我有一个数据集,其中某些实例在给定的位置、相同日期和时间时值不同。我正在尝试创建一个子集数据框来显示这些实例。以下是我的示例:
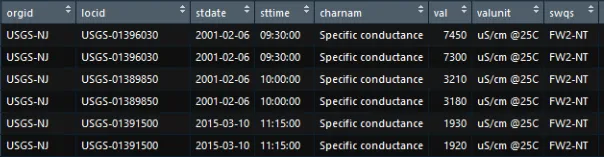 我查看了SO上类似的问题,但似乎无法得到我想要的结果。我一直得到这种情况下不是这种情况的实例。
我查看了SO上类似的问题,但似乎无法得到我想要的结果。我一直得到这种情况下不是这种情况的实例。
以下是我使用的代码:
我查看了SO上类似的问题,但似乎无法得到我想要的结果。我一直得到这种情况下不是这种情况的实例。以下是我使用的代码:
dat1<-data_concern_join2%>%
group_by(locid,stdate,sttime,charnam,valunit)%>%
filter(n()>1)
示例数据:
structure(list(orgid = c("USGS-NJ", "USGS-NJ", "USGS-NJ", "USGS-NJ",
"USGS-NJ", "USGS-NJ", "USGS-NJ", "USGS-NJ", "USGS-NJ", "USGS-NJ",
"USGS-NJ", "USGS-NJ", "USGS-NJ", "USGS-NJ", "USGS-NJ"), locid = c("USGS-01396030",
"USGS-01396030", "USGS-01389850", "USGS-01389850", "USGS-01391500",
"USGS-01391500", "USGS-01391500", "USGS-01391500", "USGS-01393960",
"USGS-01390610", "USGS-01391500", "USGS-01390610", "USGS-01391500",
"USGS-01378760", "USGS-01378760"), stdate = structure(c(11359,
11359, 11359, 11359, 16504, 16504, 16112, 16112, 11367, 13860,
12401, 13860, 16325, 13006, 13006), class = "Date"), sttime = structure(c(34200,
34200, 36000, 36000, 40500, 40500, 39600, 39600, 36000, 39600,
32400, 39600, 38400, 36900, 36900), class = c("hms", "difftime"
), units = "secs"), charnam = c("Specific conductance", "Specific conductance",
"Specific conductance", "Specific conductance", "Specific conductance",
"Specific conductance", "Specific conductance", "Specific conductance",
"Specific conductance", "Specific conductance", "Specific conductance",
"Specific conductance", "Specific conductance", "Specific conductance",
"Specific conductance"), val = c(7450, 7300, 3210, 3180, 1930,
1920, 1740, 1650, 1480, 1390, 1380, 1330, 1300, 1280, 1270),
valunit = c("uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C",
"uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C",
"uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C",
"uS/cm @25C"), swqs = c("FW2-NT", "FW2-NT", "FW2-NT", "FW2-NT",
"FW2-NT", "FW2-NT", "FW2-NT", "FW2-NT", "FW2-NT", "FW2-NT",
"FW2-NT", "FW2-NT", "FW2-NT", "FW2-NT", "FW2-NT"), WMA = c(7L,
7L, 4L, 4L, 4L, 4L, 4L, 4L, 7L, 4L, 4L, 4L, 4L, 6L, 6L),
year = c(2001L, 2001L, 2001L, 2001L, 2015L, 2015L, 2014L,
2014L, 2001L, 2007L, 2003L, 2007L, 2014L, 2005L, 2005L),
HUC14 = c("HUC02030104050090", "HUC02030104050090", "HUC02030103120050",
"HUC02030103120050", "HUC02030103140070", "HUC02030103140070",
"HUC02030103140070", "HUC02030103140070", "HUC02030104050010",
"HUC02030103140010", "HUC02030103140070", "HUC02030103140010",
"HUC02030103140070", "HUC02030103010040", "HUC02030103010040"
)), .Names = c("orgid", "locid", "stdate", "sttime", "charnam",
"val", "valunit", "swqs", "WMA", "year", "HUC14"), row.names = c(NA,
-15L), class = c("grouped_df", "tbl_df", "tbl", "data.frame"), vars = c("locid",
"stdate", "sttime", "charnam", "valunit"), drop = TRUE, indices = list(
13:14, 2:3, c(9L, 11L), 10L, 6:7, 12L, 4:5, 8L, 0:1), group_sizes = c(2L,
2L, 2L, 1L, 2L, 1L, 2L, 1L, 2L), biggest_group_size = 2L, labels = structure(list(
locid = c("USGS-01378760", "USGS-01389850", "USGS-01390610",
"USGS-01391500", "USGS-01391500", "USGS-01391500", "USGS-01391500",
"USGS-01393960", "USGS-01396030"), stdate = structure(c(13006,
11359, 13860, 12401, 16112, 16325, 16504, 11367, 11359), class = "Date"),
sttime = structure(c(36900, 36000, 39600, 32400, 39600, 38400,
40500, 36000, 34200), class = c("hms", "difftime"), units = "secs"),
charnam = c("Specific conductance", "Specific conductance",
"Specific conductance", "Specific conductance", "Specific conductance",
"Specific conductance", "Specific conductance", "Specific conductance",
"Specific conductance"), valunit = c("uS/cm @25C", "uS/cm @25C",
"uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C", "uS/cm @25C",
"uS/cm @25C", "uS/cm @25C")), row.names = c(NA, -9L), class = "data.frame", vars = c("locid",
"stdate", "sttime", "charnam", "valunit"), drop = TRUE, .Names = c("locid",
"stdate", "sttime", "charnam", "valunit")))
filter(n() > 1)根据分组变量获取重复的行。如果不是这种情况,那么就有些问题了。 - akrundata_concern_join2%>% group_by(locid,stdate,sttime,charnam,valunit)%>% filter(n_distinct(val)== n())。 - akrun