我知道有两个内存区域: 栈 和 堆。
我也知道如果你创建一个局部变量,它会存在于栈中,而不是堆中。栈会随着我们向其中推入数据而增长,就像这样:
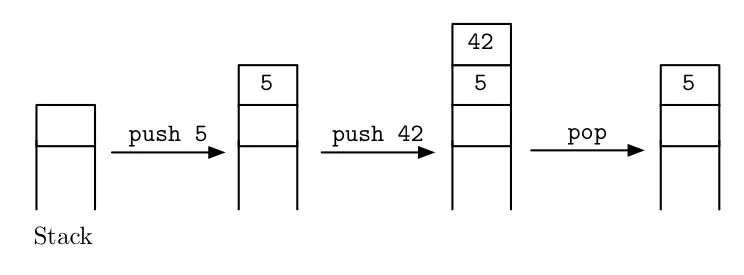
现在我将尝试把我感到困惑的事情传达给你:
例如,这段简单的Java代码:
public class TestClass {
public static void main(String[] args) {
Object foo = null;
Object bar = null;
}
}
被翻译成这个字节码:
public static void main(java.lang.String[]);
Code:
Stack=1, Locals=3, Args_size=1
0: aconst_null
1: astore_1
2: aconst_null
3: astore_2
4: return
LineNumberTable:
line 5: 0
line 6: 2
line 7: 4
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 args [Ljava/lang/String;
2 3 1 foo Ljava/lang/Object;
4 1 2 bar Ljava/lang/Object;
根据定义,acons_null 是:
push a null reference onto the stack
而 astore_1 是:
store a reference into local variable 1