我正在尝试分析使用Surveymonkey创建的大型调查,该调查在CSV文件中有数百列,输出格式难以使用,因为标题跨越两行。
- 是否有人发现了一种简单的方法来管理CSV文件中的标题,使得分析变得可控?
- 其他人如何分析Surveymonkey的结果?
谢谢!
我正在尝试分析使用Surveymonkey创建的大型调查,该调查在CSV文件中有数百列,输出格式难以使用,因为标题跨越两行。
谢谢!
您可以从Surveymonkey以符合R的方便形式导出数据,详见“高级电子表格格式”中的下载回答。
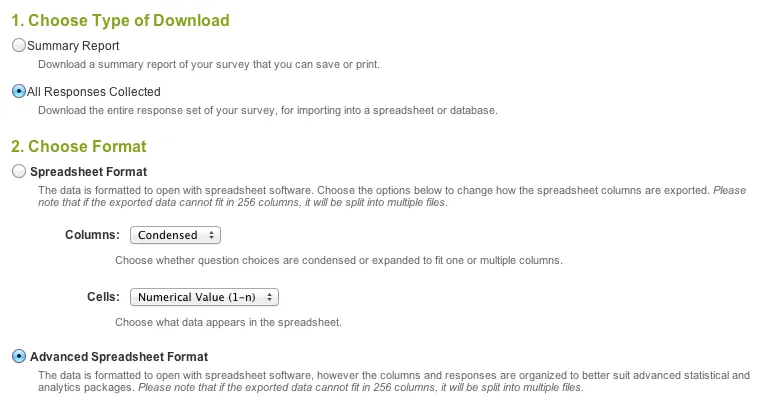
最终我所做的是使用LibreOffice打印标记为V1、V2等的标题,然后将文件读入。
m1 <- read.csv('Sheet1.csv', header=FALSE, skip=1)
然后对m1$V10、m1$V23等进行了分析...
为了避免多列数据的混乱,我使用了以下小函数:
# function to merge columns into one with a space separator and then
# remove multiple spaces
mcols <- function(df, cols) {
# e.g. mcols(df, c(14:18))
exp <- paste('df[,', cols, ']', sep='', collapse=',' )
# this creates something like...
# "df[,14],df[,15],df[,16],df[,17],df[,18]"
# now we just want to do a paste of this expression...
nexp <- paste(" paste(", exp, ", sep=' ')")
# so now nexp looks something like...
# " paste( df[,14],df[,15],df[,16],df[,17],df[,18] , sep='')"
# now we just need to parse this text... and eval() it...
newcol <- eval(parse(text=nexp))
newcol <- gsub(' *', ' ', newcol) # replace duplicate spaces by a single one
newcol <- gsub('^ *', '', newcol) # remove leading spaces
gsub(' *$', '', newcol) # remove trailing spaces
}
# mcols(df, c(14:18))
毫无疑问,有人能够整理好这个!
为了整理Likert量表,我使用了以下方法:
# function to tidy c('Strongly Agree', 'Agree', 'Disagree', 'Strongly Disagree')
tidylik4 <- function(x) {
xlevels <- c('Strongly Disagree', 'Disagree', 'Agree', 'Strongly Agree')
y <- ifelse(x == '', NA, x)
ordered(y, levels=xlevels)
}
for (i in 44:52) {
m2[,i] <- tidylik4(m2[,i])
}
随意评论,毫无疑问这将再次出现!
