我有一个大文件,实质上包含像这样的数据:
Netherlands,Noord-holland,Amsterdam,FooStreet,1,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,2,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,3,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,4,...,...
Netherlands,Noord-holland,Amsterdam,FooStreet,5,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,1,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,2,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,3,...,...
Netherlands,Noord-holland,Amsterdam,BarRoad,4,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,1,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,2,...,...
Netherlands,Noord-holland,Amstelveen,BazDrive,3,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,1,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,2,...,...
Netherlands,Zuid-holland,Rotterdam,LoremAve,3,...,...
...
这是一个多GB的文件。我有一个类来读取这个文件,并将这些行(记录)作为
IEnumerable<MyObject>暴露出来。这个MyObject有几个属性(如Country,Province,City)等。正如您所看到的,数据有很多重复。我想保持将基础数据暴露为
IEnumerable<MyObject>。但是,另一个类可能会对这些数据进行一些分层查看/结构,例如:Netherlands
Noord-holland
Amsterdam
FooStreet [1, 2, 3, 4, 5]
BarRoad [1, 2, 3, 4]
...
Amstelveen
BazDrive [1, 2, 3]
...
...
Zuid-holland
Rotterdam
LoremAve [1, 2, 3]
...
...
...
...
阅读此文件时,我基本上执行以下操作:
foreach (line in myfile) {
fields = line.split(",");
yield return new MyObject {
Country = fields[0],
Province = fields[1],
City = fields[2],
Street = fields[3],
//...other fields
};
}
现在,来到实际问题:我可以使用string.Intern()来使Country、Province、City和Street这些字符串更加紧凑(它们是主要的“罪犯”,MyObject还有其他与问题无关的属性)。
foreach (line in myfile) {
fields = line.split(",");
yield return new MyObject {
Country = string.Intern(fields[0]),
