我从我的手机接收到了使用天城体(印地语)脚本编写的短信,并将其传输到我的桌面程序,但是该程序显示的数据采用编码方式(例如:091A09470924002009240924),我发现这是Unicode编码。是否有现有的库可以将其转换为印地文本?如果没有,我该如何编写一个方法来实现转换?我正在使用C#。
3个回答
1
这是我用于将格鲁吉亚Unicode转换为其拉丁文等效文本的代码片段。
string[] charset = new string[33] { "a", "b", "g", "d", "e", "v", "z", "T", "i", "k", "l", "m", "n", "o", "p", "J", "r", "s","t", "u", "f", "q", "R", "y", "S", "C", "c", "Z", "w", "W", "x", "j", "h" };
string unicodeString = "აბ, - გდ";
string latin_string = "";
byte[] unicodeBytes = Encoding.Unicode.GetBytes(unicodeString);
for (int p = 0; p < unicodeBytes.Length / 2; p++)
{
if (unicodeBytes[p * 2] > 207 && unicodeBytes[p * 2] < 241)
latin_string += charset[unicodeBytes[p * 2] - 208];
else
latin_string += Convert.ToChar(unicodeBytes[p * 2]).ToString();
}
只解释必要的部分:
Encoding.Unicode.GetBytes(unicodeString); 返回字节数组,该数组的长度为 2 * unicodeString.Length。因此,unicodestring 中的每个字母都有一对字节。
为了更好地解释,这里附上一张图片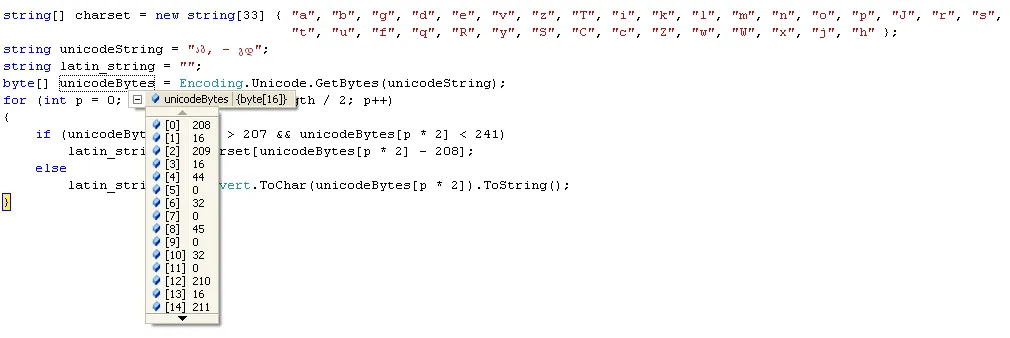
unicodeBytes 的偶数索引具有表示要解码的字母的值。格鲁吉亚字母表的第一个字母从 208 开始,以 240 结束(总共 33 个)。因此,如果 unicodeBytes 的值在 [208;240] 范围内,则必须使用 charset 字符串数组获取相应的拉丁文等效项,否则 unicodeBytes 的值就是字符代码。
我不知道是否有相关的库,但这种方法将为您提供编写自己的转换器的基本思路。
- Nika G.
1
使用System.Text.Encoding类。它有一个GetChars(byte[])方法。可能需要适当的字体,因为某些印地语符号可以用多种方式书写。
- Mike Mozhaev
0
谢谢您的回复,它们帮助我找到了确切的解决方案 - http://social.msdn.microsoft.com/Forums/en/netfxbcl/thread/12a3558d-fe48-44fd-840e-03facfd9c944
- Aakar
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接