关于以下基准测试,我有点惊讶于hashCode()方法的默认(本机)实现速度出乎意料地慢约50倍。
考虑一个基本的Book类,它没有覆盖hashCode()方法:
public class Book {
private int id;
private String title;
private String author;
private Double price;
public Book(int id, String title, String author, Double price) {
this.id = id;
this.title = title;
this.author = author;
this.price = price;
}
}
考虑另一种情况,一个与之前相同的Book类,名为BookWithHash,它重写了hashCode()方法,并使用了Intellij中的默认实现:
public class BookWithHash {
private int id;
private String title;
private String author;
private Double price;
public BookWithHash(int id, String title, String author, Double price) {
this.id = id;
this.title = title;
this.author = author;
this.price = price;
}
@Override
public boolean equals(final Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
final BookWithHash that = (BookWithHash) o;
if (id != that.id) return false;
if (title != null ? !title.equals(that.title) : that.title != null) return false;
if (author != null ? !author.equals(that.author) : that.author != null) return false;
return price != null ? price.equals(that.price) : that.price == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (title != null ? title.hashCode() : 0);
result = 31 * result + (author != null ? author.hashCode() : 0);
result = 31 * result + (price != null ? price.hashCode() : 0);
return result;
}
}
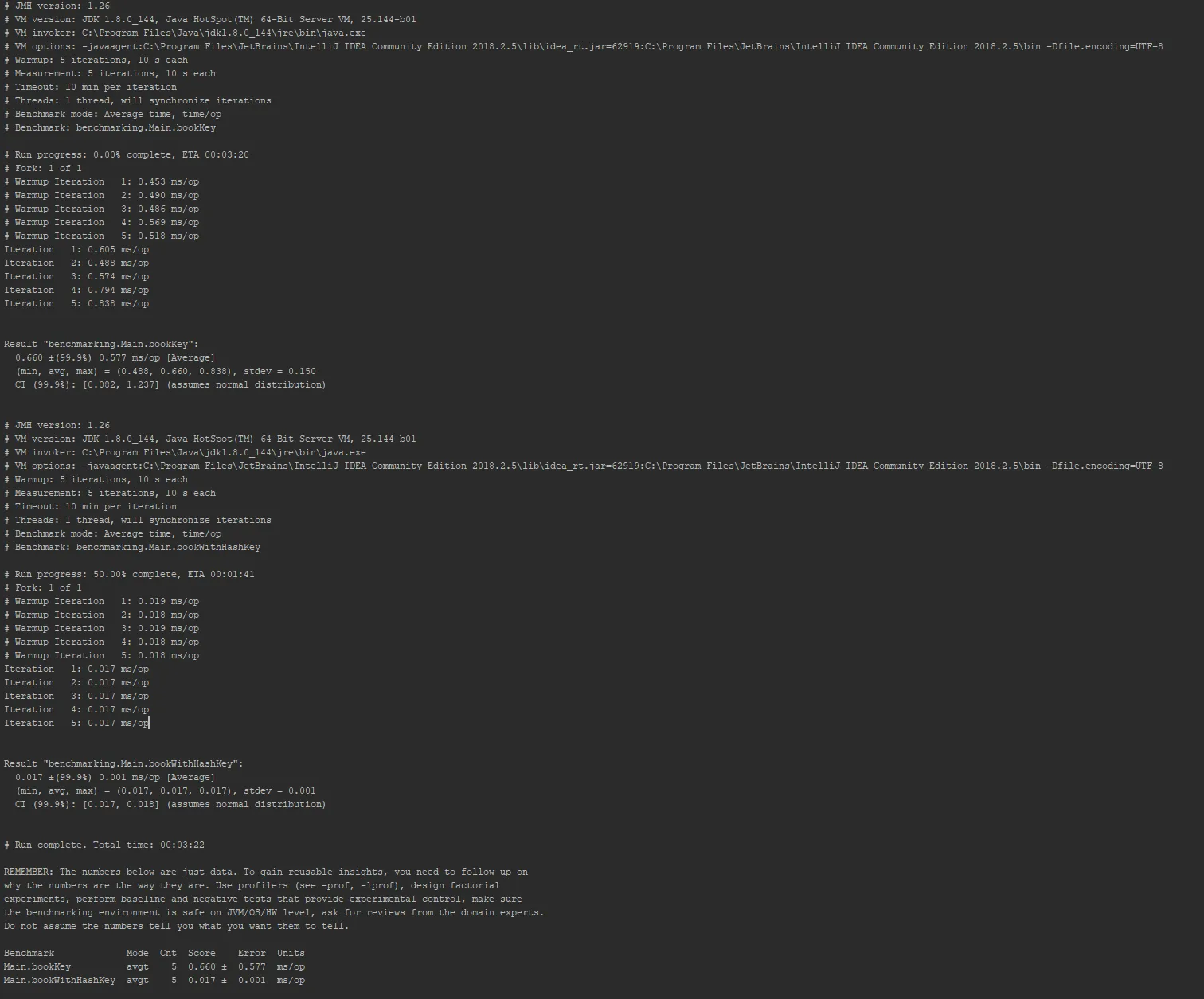
接下来,以下 JMH 基准测试的结果表明,Object 类中默认的 hashCode() 方法比 BookWithHash 类中更复杂的 hashCode() 实现要慢近50倍:
public class Main {
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder().include(Main.class.getSimpleName()).forks(1).build();
new Runner(opt).run();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public long bookWithHashKey() {
long sum = 0L;
for (int i = 0; i < 10_000; i++) {
sum += (new BookWithHash(i, "Jane Eyre", "Charlotte Bronte", 14.99)).hashCode();
}
return sum;
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public long bookKey() {
long sum = 0L;
for (int i = 0; i < 10_000; i++) {
sum += (new Book(i, "Jane Eyre", "Charlotte Bronte", 14.99)).hashCode();
}
return sum;
}
}
总结的结果表明,在BookWithHash类上调用hashCode()比在Book类上调用hashCode()快一个数量级(完整的JMH输出请见下文):
我感到惊讶的原因是,我理解默认的Object.hashCode()实现(通常)是对象初始内存地址的哈希值,这应该在微体系结构层面上非常快。这些结果似乎暗示了相对于上述简单覆盖的方法,内存位置的哈希化是Object.hashCode()的瓶颈。我很欣赏其他人对我的理解和可能导致这种令人惊讶的行为的原因的见解。
JMH完整输出:
public int hashCode() { return 0;},它们都需要大约相同的时间。 - WJS