Province = string.Intern(fields[1]),
City = string.Intern(fields[2]),
Street = string.Intern(fields[3]),
//...other fields
};
}
使用 string.Intern() 可以节省大约 42% 的内存(经过测试和测量),因为所有重复的字符串都将引用同一个字符串。此外,当使用许多 LINQ 的 .ToDictionary() 方法创建分层结构时,相应字典的键(国家、省份等)将更加高效。
然而,使用 string.Intern() 的缺点之一(除了轻微的性能损失,这不是问题)是这些字符串将不再被垃圾回收。但是当我完成数据时,我确实希望所有这些东西最终被垃圾回收。
我可以使用 Dictionary<string, string> 来“内部化”这些数据,但我不喜欢在实际上只对 key 感兴趣时有一个 key 和 value 的“开销”。我可以将 value 设置为 null 或使用相同的字符串作为值(这将导致 key 和 value 中的相同引用)。虽然只需要支付几个字节的小代价,但仍然需要支付代价。
像 HashSet<string> 这样的东西对我来说更有意义。然而,我无法获取 HashSet 中字符串的引用;我可以看到 HashSet 是否包含特定字符串,但无法获取位于 HashSet 中的该特定实例的引用。我可以为此实现自己的 HashSet,但我想知道其他聪明的 StackOverflower 可能会想出什么其他解决方案。
要求:
- 我的 "FileReader" 类需要继续公开一个
IEnumerable<MyObject>。 - 我的 "FileReader" 类可能会执行一些操作(例如
string.Intern()),以优化内存使用。 MyObject类不能更改;我不会创建一个City类,Country类等,并将这些作为属性暴露给MyObject而不是简单的string属性。- 目标是通过去重大部分
Country、Province、City等中的重复字符串使代码更加内存高效;如何实现(例如字符串内部化、内部哈希集/集合/结构)并不重要。但是: - 我知道可以将数据存储在数据库中或使用其他解决方案,但我对这些解决方案不感兴趣。
- 速度只是次要问题;当然,越快越好,但在读取/迭代对象时略有性能损失也没有问题。
- 由于这是一个长期运行的过程(例如:24/7/365 运行的 windows 服务),偶尔处理这些数据,因此在完成后希望对数据进行垃圾回收;字符串内部化效果很好,但久而久之会导致大量未使用的数据的字符串池。
- 我希望任何解决方案都要“简单”;添加 15 个具有 P/Invokes 和内联装配(夸张)的类不值得一试。代码可维护性高居我的清单之首。
这更像是一个“理论”问题;我纯粹出于好奇/兴趣而问。没有“真正”的问题,但在类似情况下,我可以看到这可能成为某人的问题。
例如:我可以采取以下做法:
public class StringInterningObject
{
private HashSet<string> _items;
public StringInterningObject()
{
_items = new HashSet<string>();
}
public string Add(string value)
{
if (_items.Add(value))
return value; //New item added; return value since it wasn't in the HashSet
//MEH... this will quickly go O(n)
return _items.First(i => i.Equals(value)); //Find (and return) actual item from the HashSet and return it
