我在Python中有两个列表:
temp1 = ['One', 'Two', 'Three', 'Four']
temp2 = ['One', 'Two']
假设每个列表中的元素都是唯一的,我希望创建第三个列表,其中包含第一个列表中不在第二个列表中的项目:
假设每个列表中的元素都是唯一的,我想要创建一个新的列表,其中包含来自第一个列表的但不在第二个列表中的项目:
temp3 = ['Three', 'Four']
有没有不需要循环和检查的快速方式?
我在Python中有两个列表:
temp1 = ['One', 'Two', 'Three', 'Four']
temp2 = ['One', 'Two']
假设每个列表中的元素都是唯一的,我希望创建第三个列表,其中包含第一个列表中不在第二个列表中的项目:
假设每个列表中的元素都是唯一的,我想要创建一个新的列表,其中包含来自第一个列表的但不在第二个列表中的项目:
temp3 = ['Three', 'Four']
有没有不需要循环和检查的快速方式?
要获取在temp1中但不在temp2中的元素(假设每个列表中的元素都是唯一的):
In [5]: list(set(temp1) - set(temp2))
Out[5]: ['Four', 'Three']
请注意这是不对称的:
In [5]: set([1, 2]) - set([2, 3])
Out[5]: set([1])
你可能期望或希望它等于set([1, 3])。如果你确实想要set([1, 3])作为你的答案,你可以使用set([1, 2]).symmetric_difference(set([2, 3]))。
list(set(temp1) - set(temp2)) == ['Four', 'Three'] 或者 list(set(temp1) - set(temp2)) == ['Three', 'Four']。 - Arthura=[1, 1, 1, 1, 2, 2],b=[1, 1, 2, 2]。 - Shark Deng现有的解决方案要么具有比O(n*m)更快的性能,要么保留输入列表的顺序。
s = set(temp2)
temp3 = [x for x in temp1 if x not in s]
性能测试
import timeit
init = 'temp1 = list(range(100)); temp2 = [i * 2 for i in range(50)]'
print timeit.timeit('list(set(temp1) - set(temp2))', init, number = 100000)
print timeit.timeit('s = set(temp2);[x for x in temp1 if x not in s]', init, number = 100000)
print timeit.timeit('[item for item in temp1 if item not in temp2]', init, number = 100000)
结果:
4.34620224079 # ars' answer
4.2770634955 # This answer
30.7715615392 # matt b's answer
我提供的这种方法不仅可以保持顺序,而且比集合减法略快,因为它不需要构建一个不必要的集合。如果第一个列表比第二个列表长得多并且哈希很昂贵,性能差异将更加明显。以下是第二个演示此点的测试:
init = '''
temp1 = [str(i) for i in range(100000)]
temp2 = [str(i * 2) for i in range(50)]
'''
结果:
11.3836875916 # ars' answer
3.63890368748 # this answer (3 times faster!)
37.7445402279 # matt b's answer
- earlonrailstemp1 = ['One', 'Two', 'Three', 'Four'] temp2 = ['One', 'Two', 'Six'] s = set(temp2) temp3 = [x for x in temp1 if x not in s] temp3 ['Three', 'Four']
可以使用Python的异或运算符来完成。
temp1与temp2之间的差异以及temp2与temp1之间的差异。set(temp1) ^ set(temp2)
temp2 添加一个在 temp1 中不存在的值,然后再试一次。 - urig你可以使用列表推导式:
temp3 = [item for item in temp1 if item not in temp2]
temp2转换为一个集合会使这个过程更有效率。 - user355252试试这个:
temp3 = set(temp1) - set(temp2)
如果您想递归地获得差异,我已经为Python编写了一个包: https://github.com/seperman/deepdiff
从PyPi安装:
pip install deepdiff
导入
>>> from deepdiff import DeepDiff
>>> from pprint import pprint
>>> from __future__ import print_function # In case running on Python 2
同一个对象返回空
>>> t1 = {1:1, 2:2, 3:3}
>>> t2 = t1
>>> print(DeepDiff(t1, t2))
{}
物品的类型已更改
>>> t1 = {1:1, 2:2, 3:3}
>>> t2 = {1:1, 2:"2", 3:3}
>>> pprint(DeepDiff(t1, t2), indent=2)
{ 'type_changes': { 'root[2]': { 'newtype': <class 'str'>,
'newvalue': '2',
'oldtype': <class 'int'>,
'oldvalue': 2}}}
某个项的值已经改变
>>> t1 = {1:1, 2:2, 3:3}
>>> t2 = {1:1, 2:4, 3:3}
>>> pprint(DeepDiff(t1, t2), indent=2)
{'values_changed': {'root[2]': {'newvalue': 4, 'oldvalue': 2}}}
添加和/或移除了项目
>>> t1 = {1:1, 2:2, 3:3, 4:4}
>>> t2 = {1:1, 2:4, 3:3, 5:5, 6:6}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff)
{'dic_item_added': ['root[5]', 'root[6]'],
'dic_item_removed': ['root[4]'],
'values_changed': {'root[2]': {'newvalue': 4, 'oldvalue': 2}}}
字符串差异
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":"world"}}
>>> t2 = {1:1, 2:4, 3:3, 4:{"a":"hello", "b":"world!"}}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff, indent = 2)
{ 'values_changed': { 'root[2]': {'newvalue': 4, 'oldvalue': 2},
"root[4]['b']": { 'newvalue': 'world!',
'oldvalue': 'world'}}}
字符串差异2
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":"world!\nGoodbye!\n1\n2\nEnd"}}
>>> t2 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":"world\n1\n2\nEnd"}}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff, indent = 2)
{ 'values_changed': { "root[4]['b']": { 'diff': '--- \n'
'+++ \n'
'@@ -1,5 +1,4 @@\n'
'-world!\n'
'-Goodbye!\n'
'+world\n'
' 1\n'
' 2\n'
' End',
'newvalue': 'world\n1\n2\nEnd',
'oldvalue': 'world!\n'
'Goodbye!\n'
'1\n'
'2\n'
'End'}}}
>>>
>>> print (ddiff['values_changed']["root[4]['b']"]["diff"])
---
+++
@@ -1,5 +1,4 @@
-world!
