我需要一个正则表达式来验证一个包含在输入字符串中的完整的英国邮编,包括所有不常见的邮编形式和通常的形式。例如:
匹配
- CW3 9SS
- SE5 0EG
- SE50EG
- se5 0eg
- WC2H 7LT
不匹配
- aWC2H 7LT
- WC2H 7LTa
- WC2H
匹配
不匹配
我建议您查看英国政府邮编数据标准 [链接已失效; XML的存档,请参见Wikipedia讨论]。该文提供了有关数据的简要描述,并且所附的xml模式提供了一个正则表达式。它可能并不完全符合您的需求,但是是一个很好的起点。该正则表达式与XML略有不同,因为在A9A 9AA格式的第三个位置上允许使用P字符。
英国政府提供的正则表达式是:
([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?))))\s?[0-9][A-Za-z]{2})
正如维基百科讨论中所指出的,这将允许一些非真实邮政编码(例如以AA、ZY开头的编码),它们提供了一个更严格的测试,您可以尝试一下。
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$。 - wieczorek1990我最近发布了一篇答案,是关于使用R语言处理英国邮政编码的这个问题。我发现英国政府的正则表达式模式是错误的,无法正确地验证一些邮政编码。不幸的是,这里许多答案都是基于这个错误的模式。
我将概述以下一些问题,并提供一个修订后的正则表达式,实际上可以工作。
我的回答(以及正则表达式一般):
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$
像许多开发人员一样,他们复制/粘贴代码(尤其是正则表达式)并期望它们能够正常工作。虽然这在理论上很好,但在这种特定情况下会失败,因为从本文档中复制/粘贴实际上会将一个字符(空格)更改为换行符,如下所示:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))
[0-9][A-Za-z]{2})$
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^^ ^ ^ ^^
fooA11 1AA 这样的值可以通过。这是因为他们已经单独地锚定了第一个选项的开头和第二个选项的结尾,就像上面的正则表达式所指出的那样。^(断言位于行首)仅适用于第一个选项 ([Gg][Ii][Rr] 0[Aa]{2}),因此第二个选项将验证以邮政编码结尾的任何字符串(无论前面是什么)。$,因此 GIR 0AAfoo 也被接受。^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$
^(([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2}))$
^^ ^^
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^^
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
[0-9]设为可选项。这会导致正则表达式匹配格式不正确的邮政编码,例如AAA 1AA。[0-9]仅匹配一次):^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?)))) [0-9][A-Za-z]{2})$
^
这个正则表达式的性能非常差。首先,他们将最不可能匹配GIR 0AA的模式选项放在了开头。与任何其他邮政编码相比,有多少用户可能有这个邮政编码;可能从来没有?这意味着每次使用正则表达式时,它必须先耗尽这个选项,然后才能进入下一个选项。为了查看性能如何受到影响,请比较原始正则表达式所需的步骤数(35)与翻转选项后的相同正则表达式(22)。
性能的第二个问题是由整个正则表达式的结构方式引起的。如果一个失败了,回溯每个选项是没有意义的。当前正则表达式的结构方式可以大大简化。我在答案部分提供了一个解决方案。
这可能不被认为是一个问题,但它确实引起了大多数开发人员的关注。正则表达式中的空格不是可选的,这意味着输入邮政编码的用户必须在邮政编码中放置一个空格。通过在空格后添加?来使它们变成可选项,可以轻松解决这个问题。请参见答案部分以获取解决方案。
解决问题部分中列出的所有问题并简化模式,可得到以下更短、更简洁的模式。由于我们正在验证邮政编码作为一个整体(而不是单个部分),因此可以删除大多数组:
^([A-Za-z][A-Ha-hJ-Yj-y]?[0-9][A-Za-z0-9]? ?[0-9][A-Za-z]{2}|[Gg][Ii][Rr] ?0[Aa]{2})$
通过删除一个情况(大写或小写)的所有范围并使用不区分大小写标志,可以进一步缩短此内容。 注意:有些语言没有这个标志,因此请使用上面较长的内容。每种语言都以不同的方式实现不区分大小写标志。
^([A-Z][A-HJ-Y]?[0-9][A-Z0-9]? ?[0-9][A-Z]{2}|GIR ?0A{2})$
如果你的正则表达式引擎支持,使用\d替换[0-9]可以让正则表达式更加简洁:
^([A-Z][A-HJ-Y]?\d[A-Z\d]? ?\d[A-Z]{2}|GIR ?0A{2})$
如果不需要特定的字母字符,可以使用以下模式(请记住,1. 修复英国政府的正则表达式 中的简化也已应用于此处):
^([A-Z]{1,2}\d[A-Z\d]? ?\d[A-Z]{2}|GIR ?0A{2})$
如果您不关心特殊情况GIR 0AA,那么更进一步:
^[A-Z]{1,2}\d[A-Z\d]? ?\d[A-Z]{2}$