}
}
但是,如果有一组大量的(需要去重的)字符串,这将很快变得混乱。我可以查看 HashSet 或字典等参考源代码,并构建一个类似的类,该类不会为
Add()方法返回布尔值,而是实际在内部/存储桶中找到的字符串。到目前为止,我能想到的最好的解决方案是:
public class StringInterningObject
{
private ConcurrentDictionary<string, string> _items;
public StringInterningObject()
{
_items = new ConcurrentDictionary<string, string>();
}
public string Add(string value)
{
return _items.AddOrUpdate(value, value, (v, i) => i);
}
}
这里的“罚款”是因为我只对Key感兴趣,但它还包括一个Value。不过仅仅几个字节,付出的代价微不足道。巧合的是,这也可以使内存使用量减少42%;与使用string.Intern()时得到的结果相同。
tolanj想到了System.Xml.NameTable:
public class StringInterningObject
{
private System.Xml.NameTable nt = new System.Xml.NameTable();
public string Add(string value)
{
return nt.Add(value);
}
}
(我已经删除了 锁定和string.Empty检查 (后者是因为NameTable 已经做到了))
xanatos 提出了一个CachingEqualityComparer:
public class StringInterningObject
{
private class CachingEqualityComparer<T> : IEqualityComparer<T> where T : class
{
public System.WeakReference X { get; private set; }
public System.WeakReference Y { get; private set; }
private readonly IEqualityComparer<T> Comparer;
public CachingEqualityComparer()
{
Comparer = EqualityComparer<T>.Default;
}
public CachingEqualityComparer(IEqualityComparer<T> comparer)
{
Comparer = comparer;
}
public bool Equals(T x, T y)
{
bool result = Comparer.Equals(x, y);
if (result)
{
X = new System.WeakReference(x);
Y = new System.WeakReference(y);
}
return result;
}
public int GetHashCode(T obj)
{
return Comparer.GetHashCode(obj);
}
public T Other(T one)
{
if (object.ReferenceEquals(one, null))
{
return null;
}
object x = X.Target;
object y = Y.Target;
if (x != null && y != null)
{
if (object.ReferenceEquals(one, x))
