我想在CPU上模拟CUDA双线性插值的行为,但我发现tex2D的返回值似乎不符合双线性公式。
我猜测将插值系数从float转换为具有8位小数位的9位定点格式[1]会导致不同的值。
根据转换公式[2, 第106行],当系数为1/2^n时,n=0,1,..., 8,转换结果与输入float相同,但我仍然(不总是)收到奇怪的值。
下面我报告一个奇怪值的例子。 在这种情况下,当id = 2 * n + 1时总是出现奇怪的值,请问有人能告诉我原因吗?
源数组:
Src[0][0] = 38;
Src[1][0] = 39;
Src[0][1] = 118;
Src[1][1] = 13;
纹理定义:
static texture<float4, 2, cudaReadModeElementType> texElnt;
texElnt.addressMode[0] = cudaAddressModeClamp;
texElnt.addressMode[1] = cudaAddressModeClamp;
texElnt.filterMode = cudaFilterModeLinear;
texElnt.normalized = false;
核函数:
static __global__ void kernel_texElnt(float* pdata, int w, int h, int c, float stride/*0.03125f*/) {
const int gx = blockIdx.x*blockDim.x + threadIdx.x;
const int gy = blockIdx.y*blockDim.y + threadIdx.y;
const int gw = gridDim.x * blockDim.x;
const int gid = gy*gw + gx;
if (gx >= w || gy >= h) {
return;
}
float2 pnt;
pnt.x = (gx)*(stride)/*1/32*/;
pnt.y = 0.0625f/*1/16*/;
float4 result = tex2D( texElnt, pnt.x + 0.5, pnt.y + 0.5f);
pdata[gid*3 + 0] = pnt.x;
pdata[gid*3 + 1] = pnt.y;
pdata[gid*3 + 2] = result.x;
}
CUDA的双线性计算结果
id pnt.x pnt.y tex2D
0 0.00000 0.0625 43.0000000
1 0.03125 0.0625 42.6171875
2 0.06250 0.0625 42.6484375
3 0.09375 0.0625 42.2656250
4 0.12500 0.0625 42.2968750
5 0.15625 0.0625 41.9140625
6 0.18750 0.0625 41.9453125
7 0.21875 0.0625 41.5625000
8 0.25000 0.0625 41.5937500
9 0.28125 0.0625 41.2109375
0 0.31250 0.0625 41.2421875
10 0.34375 0.0625 40.8593750
11 0.37500 0.0625 40.8906250
12 0.40625 0.0625 40.5078125
13 0.43750 0.0625 40.5390625
14 0.46875 0.0625 40.1562500
15 0.50000 0.0625 40.1875000
16 0.53125 0.0625 39.8046875
17 0.56250 0.0625 39.8359375
18 0.59375 0.0625 39.4531250
19 0.62500 0.0625 39.4843750
20 0.65625 0.0625 39.1015625
21 0.68750 0.0625 39.1328125
22 0.71875 0.0625 38.7500000
23 0.75000 0.0625 38.7812500
24 0.78125 0.0625 38.3984375
25 0.81250 0.0625 38.4296875
26 0.84375 0.0625 38.0468750
27 0.87500 0.0625 38.0781250
28 0.90625 0.0625 37.6953125
29 0.93750 0.0625 37.7265625
30 0.96875 0.0625 37.3437500
31 1.00000 0.0625 37.3750000
CPU结果:
// convert coefficient ((1-α)*(1-β)), (α*(1-β)), ((1-α)*β), (α*β) to fixed point format
id pnt.x pnt.y tex2D
0 0.00000 0.0625 43.00000000
1 0.03125 0.0625 43.23046875
2 0.06250 0.0625 42.64843750
3 0.09375 0.0625 42.87890625
4 0.12500 0.0625 42.29687500
5 0.15625 0.0625 42.52734375
6 0.18750 0.0625 41.94531250
7 0.21875 0.0625 42.17578125
8 0.25000 0.0625 41.59375000
9 0.28125 0.0625 41.82421875
0 0.31250 0.0625 41.24218750
10 0.34375 0.0625 41.47265625
11 0.37500 0.0625 40.89062500
12 0.40625 0.0625 41.12109375
13 0.43750 0.0625 40.53906250
14 0.46875 0.0625 40.76953125
15 0.50000 0.0625 40.18750000
16 0.53125 0.0625 40.41796875
17 0.56250 0.0625 39.83593750
18 0.59375 0.0625 40.06640625
19 0.62500 0.0625 39.48437500
20 0.65625 0.0625 39.71484375
21 0.68750 0.0625 39.13281250
22 0.71875 0.0625 39.36328125
23 0.75000 0.0625 38.78125000
24 0.78125 0.0625 39.01171875
25 0.81250 0.0625 38.42968750
26 0.84375 0.0625 38.66015625
27 0.87500 0.0625 38.07812500
28 0.90625 0.0625 38.30859375
29 0.93750 0.0625 37.72656250
30 0.96875 0.0625 37.95703125
31 1.00000 0.0625 37.37500000
我在我的 GitHub [3]上放置了一份简单代码。运行程序后,您将在D:\目录下找到两个文件。
编辑于2014/01/20
我使用不同的增量运行了该程序,并发现tex2D的规格为"当alpha乘以beta小于0.00390625时,tex2D的返回值与双线性插值公式不匹配"
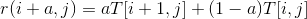
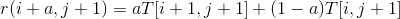
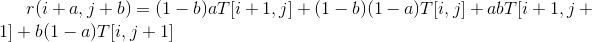
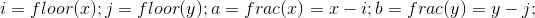
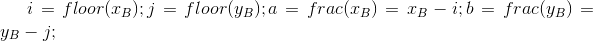 其中
其中