我一直在阅读关于C++ STL容器的书籍,尤其是关于STL及其容器的部分。现在我已经理解了它们每个具有自己特定的属性,并且我快要记住它们所有的内容……但我还没有完全理解在哪种情况下使用每个容器。
可以用示例代码来说明吗?
我一直在阅读关于C++ STL容器的书籍,尤其是关于STL及其容器的部分。现在我已经理解了它们每个具有自己特定的属性,并且我快要记住它们所有的内容……但我还没有完全理解在哪种情况下使用每个容器。
可以用示例代码来说明吗?
unordered_map和unordered_set(以及它们的多重变体),它们不在流程图中,但当您不关心顺序但需要按键查找元素时,它们是不错的选择。 它们的查找通常是O(1),而不是O(log n)。 - Aidiakapi这里是我根据 David Moore 版本(参见上文)创作的流程图,它基本符合新标准(C++11)。这仅仅是我的个人看法,不具争议性,但我认为它可能对这个讨论有价值:
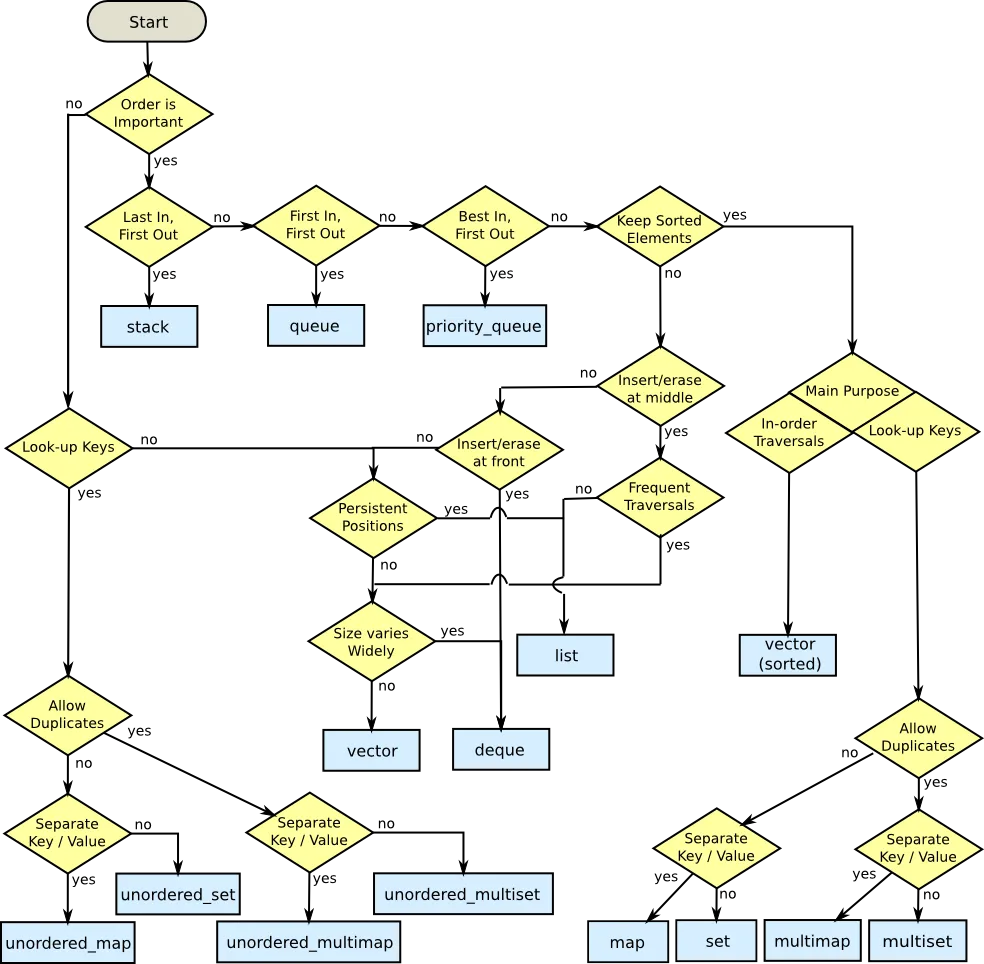
std::vector。更重要的是,如果有序迭代是集合的标准行为,我不明白为什么不能使用std::set进行有序迭代。当然,如果答案谈到通过[]有序访问容器的值,那么你只能使用已排序的std::vector。但无论哪种情况,决策都应该在“需要顺序”问题之后做出。 - RAsstd::vector。std::vector在这里表现不佳”,那么就基于X去选择其他方法。std::remove_if 函数几乎总是优于“迭代期间删除”的方法。 - fredoverflow看看Scott Meyers的Effective STL,它很好地解释了如何使用STL。
如果你想存储一定数量或不确定数量的对象并且不会删除任何一个,那么vector就是你想要的。它是C数组的默认替代品,并且像数组一样工作,但不会溢出。你也可以用reserve()预先设置它的大小。
