我们使用Entity Frameworks进行数据库访问,而当我们“想到”LIKE语句时 - 它实际上生成CHARINDEX内容。因此,这里是两个简单的查询,我将它们简化以证明我们在某些服务器上的观点:
-- Runs about 2 seconds
SELECT * FROM LOCAddress WHERE Address1 LIKE '%1124%'
-- Runs about 16 seconds
SELECT * FROM LOCAddress WHERE ( CAST(CHARINDEX(LOWER(N'1124'), LOWER([Address1])) AS int)) = 1
目前,表中包含约10万条记录。Address1是一个VarChar(100)字段,没有什么特别之处。
下面是两个计划的片段并排放置。它看起来毫无意义,显示50%和50%,但执行时间却为1:8
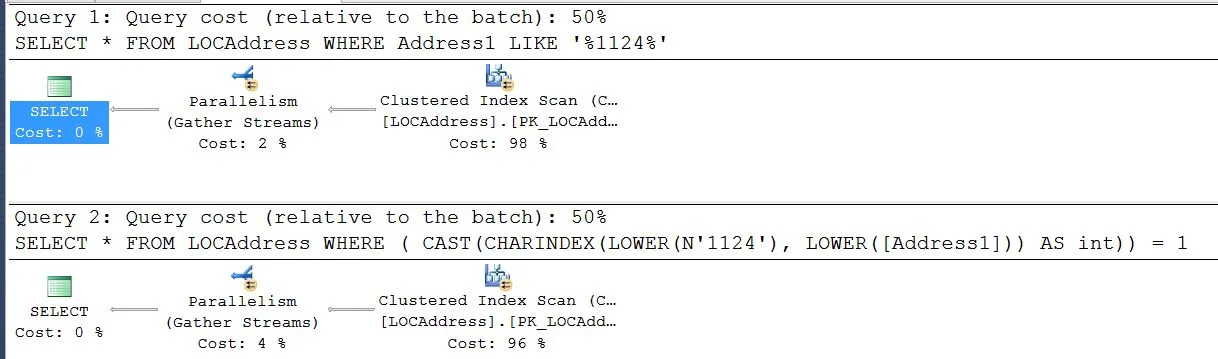
我在网上搜索了一下,一般的建议是使用CHARINDEX代替LIKE。但我们的经验恰恰相反。我的问题是,这是什么原因,并且我们如何在不改变代码的情况下解决它?
VARCHAR,并使其在实际上不是nvarchar时停止将该列解释为nvarchar... - marc_s