我正在尝试理解multiprocessing相比threading的优势。我知道multiprocessing可以绕过全局解释器锁,但除此之外还有哪些优势?threading不能做同样的事情吗?
多进程与多线程Python的区别
1024
- John
7
9我认为这篇文章很有用:http://blogs.datalogics.com/2013/09/25/threads-vs-processes-for-program-parallelization/ 虽然根据语言的不同可能会出现有趣的情况。例如,根据Andrew Sledge的链接,Python线程速度较慢。但在Java中情况恰好相反,Java进程比线程慢得多,因为启动新进程需要一个新的JVM。 - inf3rno
7前两个回答(当前排名第一的回答和第二个回答)都没有涉及GIL的重要方面。这里有一个回答涵盖了GIL方面:https://dev59.com/UGMl5IYBdhLWcg3wzpnV#18114882。 - Trevor Boyd Smith
@AndrasDeak,我们能否按照此链接所述的方式关闭问题:https://meta.stackoverflow.com/questions/251938/should-i-flag-a-question-as-duplicate-if-it-has-received-better-answers,因为该问题拥有更多赞和答案? - Ciro Santilli OurBigBook.com
3@CiroSantilli 我选择这个方向的原因是因为这个问题的答案很糟糕。被接受的答案没有什么实质性内容,在Python的上下文中是不可接受的。得票最高的答案更好,但仍然缺乏适当的解释。重复的被接受的答案来自标签中最好的贡献者之一(也是教师),实际上解释了“GIL限制”是什么以及为什么要使用它们。我更喜欢在这个方向上保留重复。我想我们在Python聊天中讨论过这个问题,但如果你愿意,我可以在那里征求意见。 - Andras Deak -- Слава Україні
2@CiroSantilli 哦,我错过了你在这里的回答!当我说“答案[...]很糟糕”时,我当然不包括现在的公司;) 我认为在那里有你的答案会更好! - Andras Deak -- Слава Україні
显示剩余2条评论
12个回答
976
以下是我总结的一些优缺点。
多进程
优点
- 独立的内存空间
- 代码通常很简单
- 利用多个CPU和核心
- 避免了cPython的GIL限制
- 除非使用共享内存(而不是同步原语),否则消除了大多数对同步原语的需求(相反,它更像是IPC的通信模型)
- 子进程可中断/可杀死
- Python
multiprocessing模块包含有用的抽象,接口类似于threading.Thread - cPython中进行CPU密集型处理时必须使用
缺点
- IPC 更复杂,有更多的开销(通信模型 vs. 共享内存/对象)
- 占用更多的内存
线程
优点
- 轻量级 - 占用内存少
- 共享内存 - 使得从另一个上下文访问状态更容易
- 可以轻松创建响应式UI
- cPython C扩展模块如果正确释放GIL将并行运行
- 对于I/O密集型应用程序是一个很好的选择
缺点
- cPython - 受GIL限制
- 不可中断/不可杀死
- 如果不遵循命令队列/消息泵模型(使用
Queue模块),则需要手动使用同步原语(需要决定锁定的粒度) - 代码通常更难理解和正确编写 - 竞争条件的潜在可能性大大增加
- Jeremy Brown
12
61多进程:利用多个 CPU 和核心。线程也具备这个优点吗? - Deqing
117在Python中,由于全局解释器锁(GIL),单个Python进程无法并行运行线程(利用多个核心)。但是,它可以在I/O绑定操作期间进行上下文切换以实现并发运行。@Deqing不是这样的。 - Andrew Guenther
18直接引用自Python多进程文档(加粗为本人添加):“multiprocessing模块提供本地和远程并发,通过使用子进程而不是线程,有效地绕过全局解释器锁。因此,该模块允许程序员充分利用给定机器上的多个处理器。” - camconn