-Goodbye!
+world
1
2
End
类型转换
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2, 3]}}
>>> t2 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":"world\n\n\nEnd"}}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff, indent = 2)
{ 'type_changes': { "root[4]['b']": { 'newtype': <class 'str'>,
'newvalue': 'world\n\n\nEnd',
'oldtype': <class 'list'>,
'oldvalue': [1, 2, 3]}}}
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2, 3, 4]}}
>>> t2 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2]}}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff, indent = 2)
{'iterable_item_removed': {"root[4]['b'][2]": 3, "root[4]['b'][3]": 4}}
列表差异2:
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2, 3]}}
>>> t2 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 3, 2, 3]}}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff, indent = 2)
{ 'iterable_item_added': {"root[4]['b'][3]": 3},
'values_changed': { "root[4]['b'][1]": {'newvalue': 3, 'oldvalue': 2},
"root[4]['b'][2]": {'newvalue': 2, 'oldvalue': 3}}}
忽略顺序或重复项的列表差异:(与上面相同的字典)
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2, 3]}}
>>> t2 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 3, 2, 3]}}
>>> ddiff = DeepDiff(t1, t2, ignore_order=True)
>>> print (ddiff)
{}
包含字典的列表:
>>> t1 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2, {1:1, 2:2}]}}
>>> t2 = {1:1, 2:2, 3:3, 4:{"a":"hello", "b":[1, 2, {1:3}]}}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (ddiff, indent = 2)
{ 'dic_item_removed': ["root[4]['b'][2][2]"],
'values_changed': {"root[4]['b'][2][1]": {'newvalue': 3, 'oldvalue': 1}}}
集合:
>>> t1 = {1, 2, 8}
>>> t2 = {1, 2, 3, 5}
>>> ddiff = DeepDiff(t1, t2)
>>> pprint (DeepDiff(t1, t2))
{'set_item_added': ['root[3]', 'root[5]'], 'set_item_removed': ['root[8]']}
命名元组:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> t1 = Point(x=11, y=22)
>>> t2 = Point(x=11, y=23)
>>> pprint (DeepDiff(t1, t2))
{'values_changed': {'root.y': {'newvalue': 23, 'oldvalue': 22}}}
自定义对象:
>>> class ClassA(object):
... a = 1
... def __init__(self, b):
... self.b = b
...
>>> t1 = ClassA(1)
>>> t2 = ClassA(2)
>>>
>>> pprint(DeepDiff(t1, t2))
{'values_changed': {'root.b': {'newvalue': 2, 'oldvalue': 1}}}
新增了对象属性:
>>> t2.c = "new attribute"
>>> pprint(DeepDiff(t1, t2))
{'attribute_added': ['root.c'],
'values_changed': {'root.b': {'newvalue': 2, 'oldvalue': 1}}}
def diff(list1, list2):
c = set(list1).union(set(list2)) # or c = set(list1) | set(list2)
d = set(list1).intersection(set(list2)) # or d = set(list1) & set(list2)
return list(c - d)
或者
def diff(list1, list2):
return list(set(list1).symmetric_difference(set(list2))) # or return list(set(list1) ^ set(list2))
diff(temp2, temp1) 或 diff(temp1, temp2) 找到差异。两者都将给出结果 ['Four', 'Three']。您不必担心列表的顺序或应首先给出哪个列表。
最简单的方法是使用 set().difference(set())
list_a = [1,2,3]
list_b = [2,3]
print set(list_a).difference(set(list_b))
答案是 set([1])
可以打印成列表形式,
print list(set(list_a).difference(set(list_b)))
我也来发表一下意见,因为目前的解决方案都没有提供一个元组:
temp3 = tuple(set(temp1) - set(temp2))
或者说:
#edited using @Mark Byers idea. If you accept this one as answer, just accept his instead.
