Kafka消费者组
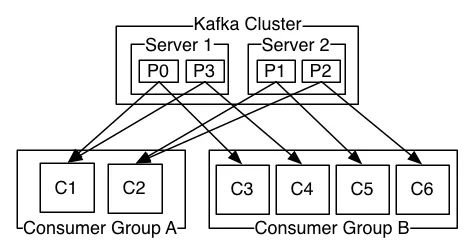
每个Kafka消费者都属于一个消费者组,可以将其视为一组消费者的逻辑容器/命名空间。消费者组可以从一个或多个主题接收消息。消费者组中的实例可以从每个主题中的零个、一个或多个分区接收消息(取决于分区数量和消费者实例数)。
「Kafka分区是如何分配给Flink工作器的?」
在Kafka中,同一消费者组中的每个消费者会被分配一个或多个分区。请注意,两个消费者不可能从同一分区消费数据。Flink消费者的数量取决于Flink并行度,也就是说,每个Flink任务(我们大致认为每个Flink任务=Flink插槽=Flink并行度=可用CPU核心)都可以作为消费者组中的单独消费者。值得注意的是,主题只是用于分组分区和数据的抽象表示,在内部只有分区根据以下方式分配给Flink的并行任务实例。
「有三种可能情况:」
1. kafka分区数==flink并行度
这种情况非常理想,因为每个消费者都处理一个分区。如果您的消息在分区之间平衡,则工作将均匀地分布在Flink操作符之间。
2. kafka分区数
当Flink任务数大于Kafka分区数时,一些Flink消费者将闲置,不读取任何数据:
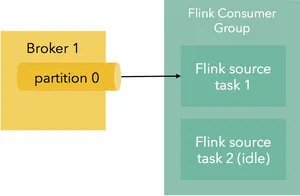
在这种情况下,如果您的并行度高于分区数(因为您想在未来的操作中使用它),您可以在Kafka源后执行
.rebalance()。这样可以确保Kafka源后的所有操作符都获得平均负载,但代价是需要重新分配数据(因此存在序列化/反序列化+网络开销)。
当Kafka分区数大于Flink任务数时,Flink消费者实例将同时订阅多个分区。
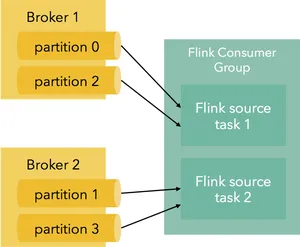
在所有情况下,Flink都会将任务最优地分配给分区。
在您的情况下,您可以使用Flink Kafka连接器创建Kafka Consumer组,并将一个或多个主题分配给它(例如使用Regex)。因此,如果Kafka有三个主题,每个主题包含10个分区,将30个槽(核心)分配给Flink作业管理器,您可以实现理想情况,这意味着每个消费者(Flink槽)将消耗一个Kafka分区。
参考资料:
1,
2,
3