因为某些原因,我想要扫描Java文件(例如TagMatchingInterface.java)的内容,并且通过正则表达式提取类名(TagMatchingInterface),但是我的正则表达式匹配到了错误的类名,因为注释中隐藏了一些关键字(class/interface/enum):
/**
*
* @author XXXX
* Introduction: A common interface that judges all kinds of algorithm tags.
* some other comment
*/
public class TagMatchingInterface
{
// content
public class InnerClazz{
// content
}
}
这是我的模式:
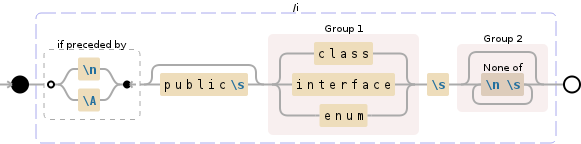
public Pattern CLASS_PATTERN = Pattern.compile("(?:public\\s)?(?:.*\\s)?(class|interface|enum)\\s+([$_a-zA-Z][$_a-zA-Z0-9]*)");
....
Matcher matcher = CLASS_PATTERN.matcher(content);
if (matcher.find()) {
System.out.println(match.group(2));
}
你对我的正则表达式有什么想法?