{
return (T)y;
}
else if (object.ReferenceEquals(one, y))
{
return (T)x;
}
}
return one;
}
}
private CachingEqualityComparer<string> _cmp;
private HashSet<string> _hs;
public StringInterningObject()
{
_cmp = new CachingEqualityComparer<string>();
_hs = new HashSet<string>(_cmp);
}
public string Add(string item)
{
if (!_hs.Add(item))
item = _cmp.Other(item);
return item;
}
}
根据Henk Holterman的要求稍作修改以适应我的“Add()接口”:
public class StringInterningObject
{
private Dictionary<string, string> _items;
public StringInterningObject()
{
_items = new Dictionary<string, string>();
}
public string Add(string value)
{
string result;
if (!_items.TryGetValue(value, out result))
{
_items.Add(value, value);
return value;
}
return result;
}
}
我在想是否有更简洁/更好/更酷的方法来“解决”我的(不是真正的)问题。现在我想已经有足够多的选择了
这里是一些我为一些简单、短暂、初步测试想出来的数字:
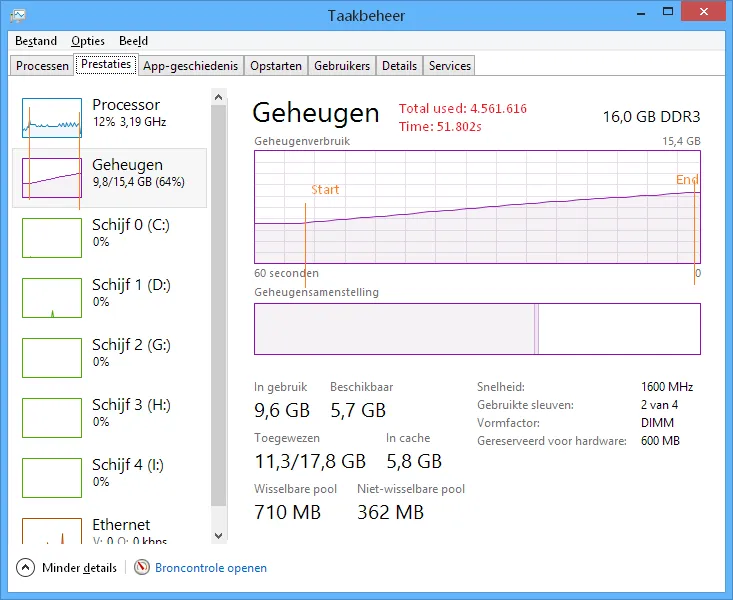
未优化
内存:约4.5GB
加载时间:约52秒
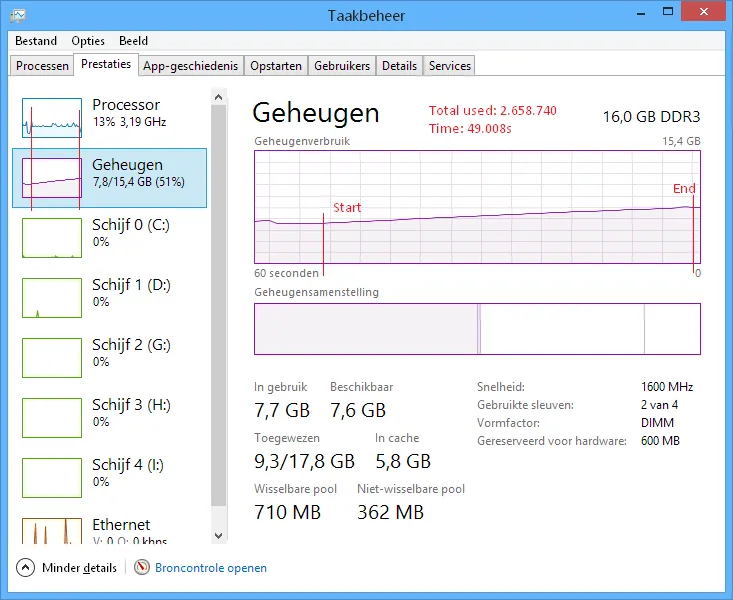
StringInterningObject(请参见上文,ConcurrentDictionary变体)
内存:约2.6GB
加载时间:约49秒
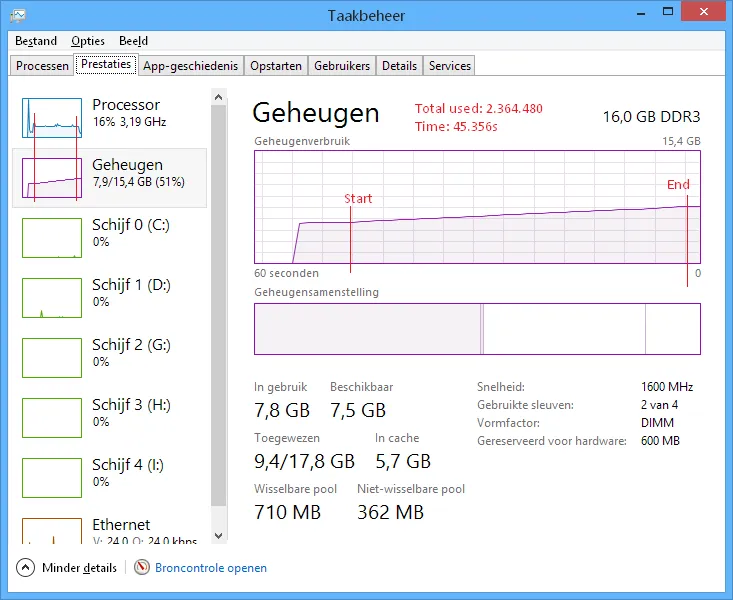
string.Intern()
内存:约2.3GB
加载时间:约45秒
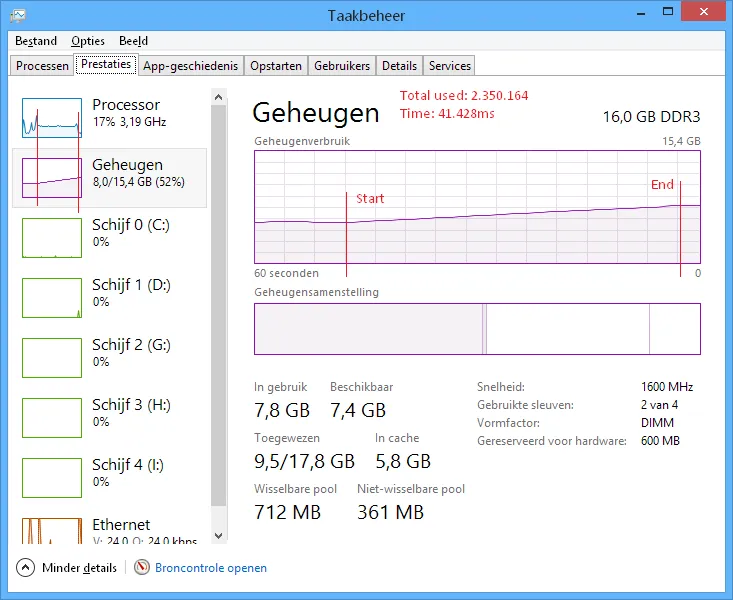
System.Xml.NameTable
内存:约2.3GB
加载时间:约41秒
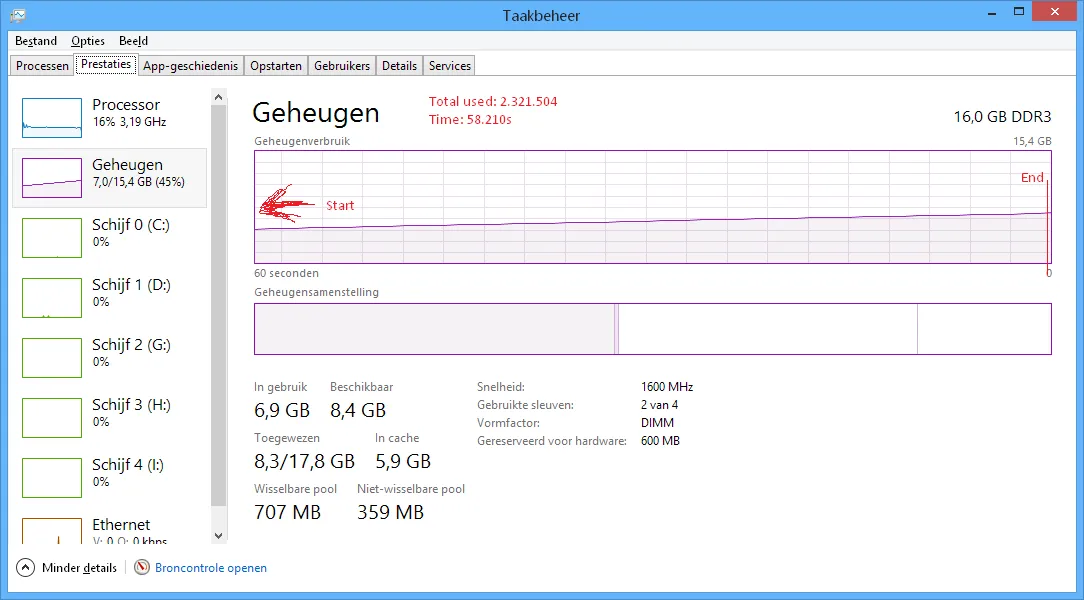
CachingEqualityComparer
内存:约2.3GB
加载时间:约58秒
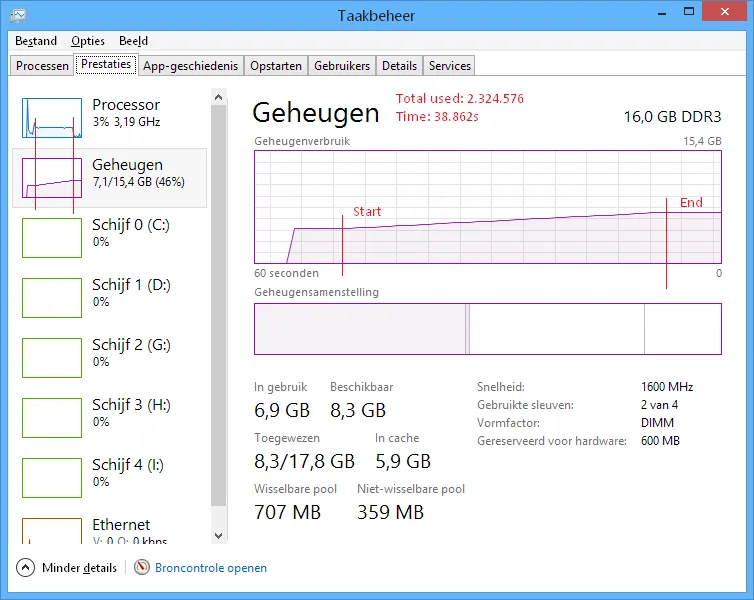
StringInterningObject(请参见上文,非并发Dictionary变体),根据Henk Holterman的请求:
内存:约2.3GB
加载时间:约39秒
虽然数字没有非常明确,但事实上使用未优化版本的许多内存分配比使用 string.Intern() 或上述的 StringInterningObjects 会导致(稍微)更长的加载时间。<<参见更新。
HashSet的替代品,在这方面会有所帮助,而我却错过了或者其他什么。或者,也许我只是在胡言乱语,想到了一些编译器指令可以帮助解决问题。 - RobIIIstring.Intern支持或不支持、是否弱引用、以每个操作成本为代价的并发性能与以不可重入为代价的更快速度)。我真的必须重新回到它并发布它。同时,编写自己的哈希集合来返回内部化的项并不困难,我会选择这样做。 - Jon Hanna