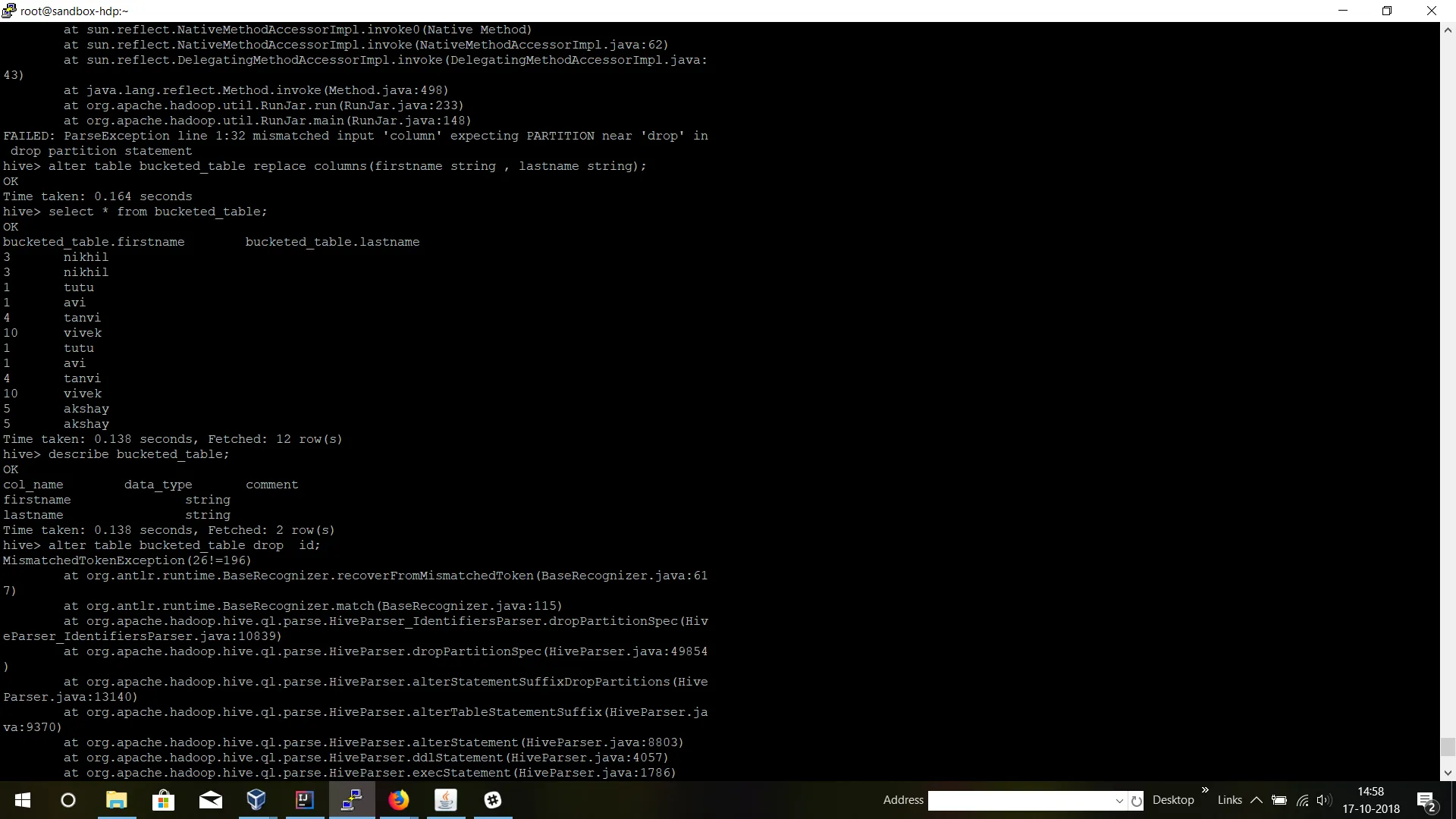
我有一个如下所示的Hive表:
create table alpha001(id int, name string) clustered by (id) into 2 buckets stored as orc TBLPROPERTIES ('transactional'='true')
我想要删除其中一列,比如“name”列。我尝试了以下方法:
ALTER TABLE alpha001 REPLACE COLUMNS (id int);
这将导致以下结果。
Exception thrown: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Replace columns is not supported for table default.alpha001. SerDe may be incompatible.
并且以下
ALTER TABLE alpha001 DROP name;
Exception thrown : FAILED: ParseException line 1:26 mismatched input 'name' expecting PARTITION near 'DROP' in drop partition statement