36是的,@camconn,“来自多进程(multiprocessing)文档”。是的,多进程(multiprocessing)包能够实现这一点,但多线程(multithreading)包却不能,这正是我之前评论所指的。 - Andrew Guenther
20我错了。我是个傻瓜想要表现得聪明。我的错。 - camconn
显示剩余7条评论
895
threading 模块使用线程,multiprocessing 模块使用进程。区别在于:线程在同一内存空间中运行,而进程具有单独的内存空间。这使得使用 multiprocessing 在进程之间共享对象变得有些困难。由于线程使用相同的内存,必须采取预防措施,否则两个线程将同时写入同一内存。这就是全局解释器锁的作用。
生成进程比生成线程略慢一些。
- Sjoerd
12
223cPython中的GIL并不保护您的程序状态,它只保护解释器的状态。请注意不要改变原意。 - Jeremy Brown
53操作系统负责进程调度,线程库负责线程调度。线程共享I/O调度——这可能会成为瓶颈。进程有独立的I/O调度。 - S.Lott
4多进程的IPC性能如何?对于一个需要频繁在进程间共享对象的程序(例如通过multiprocessing.Queue实现),与进程内队列相比,它的性能如何? - KFL
26实际上有很大的区别:http://eli.thegreenplace.net/2012/01/16/python-parallelizing-cpu-bound-tasks-with-multiprocessing/(说明:此链接为一篇英文文章,标题为:“Python并行化处理CPU密集任务的多进程方法”,本回答仅为该标题的翻译) - Andrew Sledge
4如果产生过多的进程,会导致CPU耗尽进程/内存资源,这会有问题吗?但是如果频繁地生成过多线程,情况可能也会类似,只不过相较于多个进程,开销会更小。对吗? - TommyT
显示剩余7条评论
265
多线程的作用是使应用程序具有响应能力。假设您有一个数据库连接并且需要响应用户输入,如果没有使用多线程,如果数据库连接繁忙,则应用程序将无法响应用户。通过将数据库连接拆分为单独的线程,可以使应用程序更具响应性。此外,由于这两个线程在同一进程中,它们可以访问相同的数据结构 - 良好的性能,加上灵活的软件设计。
请注意,由于GIL的原因,应用程序实际上并没有同时执行两个任务,但我们已经将数据库资源锁定放入了一个单独的线程中,以便可以在用户交互和CPU时间之间进行切换。CPU时间在线程之间进行分配。
多进程适用于真正需要同时处理多个任务的情况。假设您的应用程序需要连接到6个数据库并对每个数据集执行复杂的矩阵转换。将每个作业放入单独的线程中可能会有所帮助,因为当一个连接处于空闲状态时,另一个连接可以获得一些CPU时间,但处理不会并行进行,因为GIL意味着您只使用一个CPU的资源。通过将每个作业放入多进程进程中,每个作业都可以在自己的CPU上运行并以全效率运行。
- Simon Hibbs
5
2但是处理不会并行进行,因为GIL意味着您只使用一个CPU的资源。在多进程中的GIL是怎么回事? - Nishant Kashyap
7请重新阅读您引用的那句话所在的句子。Simon谈论的是多线程的处理,而不是多进程处理。 - ArtOfWarfare
在内存差异方面,这些是以前期成本的资本支出为基础的。运行时线程可以像进程一样占用大量资源。您可以控制两者。将它们视为成本。 - MrMesees
@ArtOfWarfare,您能解释一下为什么接受的答案假定如果GIL“正确释放”,就可以实现多线程并行吗? - Loveen Dyall
@LoveenDyall - 我不确定为什么你要找我而不是询问你正在问的答案,但那个要点是在谈论使用C语言编写Python扩展。如果你退出了Python解释器并进入本地代码领域,你绝对可以利用多个CPU核心而不必担心全局解释器锁定,因为它只会锁定解释器,而不是本地代码。除此之外,我不确定他们所说的“正确释放GIL”的确切含义 - 我以前从未编写过Python扩展。 - ArtOfWarfare
109
Python文档引用
此答案的规范版本现在位于重复的问题中:什么是线程和多进程模块之间的差异?
我已经突出了关于进程与线程以及GIL的关键Python文档引用:CPython中的全局解释器锁(GIL)是什么?
