更新:在文末添加了比较和基准测试。
这里有另一种方法,基于完美哈希。使用gperf生成了完美哈希(就像这里描述的那样:是否可能比使用哈希映射更快地将字符串映射到整数?)。
我进一步优化了代码,将函数局部静态变量挪到了一边,并将hexdigit()和hash()标记为constexpr。这消除了任何不必要的初始化开销,让编译器有充分的优化空间。
我不指望能比这个还要更快。
如果可能的话,您可以尝试每次读取1024个半字节,并给编译器一个使用AVX/SSE指令集矢量化操作的机会。(我没有检查生成的代码是否会发生这种情况。)
将std::cin转换为流模式的std::cout的完整示例代码如下:
#include <iostream>
int main()
{
char buffer[4096];
while (std::cin.read(buffer, sizeof(buffer)), std::cin.gcount())
{
size_t got = std::cin.gcount();
char* out = buffer;
for (auto it = buffer; it < buffer+got; it += 4)
*out++ = Perfect_Hash::hexchar(it);
std::cout.write(buffer, got/4);
}
}
这里是Perfect_Hash类,稍加编辑并扩展了hexchar查找。请注意,在DEBUG构建中,它使用assert验证输入:
在Coliru上实时运行
#include <array>
#include <algorithm>
#include <cassert>
class Perfect_Hash {
private:
static constexpr unsigned char asso_values[] = {
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 15, 7, 3, 1, 0, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27};
template <typename It>
static constexpr unsigned int hash(It str)
{
return
asso_values[(unsigned char)str[3] + 2] + asso_values[(unsigned char)str[2] + 1] +
asso_values[(unsigned char)str[1] + 3] + asso_values[(unsigned char)str[0]];
}
static constexpr char hex_lut[] = "???????????fbead9c873625140";
public:
#ifdef DEBUG
template <typename It>
static char hexchar(It binary_nibble)
{
assert(Perfect_Hash::validate(binary_nibble));
return hex_lut[hash(binary_nibble)];
}
#else
template <typename It>
static constexpr char hexchar(It binary_nibble)
{
return hex_lut[hash(binary_nibble)];
}
#endif
template <typename It>
static bool validate(It str)
{
static constexpr std::array<char, 4> vocab[] = {
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'1', '1', '1', '1'}}, {{'1', '0', '1', '1'}},
{{'1', '1', '1', '0'}}, {{'1', '0', '1', '0'}},
{{'1', '1', '0', '1'}}, {{'1', '0', '0', '1'}},
{{'1', '1', '0', '0'}}, {{'1', '0', '0', '0'}},
{{'0', '1', '1', '1'}}, {{'0', '0', '1', '1'}},
{{'0', '1', '1', '0'}}, {{'0', '0', '1', '0'}},
{{'0', '1', '0', '1'}}, {{'0', '0', '0', '1'}},
{{'0', '1', '0', '0'}}, {{'0', '0', '0', '0'}},
};
int key = hash(str);
if (key <= 26 && key >= 0)
return std::equal(str, str+4, vocab[key].begin());