如果你想存储不确定数量的对象,并且你将添加和删除它们,那么你可能需要一个list...因为你可以删除元素而不移动任何后续元素-不像vector。但它占用的内存比vector多,而且不能顺序访问元素。
如果你想取一堆元素,并只找到这些元素的唯一值,全部读入set中就可以,而且它还会为你排序。
如果你有很多键值对,并且想按键排序,那么map很有用...但它每个键只能持有一个值。如果你需要每个键持有多个值,你可以在map中使用vector/list作为值,或者使用multimap。
虽然不在STL中,但它在STL的TR1更新中:如果你有很多键值对,将通过键进行查找,并且不关心它们的顺序,你可能想使用哈希 - 这是tr1::unordered_map。我在Visual C++ 7.1中使用过它,当时它被称为stdext::hash_map。它的查找时间复杂度是O(1),而不是map的O(log n)。
hash_map实现并不是很好。我希望他们在unordered_map上做得更好。 - Mark Ransomlist所做的。那里有一个相当明显的错误。 - underscore_d流程图: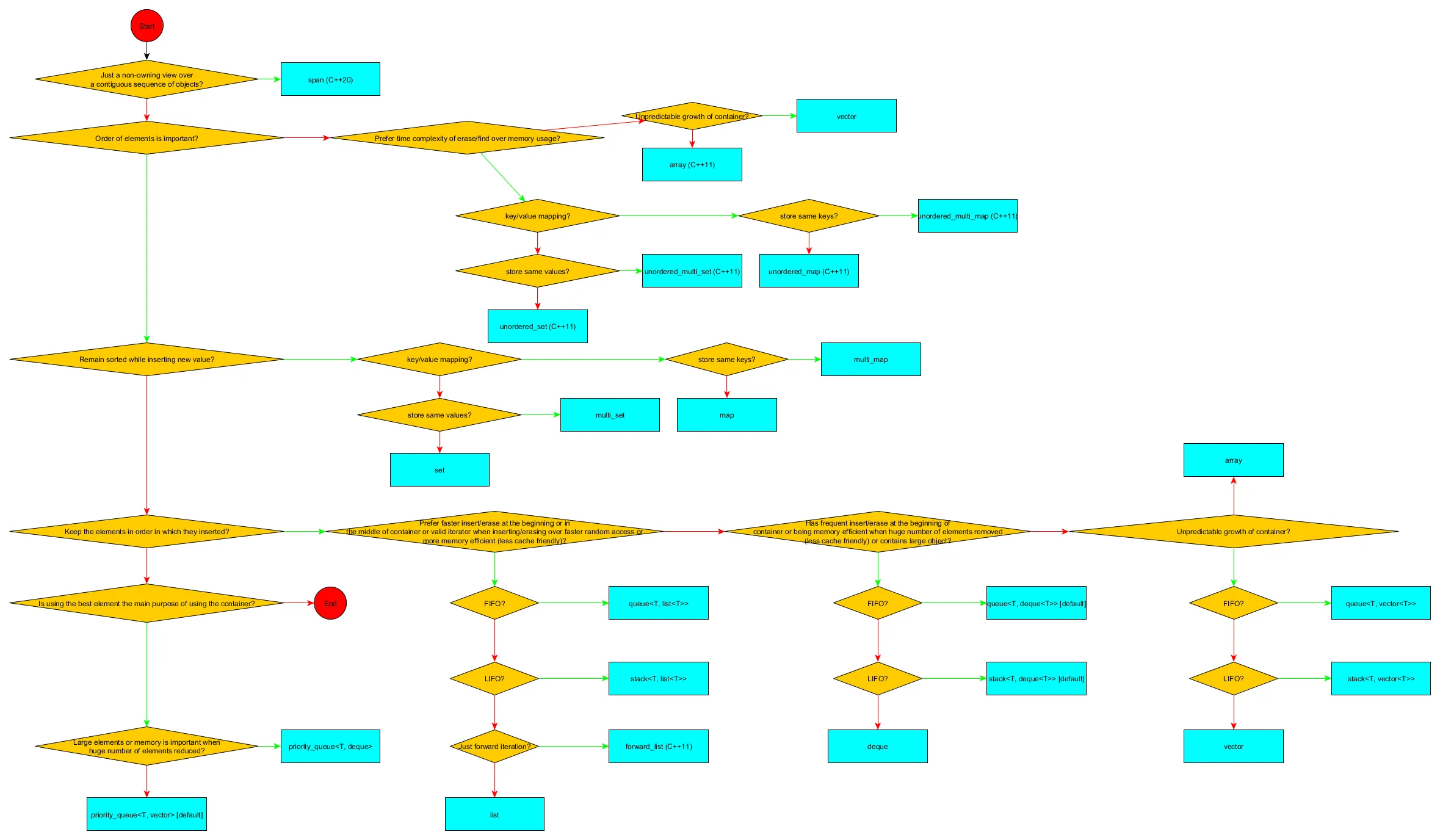
更多信息见此链接。
std::array应该改为std::unique_ptr<T[]>。简单概述:vector大小可变,unique_ptr<T[]>在创建时确定大小,而array需要其大小为编译时常量。 - Ben Voigtvector:紧凑的布局,每个包含对象很少或没有内存开销。迭代效率高。附加、插入和删除可能很昂贵,特别是对于复杂对象。通过索引查找包含对象很便宜,例如 myVector[10]。在C中使用数组的地方也适用。适用于有大量简单对象(例如 int)的情况。