我不建议过度验证邮政编码,因为新的地区、区域和子区域可能随时出现。但我建议潜在地增加对边缘情况的支持。一些特殊情况存在,并在这篇维基百科文章中进行了概述。
以下是包括3.(3.1、3.2、3.3)小节的复杂正则表达式。
关于1. 修复英国政府的正则表达式中的模式:
^(([A-Z][A-HJ-Y]?\d[A-Z\d]?|ASCN|STHL|TDCU|BBND|[BFS]IQQ|PCRN|TKCA) ?\d[A-Z]{2}|BFPO ?\d{1,4}|(KY\d|MSR|VG|AI)[ -]?\d{4}|[A-Z]{2} ?\d{2}|GE ?CX|GIR ?0A{2}|SAN ?TA1)$
关于2. 简化模式:
^(([A-Z]{1,2}\d[A-Z\d]?|ASCN|STHL|TDCU|BBND|[BFS]IQQ|PCRN|TKCA) ?\d[A-Z]{2}|BFPO ?\d{1,4}|(KY\d|MSR|VG|AI)[ -]?\d{4}|[A-Z]{2} ?\d{2}|GE ?CX|GIR ?0A{2}|SAN ?TA1)$
维基百科文章目前的陈述如下(部分格式稍作简化):
AI-1111: 安圭拉ASCN 1ZZ: 阿森松岛STHL 1ZZ: 圣赫勒拿TDCU 1ZZ: 特里斯坦-达库尼亚群岛BBND 1ZZ: 英属印度洋领地BIQQ 1ZZ: 英属南极领地FIQQ 1ZZ: 福克兰群岛GX11 1ZZ: 直布罗陀PCRN 1ZZ: 皮特凯恩群岛SIQQ 1ZZ: 南乔治亚岛和南桑威奇群岛TKCA 1ZZ: 特克斯和凯科斯群岛BFPO 11: 阿克罗提里和德凯利亚ZZ 11 & GE CX: 百慕大(参见此文件)KY1-1111: 开曼群岛(参见此文件)VG1111: 英属维尔京群岛(参见此文件)MSR 1111: 蒙特塞拉特(参见此文件)一个全面的正则表达式,仅匹配英国海外领土,可能看起来像这样:
^((ASCN|STHL|TDCU|BBND|[BFS]IQQ|GX\d{2}|PCRN|TKCA) ?\d[A-Z]{2}|(KY\d|MSR|VG|AI)[ -]?\d{4}|(BFPO|[A-Z]{2}) ?\d{2}|GE ?CX)$
尽管最近已经将其更改以更好地与英国邮政编码系统对齐为BF#(其中#代表数字),但它们被视为可选备用邮政编码。这些邮政编码遵循(曾经遵循)BFPO,后跟1-4个数字的格式:
^BFPO ?\d{1,4}$
圣诞老人还有另外一个特殊情况(如其他答案中所提到的):SAN TA1是一个有效的邮政编码。匹配此项的正则表达式非常简单:
^SAN ?TA1$
看起来我们将使用^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$,这是Minglis上面建议的略微修改版。
然而,我们需要调查确切的规则,因为上面列出的各种解决方案似乎适用不同的字母允许规则。
经过一些研究,我们找到了更多信息。显然,“govtalk.gov.uk”网站上的一个页面指向邮政编码规范govtalk-postcodes。这指向一个XML模式XML Schema,其中提供了邮政编码规则的“伪正则表达式”语句。
我们采用了这个语句并稍作修改,得到了以下表达式:
^((GIR &0AA)|((([A-PR-UWYZ][A-HK-Y]?[0-9][0-9]?)|(([A-PR-UWYZ][0-9][A-HJKSTUW])|([A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y]))) &[0-9][ABD-HJLNP-UW-Z]{2}))$
这样做可以使空格变为可选项,但是只允许一个空格(将'&'替换为'{0,}'可以无限制使用空格)。它假设所有文本都必须是大写字母。
如果你想要允许小写字母,并且有任意数量的空格,请使用:
^(([gG][iI][rR] {0,}0[aA]{2})|((([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y]?[0-9][0-9]?)|(([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW])|([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]))) {0,}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2}))$
这不包括海外领Territory土,仅强制格式,而不是不同地区的存在。它基于以下规则:
可以接受以下格式:
其中:
祝一切顺利
Colin
^(([gG][iI][rR] {0,}0[aA]{2})|(([aA][sS][cC][nN]|[sS][tT][hH][lL]|[tT][dD][cC][uU]|[bB][bB][nN][dD]|[bB][iI][qQ][qQ]|[fF][iI][qQ][qQ]|[pP][cC][rR][nN]|[sS][iI][qQ][qQ]|[iT][kK][cC][aA]) {0,}1[zZ]{2})|((([a-pr-uwyzA-PR-UWYZ][a-hk-yxA-HK-XY]?[0-9][0-9]?)|(([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW])|([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]))) {0,}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2}))$。 - David Bradshaw{0,}而不是*? - Code Animal没有一个完整的英国邮政编码正则表达式可以验证邮政编码。您可以使用正则表达式检查邮政编码是否处于正确的格式,但不能检查它是否真实存在。