temp3 = tuple(x for x in temp1 if x not in set(temp2))
像其他在这个方向上没有元组产生的答案一样,它保留顺序
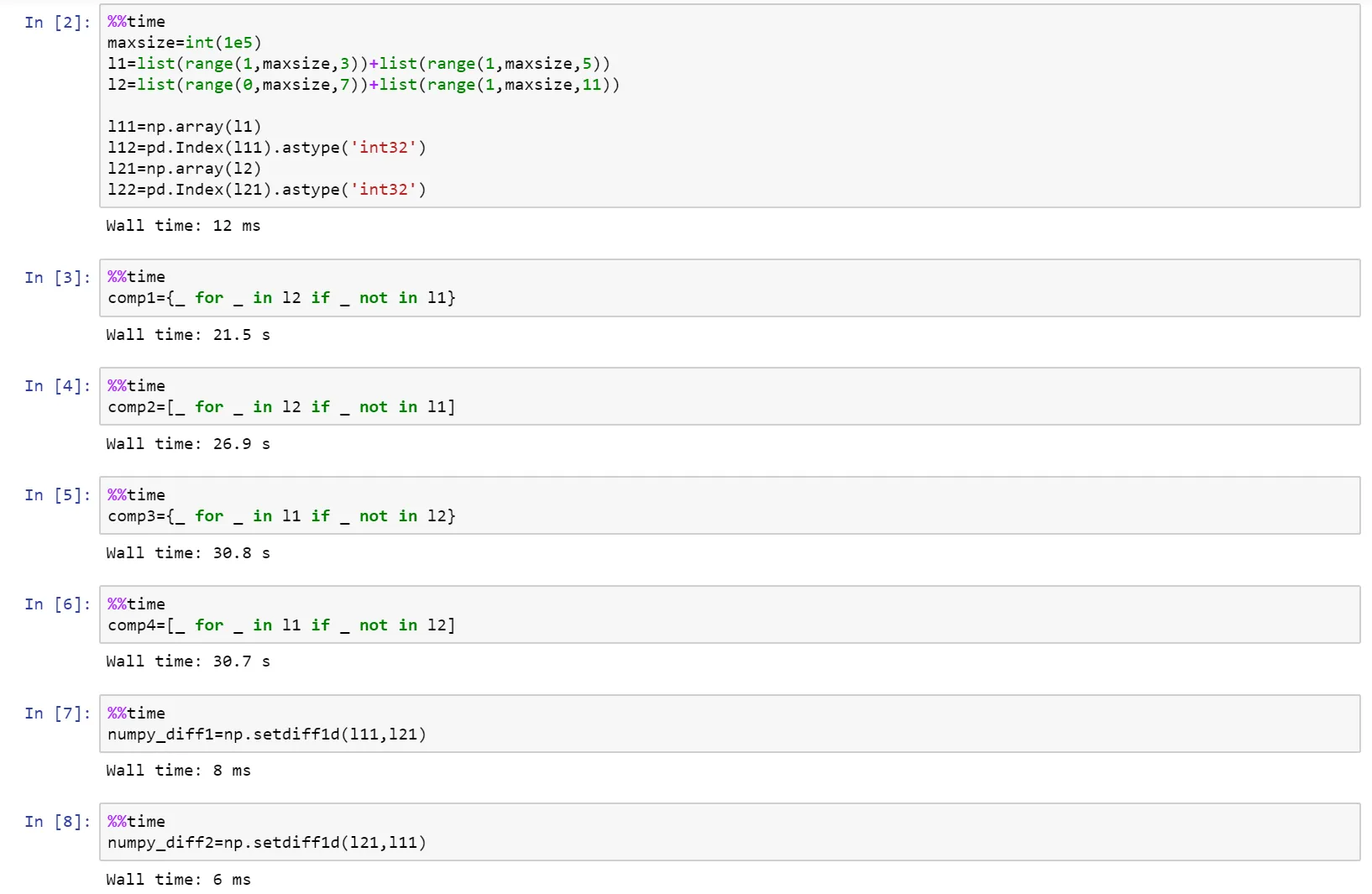
如果你真的在追求性能,那么请使用numpy!
这里有一个完整的笔记本作为 gist 放在了 Github 上,其中包含了列表、numpy和pandas之间的比较。
https://gist.github.com/denfromufa/2821ff59b02e9482be15d27f2bbd4451
temp1 = ['One', 'One', 'One']和temp2 = ['One'],你希望得到['One', 'One']还是[]? - Michael Mrozek