对不起,如果我的问题太愚蠢或者是重复的,但我没有找到任何解决办法。感谢任何建议或回答!
在我的ASP.NET MVC 5项目中,我从一个包含超过150万条记录的SQL Server表中获取数据。
为了防止SQL注入,我总是只使用参数化查询,并且生成存储过程。
例如,我发送给服务器的查询之一:
如果表中只有少量符合搜索条件的记录,则必须在返回结果之前检查所有150万个订单。我注意到,如果选择前1000条记录,则SQL Server会使用并行处理搜索“orders”表,并且速度更快,但无法在存储过程中使用该方法。因此,我想知道是否可以发送支持并行处理的存储过程或参数化查询,而不是像命令一样发送存储过程。编辑:我添加了执行计划,希望它有所帮助。
在我的ASP.NET MVC 5项目中,我从一个包含超过150万条记录的SQL Server表中获取数据。
为了防止SQL注入,我总是只使用参数化查询,并且生成存储过程。
例如,我发送给服务器的查询之一:
using (SqlConnection connection = new SqlConnection(connectionString))
{
SqlCommand sqlCommand = new SqlCommand("SELECT TOP 5 NAME
FROM TABLE_NAME
WHERE COLUMN_NAME LIKE @Param", connection);
sqlCommand.Parameters.AddWithValue("@Param", "someValue");
SqlDataAdapter sqlDataAdapter = new SqlDataAdapter();
sqlDataAdapter.SelectCommand = sqlCommand;
sqlDataAdapter.Fill(dataSet);
}
SQL Server Profiler中的结果:
exec sp_executesql N'SELECT TOP 5 NAME FROM TABLE_NAME WHERE COLUMN_NAME LIKE @Param',N'@Param nvarchar(11)',@Param=N'%someValue%'
如果表中只有少量符合搜索条件的记录,则必须在返回结果之前检查所有150万个订单。我注意到,如果选择前1000条记录,则SQL Server会使用并行处理搜索“orders”表,并且速度更快,但无法在存储过程中使用该方法。因此,我想知道是否可以发送支持并行处理的存储过程或参数化查询,而不是像命令一样发送存储过程。编辑:我添加了执行计划,希望它有所帮助。
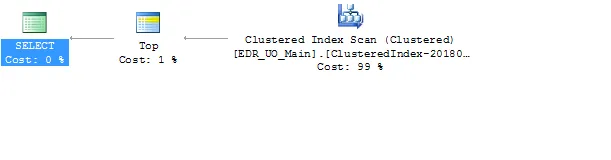
TOP(1000)机会产生并行性 - 对于其他表大小和参数,它也可能很容易再次变为顺序。 建议使用全文索引来服务这些catch-all查询。 您可以通过省略“TOP(5)”并仅使用数据阅读器读取前5行来迫使查询“最大限度地恶化”,但这会导致SQL Server以相当戏剧性的方式过度承诺资源。 这不是一种获取并行性的好策略。 - Jeroen Mostert