邮政编码是任意复杂且不断变化的。例如,区号W1可能永远不会拥有每个邮政编码区域中1到99之间的每个数字。
您不能期望当前的情况永远不变。例如,在1990年,邮局认为阿伯丁有点拥挤。他们在AB1-5的末尾添加了0,使其成为AB10-50,然后创建了许多介于这些之间的邮政编码。
每当建造新街道时,都会创建一个新的邮政编码。这是获得建筑许可的过程的一部分;地方当局有义务将此与邮局保持更新(并非所有地方当局都这样做)。
此外,正如其他用户所指出的那样,还有特殊的邮政编码,例如Girobank、GIR 0AA以及给圣诞老人的信的邮政编码SAN TA1 - 您可能不想将任何东西寄到那里,但似乎没有其他答案涵盖了这些编码。
然后,还有 BFPO 邮政编码,现在更改为更标准的格式。两种格式都将有效。最后,还有海外领土来源维基百科。+----------+----------------------------------------------+ | 邮政编码 | 位置 | +----------+----------------------------------------------+ | AI-2640 | 安圭拉 | | ASCN 1ZZ | 阿森松岛 | | STHL 1ZZ | 圣赫勒拿 | | TDCU 1ZZ | 特里斯坦-达库尼亚 | | BBND 1ZZ | 英属印度洋领地 | | BIQQ 1ZZ | 英属南极领地 | | FIQQ 1ZZ | 福克兰群岛 | | GX11 1AA | 直布罗陀 | | PCRN 1ZZ | 皮特凯恩群岛 | | SIQQ 1ZZ | 南乔治亚岛和南桑威奇群岛 | | TKCA 1ZZ | 特克斯和凯科斯群岛 | +----------+----------------------------------------------+下一步,您需要考虑到英国将其邮政编码系统“导出”到世界上许多地方。任何验证“英国”邮政编码的东西也会验证其他许多国家/地区的邮政编码。
^([A-PR-UWYZ0-9][A-HK-Y0-9][AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]? {1,2}[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)$
0-9 开头的邮政编码,而实际上不能。 - Luigi Plinge我查看了上面的一些答案,不建议使用@Dan的答案(约为2010年12月15日)中的模式,因为它错误地将近0.4%的有效邮政编码标记为无效,而其他答案没有这个问题。
Ordnance Survey提供了一个名为Code Point Open的服务,其中包含了英国所有当前邮政编码单元的列表。
我使用grep对此数据中的所有邮政编码(截至2013年7月6日)运行了以上每个正则表达式:
cat CSV/*.csv |
# Strip leading quotes
sed -e 's/^"//g' |
# Strip trailing quote and everything after it
sed -e 's/".*//g' |
# Strip any spaces
sed -E -e 's/ +//g' |
# Find any lines that do not match the expression
grep --invert-match --perl-regexp "$pattern"
总共有1,686,202个邮政编码。
以下是不匹配每个$pattern的有效邮政编码数量:
'^([A-PR-UWYZ0-9][A-HK-Y0-9][AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]?[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)$'
# => 6016 (0.36%)
'^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$'
# => 0
'^GIR[ ]?0AA|((AB|AL|B|BA|BB|BD|BH|BL|BN|BR|BS|BT|BX|CA|CB|CF|CH|CM|CO|CR|CT|CV|CW|DA|DD|DE|DG|DH|DL|DN|DT|DY|E|EC|EH|EN|EX|FK|FY|G|GL|GY|GU|HA|HD|HG|HP|HR|HS|HU|HX|IG|IM|IP|IV|JE|KA|KT|KW|KY|L|LA|LD|LE|LL|LN|LS|LU|M|ME|MK|ML|N|NE|NG|NN|NP|NR|NW|OL|OX|PA|PE|PH|PL|PO|PR|RG|RH|RM|S|SA|SE|SG|SK|SL|SM|SN|SO|SP|SR|SS|ST|SW|SY|TA|TD|TF|TN|TQ|TR|TS|TW|UB|W|WA|WC|WD|WF|WN|WR|WS|WV|YO|ZE)(\d[\dA-Z]?[ ]?\d[ABD-HJLN-UW-Z]{2}))|BFPO[ ]?\d{1,4}$'
# => 0
'^.*$'
# => 0
我并不会说明哪种模式是最好的,以过滤掉无效的邮政编码为例。
这里大部分答案并不能适用于我数据库中的所有邮政编码。最终我找到了一个可以验证所有邮编的新正则表达式,该正则表达式由政府提供:
由于它不在以前的答案中,所以我在这里发布链接,以防他们删除:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
更新:根据Jamie Bull指出的修改了正则表达式。不确定是我复制时的错误还是政府的正则表达式有误,链接现在无法访问...