进程与线程实验
我进行了一些基准测试,以便更具体地展示差异。
在基准测试中,我计时了在8个超线程 CPU上使用各种线程数量进行CPU和IO绑定工作。每个线程提供的工作总是相同的,因此更多的线程意味着更多的总工作量。
结果如下:
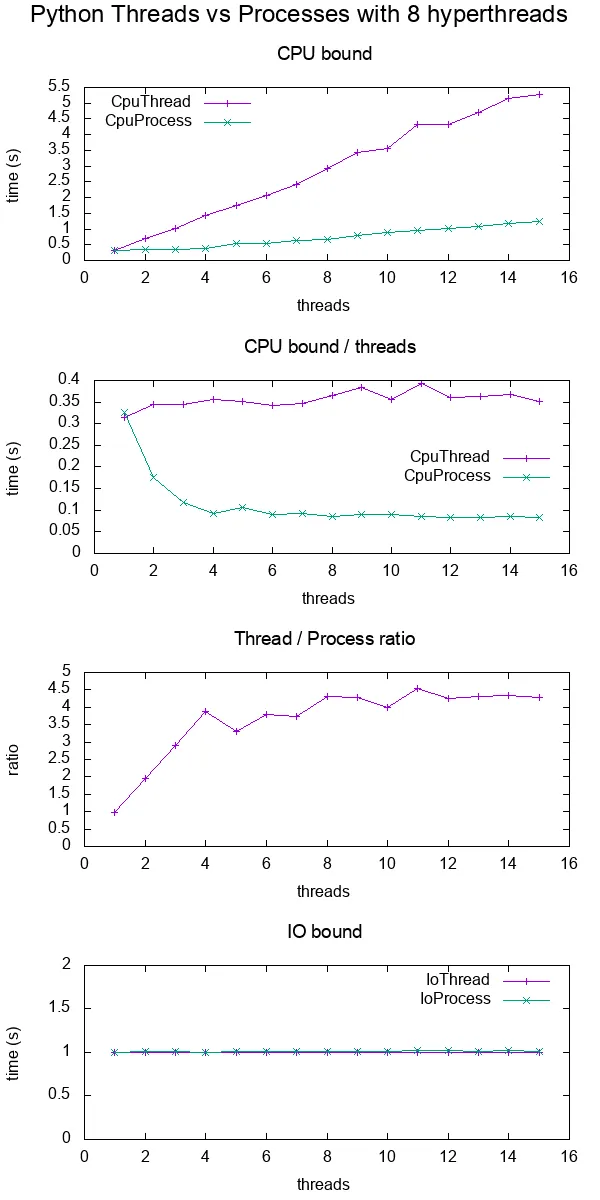
数据绘图。
结论:
对于CPU绑定的工作,多进程始终更快,可能是由于GIL。
对于IO绑定的工作,两者速度完全相同。
线程仅扩展到大约4倍,而不是期望的8倍,因为我使用的是8超线程机器。
与C POSIX CPU绑定的工作形成对比,后者达到了预期的8倍加速:在time(1)输出中,“real”,“user”和“sys”是什么意思?
待办事项:我不知道原因,必须有其他Python效率低下的因素在起作用。
测试代码:
#!/usr/bin/env python3
import multiprocessing
import threading
import time
import sys
def cpu_func(result, niters):
'''
A useless CPU bound function.
'''
for i in range(niters):
result = (result * result * i + 2 * result * i * i + 3) % 10000000
return result
class CpuThread(threading.Thread):
def __init__(self, niters):
super().__init__()
self.niters = niters
self.result = 1
def run(self):
self.result = cpu_func(self.result, self.niters)
class CpuProcess(multiprocessing.Process):
def __init__(self, niters):
super().__init__()
self.niters = niters
self.result = 1
def run(self):
self.result = cpu_func(self.result, self.niters)
class IoThread(threading.Thread):
def __init__(self, sleep):
super().__init__()
self.sleep = sleep
self.result = self.sleep
def run(self):
time.sleep(self.sleep)
class IoProcess(multiprocessing.Process):
def __init__(self, sleep):
super().__init__()
self.sleep = sleep
self.result = self.sleep
def run(self):
time.sleep(self.sleep)
if __name__ == '__main__':
cpu_n_iters = int(sys.argv[1])
sleep = 1
cpu_count = multiprocessing.cpu_count()
input_params = [
(CpuThread, cpu_n_iters),
(CpuProcess, cpu_n_iters),
(IoThread, sleep),
(IoProcess, sleep),
]
header = ['nthreads']
for thread_class, _ in input_params:
header.append(thread_class.__name__)
print(' '.join(header))
for nthreads in range(1, 2 * cpu_count):
results = [nthreads]
for thread_class, work_size in input_params:
start_time = time.time()
threads = []
for i in range(nthreads):
thread = thread_class(work_size)
threads.append(thread)
thread.start()
for i, thread in enumerate(threads):
thread.join()
results.append(time.time() - start_time)
print(' '.join('{:.6e}'.format(result) for result in results))
GitHub upstream + plotting code on same directory。
在Ubuntu 18.10,Python 3.6.7上测试通过,在Lenovo ThinkPad P51笔记本电脑上使用CPU:Intel Core i7-7820HQ CPU(4个核心/8个线程),RAM:2x Samsung M471A2K43BB1-CRC(2x 16GiB),SSD:Samsung MZVLB512HAJQ-000L7(3,000 MB/s)。
可视化给定时间正在运行的线程
