在下面的问题中,注意到无论如何都会下载完整的仓库(只有检出是部分的)。
由于git内部工作机制涉及快照和哈希计算,部分克隆(仅下载仓库的一部分)是不可能的。
问 我的理解正确吗?
为什么无法进行Git存储库的部分克隆?
3
- participant
2
我认为这个答案回答了你的问题:https://dev59.com/vnE85IYBdhLWcg3w2HNa#20921308 - edi9999
请参阅Git 2.17+的git partial clone(或“narrow clone”):https://dev59.com/unA75IYBdhLWcg3wy8br#48852630 - VonC
1个回答
1
将 git 仓库视为一个巨大的图形。实际上,它背后有一些复杂的数学原理...所有文件/对象都以某种方式相互连接,而 git 的速度、灵活性和可靠性正是基于这个图形之上的。 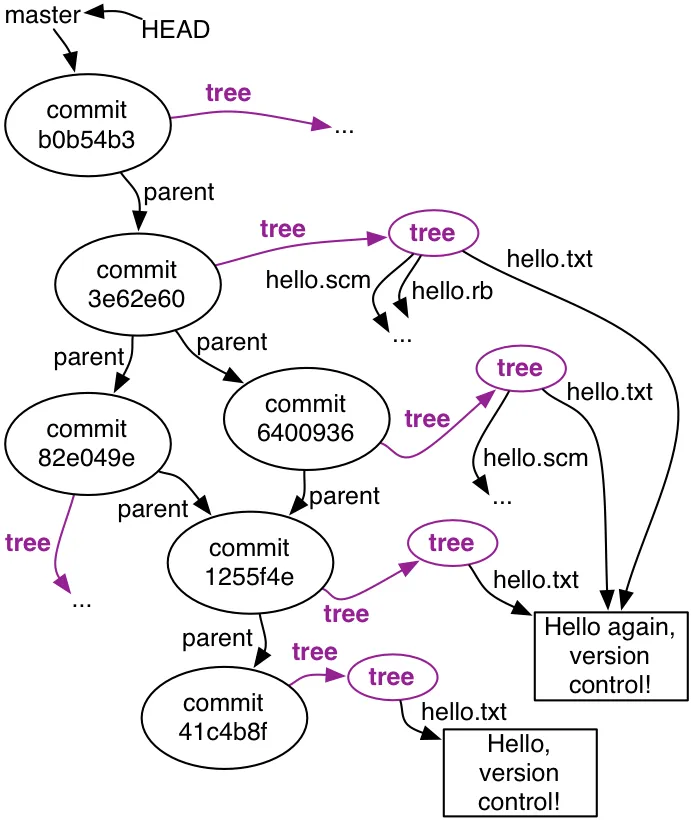 (图片: http://web.mit.edu/6.005/www/fa15/classes/05-version-control/)
(图片: http://web.mit.edu/6.005/www/fa15/classes/05-version-control/) 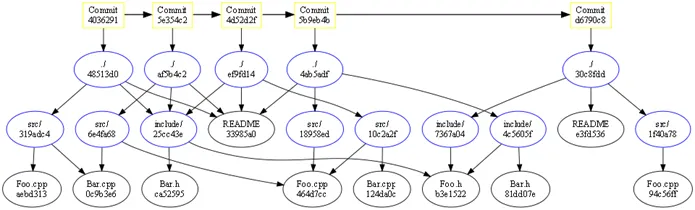 (图片: http://evadeflow.com/wp-content/uploads/2011/01/git_object_graph_thumb.png)
如果您没有拥有整个图形,很可能您将无法告诉文件的整个历史、状态和路径,因为您缺少与此文件起源的连接。如果版本库中的子目录在开始时不存在,但稍后移动到该目录中的某些文件已经存在,那么会发生什么?你如何跟踪它们?
(图片: http://evadeflow.com/wp-content/uploads/2011/01/git_object_graph_thumb.png)
如果您没有拥有整个图形,很可能您将无法告诉文件的整个历史、状态和路径,因为您缺少与此文件起源的连接。如果版本库中的子目录在开始时不存在,但稍后移动到该目录中的某些文件已经存在,那么会发生什么?你如何跟踪它们?
此外,服务器无法确定您需要哪些对象,因为Git不使用自己的服务器应用程序,而是使用HTTP服务器和SSH服务器。因此,远程服务器只能传递文件,但不能确定您实际需要哪些文件。
在“Git中检出子目录?”中接受的答案正是指出了这一点:
请注意,即使Git下载的某些文件不会出现在您的工作树中,稀疏检出仍然要求您下载整个存储库。
因此,在Git获取了整个图形之后,它可以删除所有这些对象,因为(与服务器相反)它可以确定是否需要它们。
更新:为回答您的问题:快照都保存并由哈希引用,因此是Git的内部工作负责此操作。
(图片: http://web.mit.edu/6.005/www/fa15/classes/05-version-control/)
(图片: http://evadeflow.com/wp-content/uploads/2011/01/git_object_graph_thumb.png)
如果您没有拥有整个图形,很可能您将无法告诉文件的整个历史、状态和路径,因为您缺少与此文件起源的连接。如果版本库中的子目录在开始时不存在,但稍后移动到该目录中的某些文件已经存在,那么会发生什么?你如何跟踪它们?{kind=link}
此外,服务器无法确定您需要哪些对象,因为Git不使用自己的服务器应用程序,而是使用HTTP服务器和SSH服务器。因此,远程服务器只能传递文件,但不能确定您实际需要哪些文件。
在“Git中检出子目录?”中接受的答案正是指出了这一点:
请注意,即使Git下载的某些文件不会出现在您的工作树中,稀疏检出仍然要求您下载整个存储库。
因此,在Git获取了整个图形之后,它可以删除所有这些对象,因为(与服务器相反)它可以确定是否需要它们。
更新:为回答您的问题:快照都保存并由哈希引用,因此是Git的内部工作负责此操作。
- 0xpentix
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接