在添加许多对象到容器之前不要忘记使用 reserve()。list:每个包含对象的内存开销较小。迭代效率高。附加、插入和删除很便宜。在C中使用链表的地方也适用。set(和 multiset):每个包含对象的内存开销很大。用于需要快速查找该容器是否包含给定对象或有效合并容器的情况。map(和 multimap):每个包含对象的内存开销很大。用于存储键值对并快速按键查找值的情况。
zdan提供的速查表上的流程图提供了更详尽的指南。
在评论中,用户@NathanOliver还提供了另一个好的博客,其中有更具体的测量数据。https://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html。是的,我的建议是默认使用 std::vector
我学到的一课是:尽量将它包装成一个类,因为某一天改变容器类型可能会带来很大的惊喜。
class CollectionOfFoo {
Collection<Foo*> foos;
.. delegate methods specifically
}
这不需要很多前期成本,当您想要在此结构上的某些操作时进行断点调试时,可以节省时间。
选择完美的数据结构:
每种数据结构都提供一些操作,其时间复杂度可能会有所不同:
O(1), O(lg N), O(N)等。
您需要猜测哪些操作最常用,并使用具有O(1)操作的数据结构。
简单吧 (-:
auto myIterator = whateverCollection.begin(); // <-- 不受容器类型更改的影响 - Blacktypedef Collection<Foo*> CollectionOfFoo;够用吗? - Craig McQueen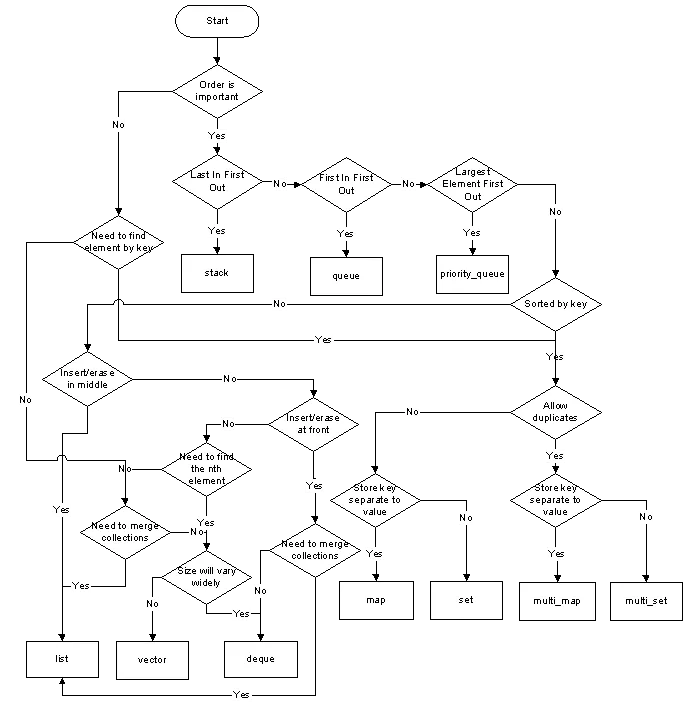
{kind=link}