这篇文章https://rohanvarma.me/GIL/教会了我,你可以使用threading.Thread的target=参数以及multiprocessing.Process的相同参数在调度线程时运行回调函数。
这使我们能够准确地查看每个时间运行的线程。当这样做时,我们会看到类似于以下内容(我制作了这个特定的图表):
+--------------------------------------+
+ Active threads / processes +
+-----------+--------------------------------------+
|Thread 1 |******** ************ |
| 2 | ***** *************|
+-----------+--------------------------------------+
|Process 1 |*** ************** ****** **** |
| 2 |** **** ****** ** ********* **********|
+-----------+--------------------------------------+
+ Time --> +
+--------------------------------------+
这将表明:
- {{线程}}被GIL完全序列化
- {{进程}}可以并行运行
- Ciro Santilli OurBigBook.com
3
回复:“线程只能扩展到大约4倍,而不是预期的8倍,因为我使用的是8个超线程机器。” 对于CPU绑定任务,应该预期4核机器最多达到4倍。超线程只有在CPU上下文切换时才有帮助。(在大多数情况下,只有“炒作”是有效的。/笑话) - Blaine
SO不喜欢重复答案,所以您应该考虑删除这个答案的实例。 - Andras Deak -- Слава Україні
7@AndrasDeak 我会把它留在这里,因为否则这个页面会变差,某些链接可能会断掉,我会失去辛苦赚来的声望。 - Ciro Santilli OurBigBook.com
51
关键优势在于隔离性。崩溃的进程不会使其他进程崩溃,而崩溃的线程可能会对其他线程造成严重影响。
- Marcelo Cantos
3
6我很确定这是错误的。如果Python中的标准线程由于引发异常而结束,当您加入它时将不会发生任何事情。我编写了自己的Thread子类,可以在线程中捕获异常,并在加入线程时重新引发该异常,因为忽略此异常实际上是非常糟糕的(会导致其他难以发现的错误)。进程的行为也是一样的。除非你指的是Python实际崩溃,否则都是如此。如果您发现Python崩溃,那肯定是一个bug,您应该报告给相关人员。Python应该始终引发异常,而不是崩溃。 - ArtOfWarfare
11线程不仅能引发异常。通过有缺陷的本地或ctypes代码,一个无序的线程可以破坏进程中任何位置的内存结构,包括Python运行时本身,从而导致整个进程被损坏。 - Marcelo Cantos
从一般的角度来看,Marcelo的回答更加完整。如果系统真的很关键,你永远不应该依赖于“事情按预期工作”的事实。使用单独的内存空间,必须发生溢出才能损坏附近的进程,这比Marcelo所述的情况更不可能发生。 - DGoiko
39
如问题所述,Python中的多进程(Multiprocessing)是实现真正并行的唯一方法。而多线程(Multithreading)无法实现这一点,因为GIL会阻止线程并行运行。
因此,在Python中,线程可能并不总是有用的,事实上,根据您尝试实现的内容,它甚至可能导致性能变差。例如,如果您正在执行计算密集型任务,如解压缩gzip文件或3D渲染(任何CPU密集型任务),则线程可能会妨碍您的性能而非帮助。在这种情况下,你需要使用多进程(Multiprocessing),因为只有该方法实际上可以并行运行,并有助于分配任务负载。但这可能会有一些开销,因为多进程(Multiprocessing)涉及将脚本内存复制到每个子进程中,这可能会对大型应用程序造成问题。
然而,当您的任务是IO-bound时,多线程(Multithreading)变得有用。例如,如果您的大部分任务涉及等待 API调用,则应使用多线程(Multithreading),因为在等待时启动另一个线程中的请求,而不是让您的CPU闲置。
简而言之:
- 多线程(Multithreading)是并发的,并用于IO-bound任务
- 多进程实现真正的并行处理,适用于CPU密集型任务
- buydadip
2
2你能举一个IO绑定的任务的例子吗? - YellowPillow
8假设你正在多次调用API请求数据,在这种情况下,大部分时间都花费在等待网络上。当它等待网络I/O时,GIL可以被释放以供下一个任务使用。然而,该任务需要重新获取GIL才能执行与每个API请求相关联的任何Python代码的其余部分,但是由于任务正在等待网络,因此不需要持有GIL。 - buydadip
29
还有一件事没有提到,那就是速度取决于您使用的操作系统。在Windows中,进程是昂贵的,因此在Windows中使用线程会更好,但在Unix中,进程比它们的Windows变体更快,因此在Unix中使用进程更安全且能够快速生成。
- chrisg
3
8你是否有实际数据来支持这个想法?例如,在Windows和Unix上,对比单线程执行任务、多线程执行任务以及多进程执行任务的表现。请提供具体数据。 - ArtOfWarfare