else
return false;
}
};
constexpr unsigned char Perfect_Hash::asso_values[];
constexpr char Perfect_Hash::hex_lut[];
#include <iostream>
int main()
{
char buffer[4096];
while (std::cin.read(buffer, sizeof(buffer)), std::cin.gcount())
{
size_t got = std::cin.gcount();
char* out = buffer;
for (auto it = buffer; it < buffer+got; it += 4)
*out++ = Perfect_Hash::hexchar(it);
std::cout.write(buffer, got/4);
}
}
例如,od -A none -t o /dev/urandom | tr -cd '01' | dd bs=1 count=4096 | ./test的演示输出结果如下:
03bef5fb79c7da917e3ebffdd8c41488d2b841dac86572cf7672d22f1f727627a2c4a48b15ef27eb0854dd99756b24c678e3b50022d695cc5f5c8aefaced2a39241bfd5deedcfa0a89060598c6b056d934719eba9ccf29e430d2def5751640ff17860dcb287df8a94089ade0283ee3d76b9fefcce3f3006b8c71399119423e780cef81e9752657e97c7629a9644be1e7c96b5d0324ab16d20902b55bb142c0451e675973489ae4891ec170663823f9c1c9b2a11fcb1c39452aff76120b21421069af337d14e89e48ee802b1cecd8d0886a9a0e90dea5437198d8d0d7ef59c46f9a069a83835286a9a8292d2d7adb4e7fb0ef42ad4734467063d181745aaa6694215af7430f95e854b7cad813efbbae0d2eb099523f215cff6d9c45e3edcaf63f78a485af8f2bfc2e27d46d61561b155d619450623b7aa8ca085c6eedfcc19209066033180d8ce1715e8ec9086a7c28df6e4202ee29705802f0c2872fbf06323366cf64ecfc5ea6f15ba6467730a8856a1c9ebf8cc188e889e783c50b85824803ed7d7505152b891cb2ac2d6f4d1329e100a2e3b2bdd50809b48f0024af1b5092b35779c863cd9c6b0b8e278f5bec966dd0e5c4756064cca010130acf24071d02de39ef8ba8bd1b6e9681066be3804d36ca83e7032274e4c8e8cacf520e8078f8fa80eb8e70af40367f53e53a7d7f7afe8704c46f58339d660b8151c91bddf82b4096
基准测试
我提出了三种不同的方法:
- naive.cpp(无hack,无库); 在Godbolt上进行实时反汇编
- spirit.cpp(Trie); 在pastebin上进行
实时反汇编
- 和这个答案:perfect.cpp哈希基础; 在Godbolt上进行实时反汇编
为了进行一些比较,我:
- 使用相同的编译器(GCC 4.9)和标志(
-O3 -march=native -g0 -DNDEBUG)对它们进行了编译
- 优化了输入/输出,使其不会每次读取4个字符/写入单个字符
- 创建了一个大的输入文件(1千兆字节)
以下是结果:
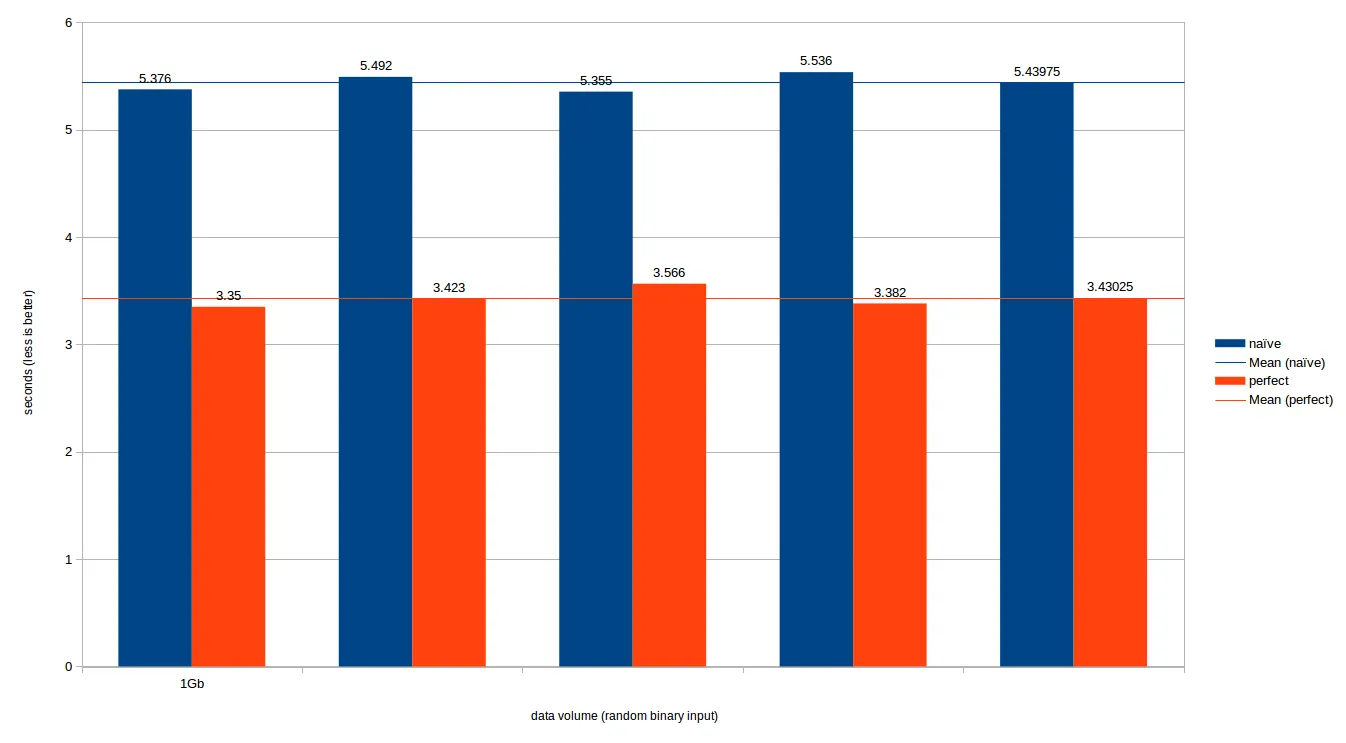
- 令人惊讶的是,第一个答案中的
naive方法表现得相当不错
- Spirit在这里表现非常差; 它的吞吐量为3.4MB/s,因此整个文件需要294秒(!!!)。我们已经将其从图表中删除了
- 平均吞吐量为naive.cpp约为720MB/s,而perfect.cpp约为1.14GB/s
- 这使得完美哈希方法比朴素方法快大约50%。
*摘要我会说朴素方法足够好如我10小时前发布的那样。如果您真的想要高吞吐量,则完美哈希是一个不错的开始,但请考虑手动编写基于SIMD的解决方案
uint32_t *,然后您可以一次比较32位。比玩弄字符串和字符要快得多。 - Andy Brown