我正在尝试使用Spark Kafka直接流方法。根据文档,它通过创建与kafka主题分区数量相同的RDD分区来简化并行处理。根据我的理解,Spark将为每个RDD分区创建一个执行器来执行计算。
因此,当我以yarn-cluster模式提交应用程序,并将选项num-executors指定为不同于分区数的值时,将有多少个执行器?
例如,有一个具有2个分区的kafka主题,我将num-executors指定为4:
export YARN_CONF_DIR=$HADOOP_HOME/client_conf
./bin/spark-submit \
--class playground.MainClass \
--master yarn-cluster \
--num-executors 4 \
../spark_applications/uber-spark-streaming-0.0.1-SNAPSHOT.jar \
127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9095 topic_1
我尝试了一下并发现执行器的数量为4,每个执行器都从kafka读取和处理数据。为什么?Kafka主题中只有2个分区,那么4个执行器如何从仅有2个分区的kafka主题中读取呢?
下面是Spark应用程序和日志的详细信息。
我的Spark应用程序,它在每个执行器中(在flatMap方法中)打印接收到的来自kafka的消息:
...
String brokers = args[0];
HashSet<String> topicsSet = new HashSet<String>(Arrays.asList(args[1].split(",")));
kafkaParams.put("metadata.broker.list", brokers);
JavaPairInputDStream<String, String> messages =
KafkaUtils.createDirectStream(jssc, String.class, String.class, StringDecoder.class, StringDecoder.class,
kafkaParams, topicsSet);
JavaPairDStream<String, Integer> wordCounts =
messages.flatMap(new FlatMapFunction<Tuple2<String, String>, String>()
{
public Iterable<String> call(Tuple2<String, String> tuple) throws Exception
{
System.out.println(String.format("[received from kafka] tuple_1 is %s, tuple_2 is %s", tuple._1(),
tuple._2())); // print the kafka message received in executor
return Arrays.asList(SPACE.split(tuple._2()));
}
}).mapToPair(new PairFunction<String, String, Integer>()
{
public Tuple2<String, Integer> call(String word) throws Exception
{
System.out.println(String.format("[word]: %s", word));
return new Tuple2<String, Integer>(word, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>()
{
public Integer call(Integer v1, Integer v2) throws Exception
{
return v1 + v2;
}
});
wordCounts.print();
Runtime.getRuntime().addShutdownHook(new Thread(){
@Override
public void run(){
System.out.println("gracefully shutdown Spark!");
jssc.stop(true, true);
}
});
jssc.start();
jssc.awaitTermination();
我的Kafka主题有2个分区。字符串"hello hello word 1", "hello hello word 2", "hello hello word 3"等被发送到该主题。
Topic: topic_2 PartitionCount:2 ReplicationFactor:2 Configs:
Topic: topic_2 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: topic_2 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Web控制台:
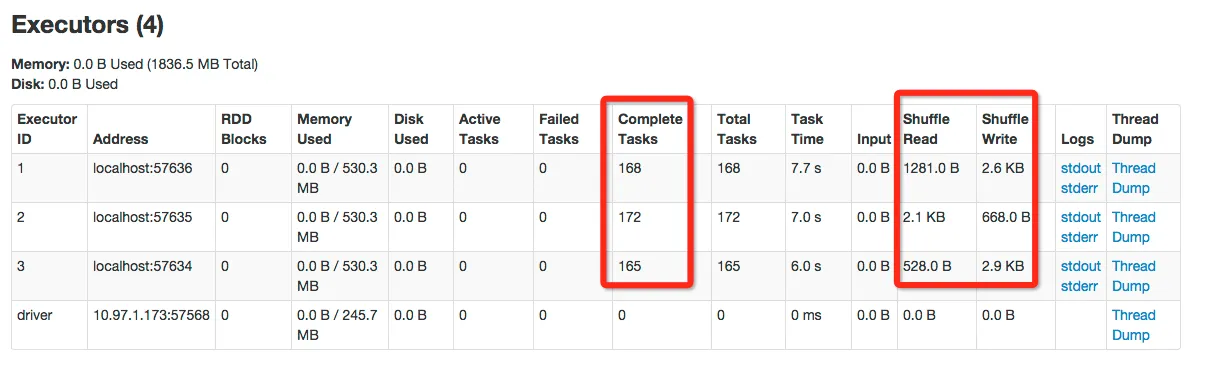
执行器1的控制台输出:
...
[received from kafka] tuple_1 is null, tuple_2 is hello hello world 12
[word]: hello
[word]: hello
[word]: world
[word]: 12
...
执行程序2的控制台输出:
...
[received from kafka] tuple_1 is null, tuple_2 is hello hello world 2
[word]: hello
[word]: hello
[word]: world
[word]: 2
...
执行者3的控制台输出:
...
[received from kafka] tuple_1 is null, tuple_2 is hello hello world 3
[word]: hello
[word]: hello
[word]: world
[word]: 3
...