我正在阅读 http://www.geeksforgeeks.org/maximum-bipartite-matching/ 和 http://en.wikipedia.org/wiki/Ford%E2%80%93Fulkerson_algorithm,但是我有些困惑。看起来,这个例子的假设是每个工作只能接受一个人,并且每个人只想要一份工作。我想知道如果例如v集合的容量大于1(可以雇用多个人),u集合大于1(每个人想要多份工作)的情况下,算法/代码会如何改变?
最大二分图匹配(Ford-Fulkerson算法)
13
- senjougahara
3
2你只需要在图的左右两侧设置边缘容量>1,并像往常一样找到最大流。你的算法需要更加通用,以跟踪增广路径的瓶颈容量。你可以在维基百科上阅读有关Ford-Fulkerson算法的内容。 - Niklas B.
那么假设每个人都想要两份工作,每份工作有三个空缺,那么图形会是这样的吗?http://i.imgur.com/B0SvQjU.png - senjougahara
中间的边缘应具有容量为1,除非您想将一个人分配给同一工作多次(这取决于您的用例可能是明智的)。然后,在该图中找到最大流并检查它是否等于8(左侧容量总和)。如果不是,则无法满足每个工作的需求。 - Niklas B.
1个回答
9
为了让工作可以分配给多个人,你只需要修改从
如果一个人能够执行多个工作,则从
Jobs到Terminal的边缘容量(类似于Niklas B.在他的评论中所描述的方式,但不完全相同)。像这样:
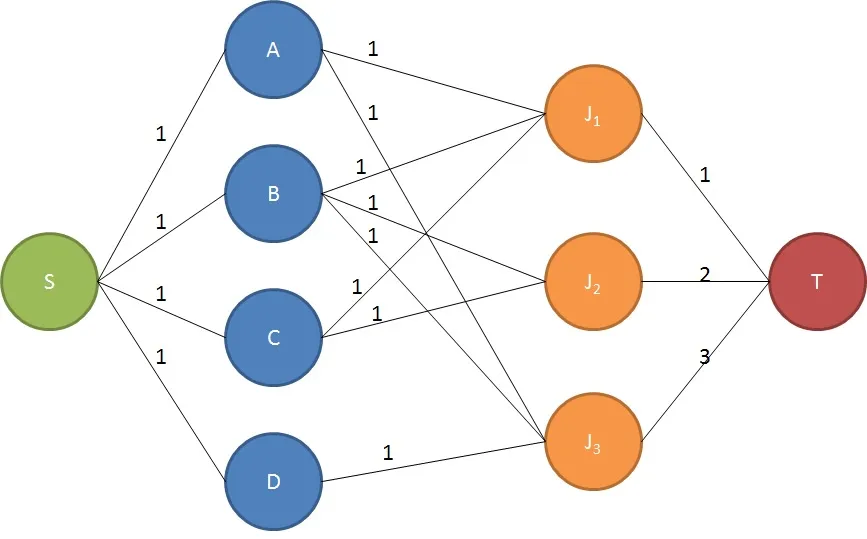
源到人员的容量为1,从人员到工作的容量也为1,这保证了一个人只会被选定一份工作(因为他们总体上能够贡献的最大流量为1)。然而,从工作到终端的容量> 1允许分配多个人到该工作。如果一个人能够执行多个工作,则从
源到人员的最大流量将增加该数量:
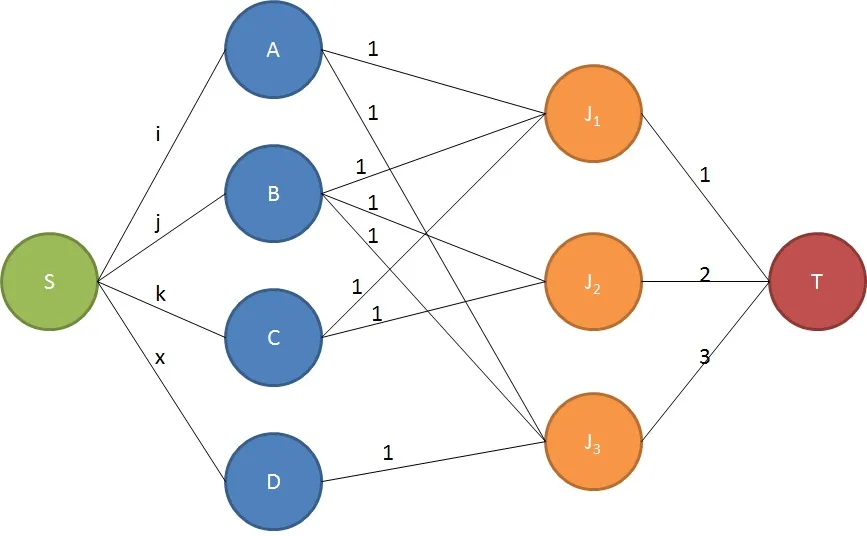
这里的i、j、k和x是整数的代表,其值应>= 1。
关键是要记住,在People左侧的流量容量决定了他们可以接受多少工作,而在Jobs右侧的流量容量则决定了可以被分配该工作的人数。中间的容量不应更改。
- AndyG
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接