我希望有一个正则表达式,能够匹配任何不正确的数学数字。以下列表是正则表达式的输入示例:
所以前三个(用粗体标记的)不应被选择,其余的应该被选择。 这与另一篇帖子非常接近,但由于它的负面性质,它是不同的。 我正在使用R,但我想任何正则表达式都可以。 以下是提到的帖子中最好的解决方案:
1
1.7654
-2.5
2-
2.
m
2..3
2....233..6
2.2.8
2--5
6-4-9
所以前三个(用粗体标记的)不应被选择,其余的应该被选择。 这与另一篇帖子非常接近,但由于它的负面性质,它是不同的。 我正在使用R,但我想任何正则表达式都可以。 以下是提到的帖子中最好的解决方案:
a <- c("1", "1.7654", "-2.5", "2-", "2.", "m", "2..3", "2....233..6", "2.2.8", "2--5", "6-4-9")
grep(pattern="(-?0[.]\\d+)|(-?[1-9]+\\d*([.]\\d+)?)|0$", x=a)
这将会输出:
\[1\] 1 2 3 4 5 7 8 9 10 11
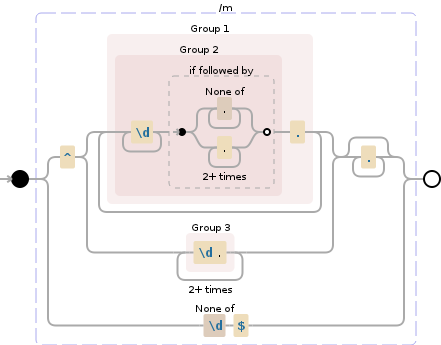
a[is.na(as.numeric(a))]相当接近,除了其中的“2.”。 - talatsuppressWarnings(a[is.na(as.numeric(a))]),灵感来自于这里。 - MichaelChirico