我经常需要处理这个问题,但是两列标头有些麻烦。这个函数解决了这个问题,让你只需要一个一行的标头。它还将多 punch 问题合并在一起,这样你就可以使用上下样式命名。
#' @param x The path to a surveymonkey csv file
fix_names <- function(x) {
rs <- read.csv(
x,
nrows = 2,
stringsAsFactors = FALSE,
header = FALSE,
check.names = FALSE,
na.strings = "",
encoding = "UTF-8"
)
rs[rs == ""] <- NA
rs[rs == "NA"] <- "Not applicable"
rs[rs == "Response"] <- NA
rs[rs == "Open-Ended Response"] <- NA
nms <- c()
for(i in 1:ncol(rs)) {
current_top <- rs[1,i]
current_bottom <- rs[2,i]
if(i + 1 < ncol(rs)) {
coming_top <- rs[1, i+1]
coming_bottom <- rs[2, i+1]
}
if(is.na(coming_top) & !is.na(current_top) & (!is.na(current_bottom) | grepl("^Other", coming_bottom)))
pre <- current_top
if((is.na(current_top) & !is.na(current_bottom)) | (!is.na(current_top) & !is.na(current_bottom)))
nms[i] <- paste0(c(pre, current_bottom), collapse = " - ")
if(!is.na(current_top) & is.na(current_bottom))
nms[i] <- current_top
}
nms
}
如果你注意到了,它只返回名称。我通常使用...,skip=2, header = FALSE读取.csv文件,并保存到变量中并覆盖变量的名称。同时设置na.strings和stringsAsFactor = FALSE也非常有帮助。
nms = fix_names("path/to/csv")
d = read.csv("path/to/csv", skip = 2, header = FALSE)
names(d) = nms
for(i in 1:ncol(df)){
newname <- colnames(df)[i]
if(nchar(newname) < 2){
colnames(df)[i] <- df[1,i]
}
df <- df[-1,]
.csv,则在 RStudio 中,重复的列名将自动替换为 X。如果导出为 .xlsx,则重复的值将是 ...。base R 的解决方案:sm_header_function <- function(x, rep_val){
orig <- x
sv <- x
sv <- sv[1,]
sv <- sv[, sapply(sv, Negate(anyNA)), drop = FALSE]
sv <- t(sv)
sv <- cbind(rownames(sv), data.frame(sv, row.names = NULL))
names(sv)[1] <- "name"
names(sv)[2] <- "value"
sv$grp <- with(sv, ave(name, FUN = function(x) cumsum(!startsWith(name, rep_val))))
sv$new_value <- with(sv, ave(name, grp, FUN = function(x) head(x, 1)))
sv$new_value <- paste0(sv$new_value, " ", sv$value)
new_names <- as.character(sv$new_value)
colnames(orig)[which(colnames(orig) %in% sv$name)] <- sv$new_value
orig <- orig[-c(1),]
return(orig)
}
sm_header_function(df, "X")
sm_header_function(df, "...")
> colnames(sample)
[1] "Respondent ID" "Please provide your contact information:" "...11"
[4] "...12" "...13" "...14"
[7] "...15" "...16" "...17"
[10] "...18" "...19" "I wish it would have snowed more this winter."
来自SurveyMonkey的清理导出:
> colnames(sample_clean)
[1] "Respondent ID" "Please provide your contact information: Name"
[3] "Please provide your contact information: Company" "Please provide your contact information: Address"
[5] "Please provide your contact information: Address 2" "Please provide your contact information: City/Town"
[7] "Please provide your contact information: State/Province" "Please provide your contact information: ZIP/Postal Code"
[9] "Please provide your contact information: Country" "Please provide your contact information: Email Address"
[11] "Please provide your contact information: Phone Number" "I wish it would have snowed more this winter. Response"
示例数据:
structure(list(`Respondent ID` = c(NA, 11385284375, 11385273621,
11385258069, 11385253194, 11385240121, 11385226951, 11385212508
), `Please provide your contact information:` = c("Name", "Benjamin Franklin",
"Mae Jemison", "Carl Sagan", "W. E. B. Du Bois", "Florence Nightingale",
"Galileo Galilei", "Albert Einstein"), ...11 = c("Company", "Poor Richard's",
"NASA", "Smithsonian", "NAACP", "Public Health Co", "NASA", "ThinkTank"
