我正在尝试基于像素值将灰度图像分离:假设将像素从0到60放在一个箱子里,60-120放在另一个箱子里,120-180...以此类推直到255。 在这种情况下,范围大致等间距。
然而,使用K-means聚类是否可以获得更真实的像素值范围? 尝试将相似的像素放在一起,不浪费低浓度像素存在的箱子。
编辑(包括获得的结果):
 K-means聚类,聚类数= 5
K-means聚类,聚类数= 5
编辑(包括获得的结果):
K-means聚类,聚类数= 5
K-means聚类,聚类数= 5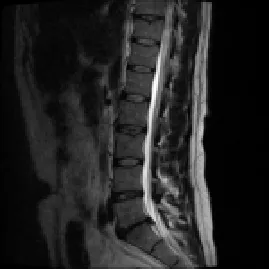
让我们来看看在8位表示图像时有多少个灰度级:
ac = ImageData[ImageTake[i, All, All], "Byte"];
First@Dimensions@Tally@Flatten@ac
-> 234
好的。让我们降低这234个级别。我们的第一次尝试将是让算法独立决定默认配置下有多少个聚类:
ic = ClusteringComponents[Image@ac];
First@Dimensions@Tally@Flatten@ic
-> 3
它选择了3个聚类,相应的图像为:
ic2 = ClusteringComponents[Image@ac, 6];
Image@ic2 // ImageAdjust
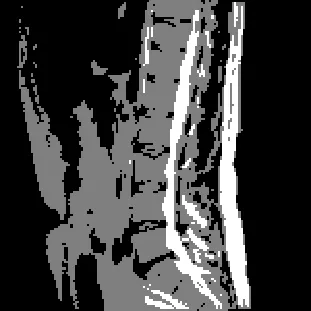
结果:
以下是每个箱子中使用的像素范围:
Table[{Min@#, Max@#} &@(Take[orig, {#[[1]]}, {#[[2]]}] & /@
Position[clus, n]), {n, 1, 6}]
-> {{0, 11}, {12, 30}, {31, 52}, {53, 85}, {86, 134}, {135, 241}}
每个箱子中的像素数量:
Table[Count[Flatten@clus, i], {i, 6}]
-> {8906, 4400, 4261, 2850, 1363, 720}
所以,答案是肯定的,并且很简单。
编辑
也许这可以帮助你理解在新示例中你做错了什么。
如果我对你的彩色图像进行聚类,并使用聚类编号来表示亮度,我得到:

