有人能解释一下如何使用Count Sketch算法吗?例如,我仍然弄不清楚哈希函数是如何使用的。我很难理解这篇论文。
2个回答
55
这个流式算法实现了以下框架。
找到一个随机的流式算法,其输出(作为随机变量)具有所需的期望值但通常具有高方差(即噪声)。
为了减少方差/噪声,同时运行许多独立副本并结合它们的输出。
通常,第1步比第2步更有趣。这种算法的第2步实际上有点非标准,但我只想谈论第1步。
假设我们正在处理输入
a b c a b a .
使用三个计数器,就不需要哈希了。
a: 3, b: 2, c: 1
假设我们仅有一个函数。有八种可能的函数 h : {a, b, c} -> {+1, -1}。下面是结果表格。
h |
abc | X = counter
----+--------------
+++ | +3 +2 +1 = 6
++- | +3 +2 -1 = 4
+-- | +3 -2 -1 = 0
+-+ | +3 -2 +1 = 2
--+ | -3 -2 +1 = -4
--- | -3 -2 -1 = -6
-+- | -3 +2 -1 = -2
-++ | -3 +2 +1 = 0
现在我们可以计算期望值
(6 + 4 + 0 + 2) - (-4 + -6 + -2 + 0)
E[h(a) X] = ------------------------------------ = 24/8 = 3
8
(6 + 4 + -2 + 0) - (0 + 2 + -4 + -6)
E[h(b) X] = ------------------------------------ = 16/8 = 2
8
(6 + 2 + -4 + 0) - (4 + 0 + -6 + -2)
E[h(c) X] = ------------------------------------ = 8/8 = 1 .
8
这里发生了什么?对于a,我们可以将X = Y + Z分解,其中Y是a的和的变化量,Z是非a的和。根据期望的线性性,我们有
E[h(a) X] = E[h(a) Y] + E[h(a) Z] .
E[h(a) Y] 是一个求和式,其中每个出现 a 且满足 h(a)^2 = 1 的术语都会被计算进去,因此 E[h(a) Y] 就是 a 出现的次数。另一个术语 E[h(a) Z] 等于零;即使已知 h(a),每个其他哈希值也有相等的可能性成为正号或负号,因此在期望意义下对总和没有贡献。
实际上,哈希函数不需要是均匀随机的,这是件好事情:否则将无法存储它。哈希函数只需要成对独立(任意两个特定的哈希值是独立的)就足够了。对于我们的简单示例,随机选择以下四个函数中的任意一个即可。
abc
+++
+--
-+-
--+
新的计算留给你来处理。
- insomniac
5
34
Count Sketch是一种概率数据结构,可以回答以下问题:
读取一个元素流a1,a2,a3,...,an,其中可能有许多重复的元素,您可以随时回答以下问题:到目前为止,您已经看到了多少个ai元素?
你可以通过维护从
ai到迄今为止看到的元素计数的映射,在任何时候都可以清楚地得到准确的答案。记录新观察结果的成本为O(1),检查给定元素的观察计数的成本也为O(1)。但是,存储这个映射需要O(n)的空间,其中n是不同元素的数量。
如何使用 Count Sketch 帮助您?与所有概率数据结构一样,您需要用空间来换取准确性。Count Sketch 允许您选择两个参数:结果的准确度 (ε) 和错误估计的概率 (δ)。
为此,您需要选择一组
d 成对独立哈希函数。这些复杂的词意味着它们不会太经常发生碰撞(实际上,如果两个哈希将值映射到空间 [0,m],则碰撞的概率大约是 1/m^2)。每个哈希函数将值映射到一个空间 [0,w],因此您需要创建一个 d * w 矩阵。当您读取元素时,您需要计算该元素的每个d哈希值,并更新草图中相应的值。这部分对于 Count Sketch 和 Count-min Sketch 都是相同的。
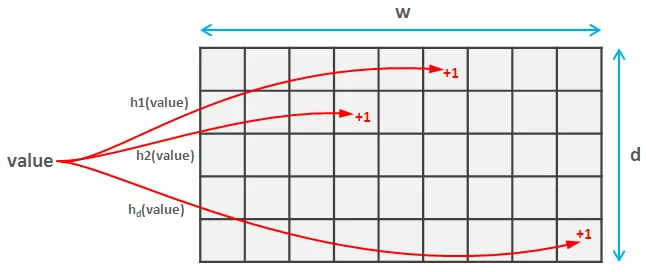
增加哈希函数的范围可以提高结果的准确性,而增加哈希数量则降低了错误估计的概率:ε = e/w 和 δ=1/e^d。另一个有趣的事情是,该值总是被高估的(如果您找到了该值,则它很可能比实际值大,但肯定不会更小)。
- Salvador Dali
1
1所以,Count-Sketch和Min-Count-Sketch算法都解决了同样的问题,但它们的实现方式略有不同? - Angelo
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 12 解释算法背后的数学原理
- 4 领导者聚类算法解释
- 7 A*(A星)算法解释
- 9 LZ4压缩算法解释
- 4 极小化极大算法解释
- 3 编辑距离算法解释
- 15 中位数算法的解释
- 4 迭代加深A*算法解释
- 28 快速选择算法 - 简化解释
- 19 卡登算法解释
1 <= y <= u,则P[h(x)=y]=1/u。问题在于相互独立性,即P[h(x_1) = y_1 and ... and h(x_n) = y_n] = P[h(x_1) = y_1]...P[h(x_n) = y_n],正如你所说,这需要n log u位的内存!幸运的是,正如你所说,对于计数草图,我们可以少用得多(四个独立性)。 - Thomas Ahle