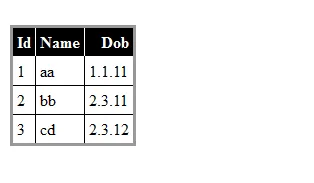
我有一个DataTable,看起来像这样:
ID Name DateBirth
.......................
1 aa 1.1.11
2 bb 2.3.11
2 cc 1.2.12
3 cd 2.3.12
哪种方法最快地删除具有相同ID的行,以获得如下结果(保留第一次出现,删除其余行):
ID Name DateBirth
.......................
1 aa 1.1.11
2 bb 2.3.11
3 cd 2.3.12
我不想对表格行进行两次处理,因为行数很大。 如果可能的话,我想使用一些LinQ,但我想这可能会是一个巨大的查询,我必须使用比较器。