我有一个文本文件,其中包含不同国家的名称,如下所示:
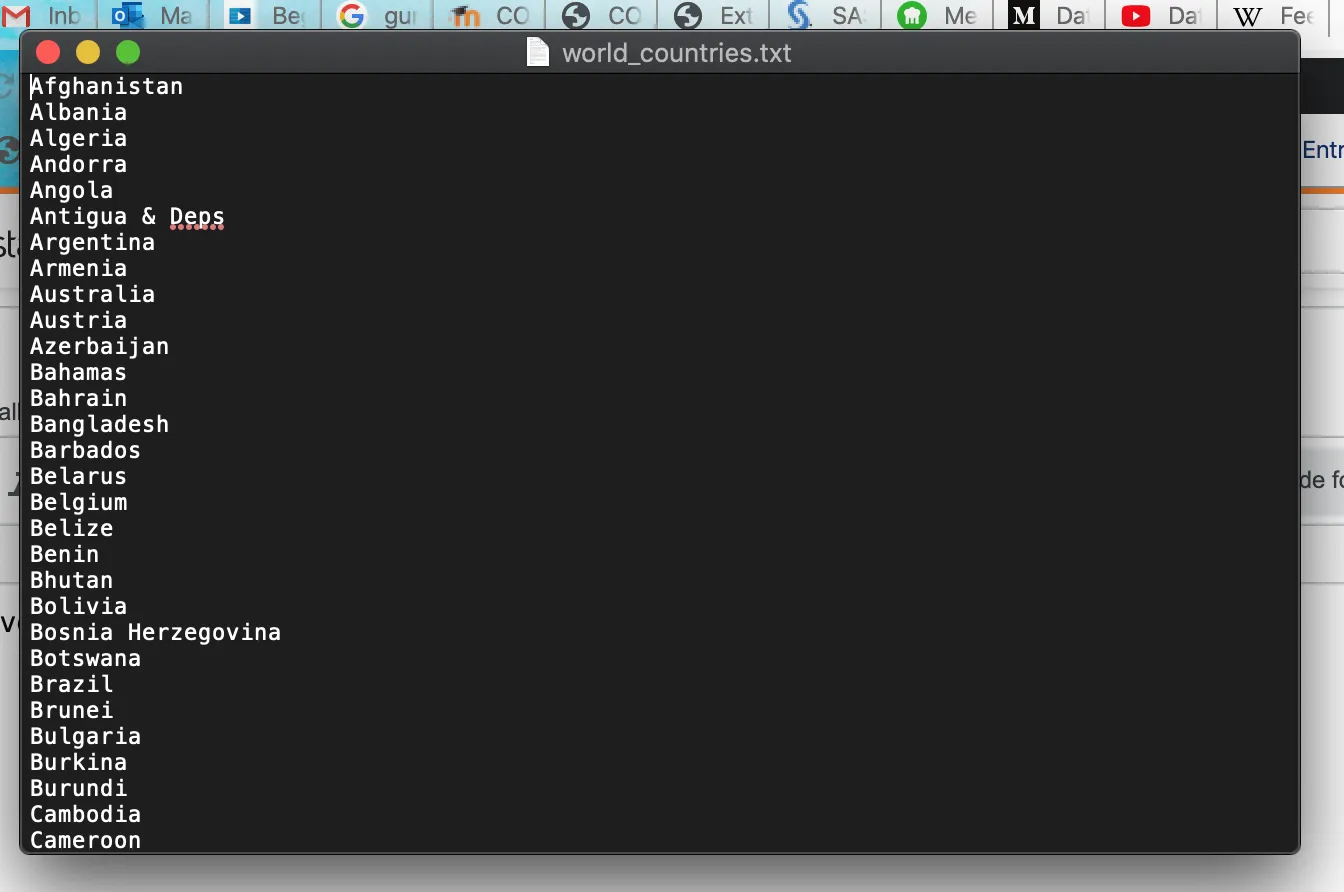
with open('a.txt') as x:
b = [word for line in x for word in line.split()]
print(b)
问题:
上面的Python代码完全可以运行,但唯一的问题是如果在任意两个单词之间发现任何空格,则按两个独立单词存储在列表中。而我想逐行检索名称并将整个单词作为单个单词存储。
例如:
我想将单词Antigua&Deps作为一个单独的单词存储在列表内。然而,它将其作为3个不同的单词存储。
请问有谁可以帮我解决这个问题吗?