我有一个关于故障时间的数据集。故障的开始在“Begin”列,结束在“End”列。
此外,还有3个故障类别,它们在时间上也可能重叠。
我的实际目标是计算每天没有故障的时间段的总和。(实际上,类别并不重要,我不需要对类别进行细分)。
为了更好地说明,以下是一个关于故障时间跨越3天的示例数据集:
我现在尝试以图形方式可视化故障时间: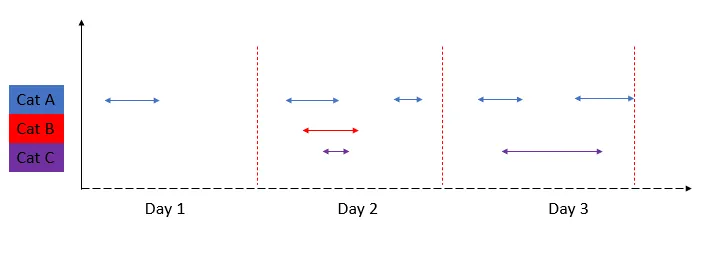 现在我想计算每个日历日的摘要,显示没有发生任何故障的分钟数(或小时数或秒数)。
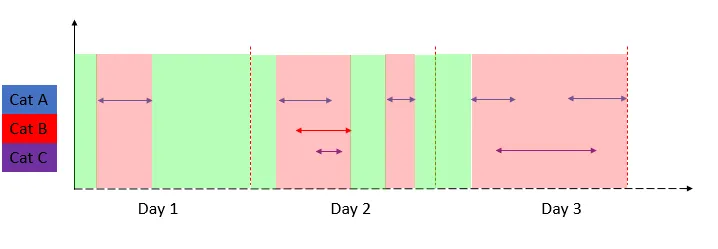
这是每天所有绿色时间间隔的总和:
现在我想计算每个日历日的摘要,显示没有发生任何故障的分钟数(或小时数或秒数)。
这是每天所有绿色时间间隔的总和:
 如果只有一个故障类别,可以简单地计算24小时减去故障间隔。
然而,我在处理不同重叠的故障间隔时无法进一步。
有人能帮我计算无故障期间和/或每日故障期间吗?
如果只有一个故障类别,可以简单地计算24小时减去故障间隔。
然而,我在处理不同重叠的故障间隔时无法进一步。
有人能帮我计算无故障期间和/或每日故障期间吗?
我想象中的评估可能是这样的:(结果可能与上面的示例数据集不完全相同)
以下是创建示例数据框的代码:
此外,还有3个故障类别,它们在时间上也可能重叠。
我的实际目标是计算每天没有故障的时间段的总和。(实际上,类别并不重要,我不需要对类别进行细分)。
为了更好地说明,以下是一个关于故障时间跨越3天的示例数据集:
> df_time
# A tibble: 8 × 3
Category Begin End
<chr> <dttm> <dttm>
1 A 2023-07-15 01:40:11 2023-07-15 13:43:15
2 A 2023-07-16 05:54:44 2023-07-16 10:50:45
3 B 2023-08-16 07:43:09 2023-08-16 16:42:12
4 C 2023-08-16 12:00:00 2023-08-16 13:11:13
5 A 2023-08-16 18:00:00 2023-08-16 19:30:00
6 A 2023-08-17 08:00:00 2023-08-17 13:00:00
7 C 2023-08-17 11:12:45 2023-08-17 19:58:22
8 A 2023-08-17 19:01:45 2023-08-17 23:59:59
我现在尝试以图形方式可视化故障时间:
现在我想计算每个日历日的摘要,显示没有发生任何故障的分钟数(或小时数或秒数)。
这是每天所有绿色时间间隔的总和:
如果只有一个故障类别,可以简单地计算24小时减去故障间隔。
然而,我在处理不同重叠的故障间隔时无法进一步。
有人能帮我计算无故障期间和/或每日故障期间吗?我想象中的评估可能是这样的:(结果可能与上面的示例数据集不完全相同)
Date OK_times malfunction_times
<date> <chr> <chr>
1 2023-07-15 17 hours 7 hours
2 2023-07-16 5 Hours 19 hours
3 2023-07-17 3 hours 21 hours
以下是创建示例数据框的代码:
library(tidyverse)
df_time <- tibble(
Category = c("A", "A", "B", "C", "A", "A", "C", "A"),
Begin = as_datetime(c(
"2023-07-15 01:40:11",
"2023-07-16 05:54:44",
"2023-08-16 07:43:09",
"2023-08-16 12:00:00",
"2023-08-16 18:00:00",
"2023-08-17 08:00:00",
"2023-08-17 11:12:45",
"2023-08-17 19:01:45"
)),
End = as_datetime(c(
"2023-07-15 13:43:15",
"2023-07-16 10:50:45",
"2023-08-16 16:42:12",
"2023-08-16 13:11:13",
"2023-08-16 19:30:00",
"2023-08-17 13:00:00",
"2023-08-17 19:58:22",
"2023-08-17 23:59:59"
))
)