我学习了这两种模式,但并不理解它们之间的区别。
我不知道在何时何地使用这些模式。
有人能解释一下它们的差异和使用案例吗?
我学习了这两种模式,但并不理解它们之间的区别。
我不知道在何时何地使用这些模式。
有人能解释一下它们的差异和使用案例吗?
主要区别在于策略模式封装了一组单一相关行为,而访问者模式则封装了多个这样的组。
访问者模式的意图:
表示要对对象结构的元素执行的操作。访问者允许您定义一个新的操作,而不必更改它所操作的元素的类。
如果需要,使用访问者模式:
尽管访问者模式提供了在Object中添加新操作而不更改现有代码的灵活性,但这种灵活性也带来了缺点。
如果添加了新的可访问对象,则需要更改Visitor和ConcreteVisitor类中的代码。有一种解决此问题的方法:使用反射,这会影响性能。
有关详细信息,请参阅oodesign文章和sourcemaking文章
策略模式的意图:
定义一组算法,将每个算法封装起来,并使它们可以互换。策略让算法独立于使用它的客户端而变化。
策略允许您更改对象的内部实现。
有关详细信息,请参阅下面的SE问题:
Visitor 可以是一个类,根据正在处理的物品种类定义不同种类的计算。它是一个服务,将价格计算的差异从物品层次结构中移开。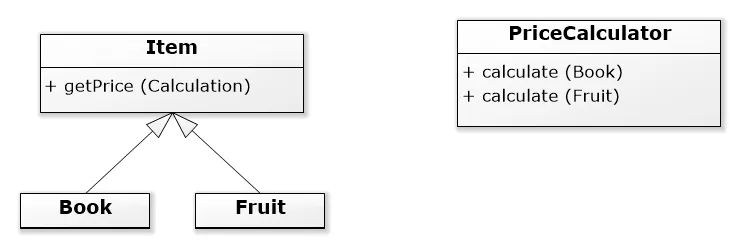 其中
其中 getPrice 的主体可能如下所示:getPrice(Calculation c) {
return c.calculate(this); // <-- visitor.visit( specific implementation )
}
在 ShoppingCart 中,你将会这样做:
calc = getPriceCalculator()
foreach item in items:
totalPrice += item.getPrice(calc)
想象这样的情境:在黑色星期五,你想做一些疯狂的折扣,所有图书 7 折,所有水果 5 折。你可以轻松地实现类似以下的操作:
BlackFridayCalculator extends PriceCalculator {
calculate(Book b) { return 0.3 * parent.calculate(b) }
calculate(Fruit f) { return 0.5 * parent.calculate(f) }
}
// and in getPriceCalculator:
return (black friday time) ? new BlackFridayCalculator() : new PriceCalculator();
策略 可以有不同种类的计算(策略)层次结构,每个项目都可以定义应该使用哪种计算(策略)。
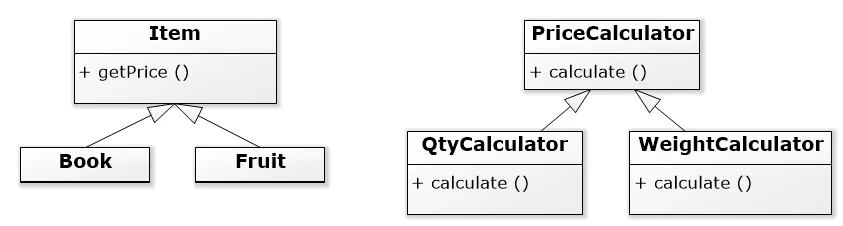
Item方法getCalculator,让每个项目选择它需要的计算方法。Fruit默认使用WeightCalculator并创建一个将按数量出售的水果子集。