更新:如ctwheels所发现,该正则表达式适用于javascript正则表达式语法。请参考他的评论中适用于pcre(php)语法的一个。
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$应该是^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$- 发现区别;-) - Jamie Bull([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) ?[0-9][A-Za-z]{2})(已删除^和$并在空格后添加了一个?)以便http://www.regexr.com/可以找到多个结果,并且对于两个查询,可以找到没有空格分隔符的结果。 - mythofechelon(?:) 中,然后再放置锚定点。在这里可以看到它失败了:https://regex101.com/r/KleL5c/1。更多信息请参见我的答案:https://dev59.com/Mq3la4cB1Zd3GeqPPp5i#51828886。^(?:([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2}))$ 是已校正的正则表达式。 - ctwheels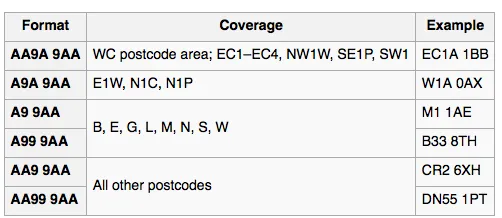 这种模式涵盖了所有情况。
这种模式涵盖了所有情况。(?:[A-Za-z]\d ?\d[A-Za-z]{2})|(?:[A-Za-z][A-Za-z\d]\d ?\d[A-Za-z]{2})|(?:[A-Za-z]{2}\d{2} ?\d[A-Za-z]{2})|(?:[A-Za-z]\d[A-Za-z] ?\d[A-Za-z]{2})|(?:[A-Za-z]{2}\d[A-Za-z] ?\d[A-Za-z]{2})
当在Android\Java上使用时,请使用 \\d
这是Google在他们的i18napis.appspot.com域上提供的正则表达式:
GIR[ ]?0AA|((AB|AL|B|BA|BB|BD|BH|BL|BN|BR|BS|BT|BX|CA|CB|CF|CH|CM|CO|CR|CT|CV|CW|DA|DD|DE|DG|DH|DL|DN|DT|DY|E|EC|EH|EN|EX|FK|FY|G|GL|GY|GU|HA|HD|HG|HP|HR|HS|HU|HX|IG|IM|IP|IV|JE|KA|KT|KW|KY|L|LA|LD|LE|LL|LN|LS|LU|M|ME|MK|ML|N|NE|NG|NN|NP|NR|NW|OL|OX|PA|PE|PH|PL|PO|PR|RG|RH|RM|S|SA|SE|SG|SK|SL|SM|SN|SO|SP|SR|SS|ST|SW|SY|TA|TD|TF|TN|TQ|TR|TS|TW|UB|W|WA|WC|WD|WF|WN|WR|WS|WV|YO|ZE)(\d[\dA-Z]?[ ]?\d[ABD-HJLN-UW-Z]{2}))|BFPO[ ]?\d{1,4}
这是一篇老文章,但在谷歌搜索结果中排名仍然很高,所以我想更新一下。该文档定义了英国邮编正则表达式:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([**AZ**a-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
来源:
该文件还解释了其背后的逻辑。然而,它存在一个错误(加粗),并且允许使用小写字母,虽然是合法的,但不太常见,因此修订版本如下:
^(GIR 0AA)|((([A-Z][0-9]{1,2})|(([A-Z][A-HJ-Y][0-9]{1,2})|(([A-Z][0-9][A-Z])|([A-Z][A-HJ-Y][0-9]?[A-Z])))) [0-9][A-Z]{2})$
这适用于新的伦敦邮政编码(例如W1D 5LH),而先前的版本则不适用。
(?:) 中,然后再放置锚定点。在这里可以看到它失败了:https://regex101.com/r/KleL5c/1。更多信息请参见我的答案:https://dev59.com/Mq3la4cB1Zd3GeqPPp5i#51828886。^(?:([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2}))$ 是已校正的正则表达式。 - ctwheels