给定多个正则表达式,我们能否编写一个等于它们交集的正则表达式?
例如,给定两个正则表达式 c[a-z][a-z] 和 [a-z][aeiou]t,它们的交集包含 cat 和 cut,以及可能还有其他字符串。那么我们如何编写一个正则表达式来表示它们的交集呢?
谢谢。
给定多个正则表达式,我们能否编写一个等于它们交集的正则表达式?
例如,给定两个正则表达式 c[a-z][a-z] 和 [a-z][aeiou]t,它们的交集包含 cat 和 cut,以及可能还有其他字符串。那么我们如何编写一个正则表达式来表示它们的交集呢?
谢谢。
(?=...)(?=...)
因此,
(?=[a-z][aeiou]t)(?=c[a-z][a-z])

(?=(c[a-z][a-z]))(?=([a-z][aeiou]t)) - undefined前瞻示例很容易使用,但从技术上讲不再是正则语言。然而,可以取两个正则语言的交集,其补集是正则的。
首先注意,正则表达式可以转换为和从NFA中;它们都是表示正则语言的方法。
其次,根据德摩根定理,
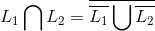
因此,以下是计算两个正则表达式交集的步骤:
一些参考资料:
^(?=regex1$)(?=regex2$),但这仅适用于匹配整个字符串,对于搜索或嵌入其他正则表达式则不适用。如果没有定位,两个lookaheads可能会匹配不同长度的字符串。这不是交集。$ 和 ^ 不允许在字符串中间进行匹配。请参见我的问题:https://dev59.com/UoDba4cB1Zd3GeqPFYYQ - Tim首先,让我们统一术语。我的语法假设是:
多个正则表达式的交集是一个正则表达式,可以匹配每个组件正则表达式也能匹配的字符串。
通用方法
要检查两个模式的交集,通用方法为(伪代码):
if match(regex1) && match(regex2) { champagne for everyone! }
正则表达式选项
在某些情况下,您可以使用前瞻来完成相同的任务,但对于复杂的正则表达式而言,这样做几乎没有任何好处,除了使您的正则表达式更加晦涩难懂。为什么没有优势呢?因为引擎仍然必须多次解析整个字符串。
布尔“与”
用于检查字符串是否完全符合regex1和regex2的AND的一般模式如下:
^(?=regex1$)(?=regex2$)
$在每个前瞻中确保每个字符串都匹配模式且没有多余内容。^(?=regex1$)(?=regex2$).*
^(?=regex1$)regex2$
|来实现:catch|cat1|cat2|cat3|cat5
此外,这样的正则表达式通常可以被压缩,例如:
cat(?:ch|[1-35])
对于 And 操作,我们在正则表达式中可以使用以下语法:
(REGEX)(REGEX)
以您的示例为例:
'Cat'.match(/^([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)$/)
["Cat", "C", "a", "t"]
'Ca'.match(/^([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)$/)
//null
'Cat123'.match(/^([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)$/)
//null
在哪里
([A-Za-z]+) //Match All characters
和
([aeiouAEIOU]+) //Match all vowels
将它们结合起来会匹配
([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)
例如:
'Hmmmmmm'.match(/^([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)$/)
//null
'Stckvrflw'.match(/^([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)$/)
null
'StackOverflow'.match(/^([A-Za-z]+)([aeiouAEIOU]+)([A-Za-z]+)$/)
["StackOverflow", "StackOverfl", "o", "w"]
=? 的意思是“匹配零次或一次等号”?这与 lookahead 无关。如果我误解了你的意图,请告诉我。 - zx81