), ...12 = c("Address", NA, NA, NA, NA, NA, NA, NA), ...13 = c("Address 2",
NA, NA, NA, NA, NA, NA, NA), ...14 = c("City/Town", "Philadelphia",
"Decatur", "Washington", "Great Barrington", "Florence", "Pisa",
"Princeton"), ...15 = c("State/Province", "PA", "Alabama", "D.C.",
"MA", "IT", "IT", "NJ"), ...16 = c("ZIP/Postal Code", "19104",
"20104", "33321", "1230", "33225", "12345", "8540"), ...17 = c("Country",
NA, NA, NA, NA, NA, NA, NA), ...18 = c("Email Address", "benjamins@gmail.com",
"mjemison@nasa.gov", "stargazer@gmail.com", "dubois@web.com",
"firstnurse@aol.com", "galileo123@yahoo.com", "imthinking@gmail.com"
), ...19 = c("Phone Number", "215-555-4444", "221-134-4646",
"999-999-4422", "999-000-1234", "123-456-7899", "111-888-9944",
"215-999-8877"), `I wish it would have snowed more this winter.` = c("Response",
"Strongly disagree", "Strongly agree", "Neither agree nor disagree",
"Strongly disagree", "Disagree", "Agree", "Strongly agree")), row.names = c(NA,
-8L), class = c("tbl_df", "tbl", "data.frame"))
library(haven)
read_sav("your-file-here.sav")
haven_labelled的数值向量,这类似于因子。
我创建了一个一个函数的软件包,它使用tidyverse函数来读取和清理SM结果,这些结果以默认的奇怪格式导出。
所以,如果你想的话,你可以这样做:
devtools::install_github("church-army/monkeyreadr")
library(monkeyreadr)
read_sm("your-survey-monkey-data.csv")
read_sm() 函数default_cols <- c("Respondent ID", "Collector ID", "IP Address",
"Email Address", "First Name", "Last Name",
"Custom Data 1")
read_sm <- function(x, clean_names = TRUE, drop_surplus_cols = TRUE,
...){
## determine cleaning function from clean_names -------------------
stopifnot(length(clean_names) == 1)
if(!is.function(clean_names)){
name_cleaner <- ifelse(clean_names, janitor::make_clean_names, identity)
} else name_cleaner <- clean_names
## read sm_data ---------------------------------------------------
suppressMessages({
sm_data <- vroom::vroom(x, show_col_types = FALSE, ...)
})
missing_names <- stringr::str_detect(names(sm_data), "^\\.\\.\\.\\d+$")
sm_data <- dplyr::rename_with(sm_data, name_cleaner, everything())
## Assign correct types (where known) ----------------------------------------
default_cols <- name_cleaner(default_cols)
sm_data <-
dplyr::mutate(
sm_data,
dplyr::across(
dplyr::any_of(default_cols), as.character)
)
sm_data <-
dplyr::mutate(
sm_data,
dplyr::across(any_of(name_cleaner(c("Start Date", "End Date"))),
lubridate::mdy_hms
)
)
## Replace missing names w/ values from first row ----------------------------
first_row <- unlist(sm_data[1, ])
sm_data <- sm_data[-1, ]
repaired_names <-
name_cleaner(paste(first_row[missing_names], which(missing_names)))
old_names <- names(sm_data)[missing_names]
names(sm_data)[missing_names] <- repaired_names
if(length(repaired_names) > 0){
repaired_names_to_print <-
paste(old_names, "->", repaired_names, sep = " ")
rlang::inform(message = "Repaired names:",
class = "sm_name_repair",
body = repaired_names_to_print
)
}
## Drop surplus columns ------------------------
if(drop_surplus_cols){
all_na <- \(x) all(is.na(x))
sm_data <- dplyr::select(sm_data, -(any_of(default_cols) & where(all_na)))
}
sm_data
}
read.csv()并将header=FALSE。创建两个数组,一个包含两行标题,另一个包含调查答案。然后使用paste()将两行/句子合并在一起。最后,使用colnames()。if(!is.null(second.line)) { paste(first.line, second.line) } 怎么样? - power
readLines和n=2读取(和处理)标题,并使用skip=2, header=FALSE的read.csv仅获取数据... - Ben Bolker