我有一个XPath表达式,它给我提供了以下类似的值序列:
1 2 2 3 4 5 5 6 7
使用distinct-values(),可以轻松将其转换为唯一值序列1 2 3 4 5 6 7。然而,我想要提取的是重复值列表= 2 5。我想不到一种简单的方法来完成这个任务。有人能帮忙吗?
使用这个简单的XPath 2.0表达式::
$vSeq[index-of($vSeq,.)[2]]
其中$vSeq是我们想要查找重复项的值序列。
关于这个“工作原理”的解释,请参见:
简言之,这张图片可以作为视觉解释。
如果序列是:
$vSeq = 1, 2, 3, 2, 4, 5, 6, 7, 5, 7, 5
然后评估上述XPath表达式会产生:2, 5, 7
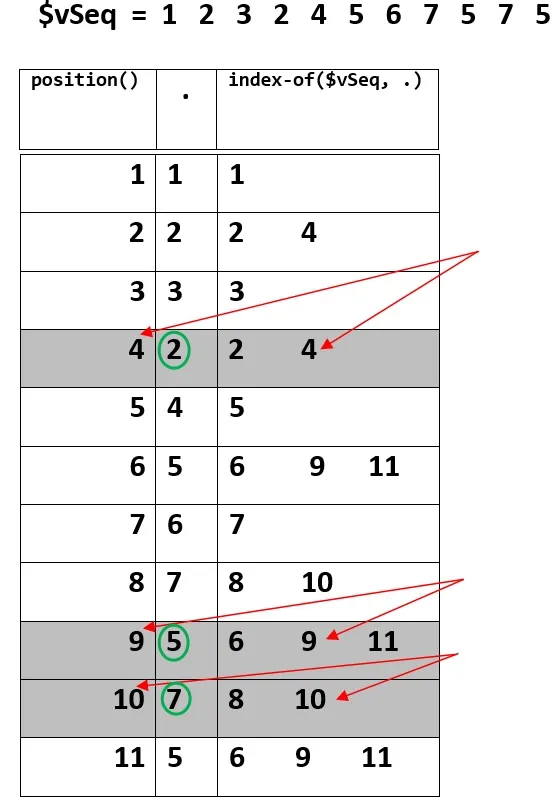
关于:
distinct-values(
for $item in $seq
return if (count($seq[. eq $item]) > 1)
then $item
else ())
这个函数会遍历序列中的所有项,如果有至少两个相同的项,就会返回该项。然后你需要使用 distinct-values() 函数来从列表中移除重复项。
计算您的原始集合与不同值集之间的差异。这就是出现次数多于一次的数字集合。请注意,如果在原始序列中它们出现超过两次,则此结果集中的数字并非必须是不同的,因此如果需要,可以再次转换为不同值集。
<xsl:for-each select="/r/a">
<xsl:variable name="cur" select="." />
<xsl:if test="count(./preceding-sibling::a[. = $cur]) > 0 and count(./following-sibling::a[. = $cur]) = 0">
<xsl:value-of select="." />
</xsl:if>
</xsl:for-each>