3同意@ArtOfWarfare的问题。数字是多少?你推荐在Windows中使用线程吗? - m3nda
操作系统并不重要,因为Python的全局解释器锁(GIL)不允许在单个进程上运行多个线程。在Windows和Linux中,使用多进程会更快。 - Viliami
23
其他回答更多关注于多线程与多进程方面,但在Python中需要考虑全局解释器锁(GIL)。当创建更多线程(例如k个)时,通常不会以k倍的性能提高,因为它仍将作为单线程应用程序运行。GIL是一个全局锁,它锁定了所有内容,只允许单线程执行并利用单个核心。性能在使用C扩展(如numpy、Network、I/O等)的地方会增加,这些地方做了大量的后台工作,并释放了GIL。
因此,在使用线程时,只有一个操作系统级别的线程,而Python创建伪线程,这些线程完全由线程本身管理,但实际上作为单个进程运行。这些伪线程之间进行抢占。如果CPU运行在最大容量下,则可以切换到多进程。
现在,在自包含的执行实例中,您可以选择使用池。但在重叠数据的情况下,您可能希望进程进行通信,此时应使用
因此,在使用线程时,只有一个操作系统级别的线程,而Python创建伪线程,这些线程完全由线程本身管理,但实际上作为单个进程运行。这些伪线程之间进行抢占。如果CPU运行在最大容量下,则可以切换到多进程。
现在,在自包含的执行实例中,您可以选择使用池。但在重叠数据的情况下,您可能希望进程进行通信,此时应使用
multiprocessing.Process。- Chitransh Gaurav
2
因此,当使用线程时,只有一个操作系统级别的线程,而Python创建的伪线程完全由线程本身管理,但实际上是作为单个进程运行的。这不是真的。Python线程是真正的操作系统线程。您所描述的是绿色线程,Python不使用它。只是线程需要持有GIL才能执行Python字节码,这使得线程执行变成了顺序执行。 - Darkonaut
现在,对于自包含的执行实例,您可以选择使用池。但是,在存在重叠数据的情况下,您可能希望进程进行通信,因此应该使用multiprocessing.Process。什么池?multiprocessing库有一个池,因此这没有太多意义。 - AMC
16
多进程
- 多进程增加CPU以增加计算能力。
- 多个进程同时执行。
- 创建进程的过程耗时且资源密集。
- 多处理可以是对称的或非对称的。
- Python中的multiprocessing库使用单独的内存空间、多个CPU核心、绕过CPython中的GIL限制,子进程可以被“杀死”(例如程序中的函数调用),使用起来更加方便。
- 该模块的一些注意事项包括较大的内存占用和IPC的一些更复杂的开销。
多线程
- 多线程创建一个进程的多个线程以增加计算能力。
- 单个进程的多个线程同时执行。
- 创建线程在时间和资源上都比较经济。
- 多线程库是轻量级的,共享内存,负责响应式UI,适用于I/O绑定应用程序。
- 该模块无法“杀死”线程,受GIL的影响。
- 多个线程存在于同一进程的同一空间中,每个线程将执行特定的任务,具有自己的代码、栈内存、指令指针和共享堆内存。
- 如果一个线程有内存泄漏,它可能会损坏其他线程和父进程。
使用Python进行多线程和多进程的示例
Python 3具有启动并行任务的功能。这使我们的工作更加容易。
以下是一个示例:
ThreadPoolExecutor 示例
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
进程池执行器
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
- Jeril
3
如果你能在同一个示例中展示
ThreadPoolExecutor和ProcessPoolExecutor,效果会更好。 - undefined像巨大矩阵的乘法一样 - undefined
1@Chandan 你可以使用相同的例子
ProcessPoolExecutor,然后将 with concurrent.futures.ProcessPoolExecutor() as executor: 改为 with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:。 - undefined11
线程共享同一内存空间,以确保两个线程不共享相同的内存位置,因此需要采取特殊预防措施。CPython解释器使用一种称为全局解释器锁(GIL)的机制来处理这个问题。
GIL是什么?
在CPython中,全局解释器锁(GIL)是一个互斥锁,用于保护Python对象的访问,防止多个线程同时执行Python字节码。这个锁主要是必需的,因为CPython的内存管理不是线程安全的。
针对主要问题,我们可以通过使用用例进行比较,如何比较?
1-线程使用情况:在GUI程序中,线程可用于使应用程序具有响应性。例如,在文本编辑程序中,一个线程可以负责记录用户输入,另一个线程可以负责显示文本,第三个线程可以进行拼写检查等等。在这种情况下,程序必须等待用户交互,这是最大的瓶颈。线程的另一个使用情况是那些IO绑定或网络绑定的程序,例如网络爬虫。
2-多处理使用情况:在程序需要CPU密集型处理而不需要进行任何IO或用户交互的情况下,多处理优于线程。
- EL TEGANI MOHAMED HAMAD GABIR
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接