如果数据被建模为键值对(
Table_LKP_AlertMastInfo中的键值对和
Table_RegistrationInfo中的列),那么如果没有动态SQL,这将是不可能的。因此,既然我们已经处理完了这个问题,那么让我们开始吧。提供确切结果的存储过程的完整代码将在文末附上,接下来我会解释它的作用。
因为警报是指定为键值对(字段名-字段值),所以我们首先需要以相同的格式获取候选数据。如果我们可以得到字段列表,
UNPIVOT就可以轻松解决这个问题。如果我们只有你在问题中提到的两个字段,那么这将非常容易,例如:
SELECT CandidateId, DistrictID
, FieldName
, FieldValue
FROM Table_RegistrationInfo t
UNPIVOT (FieldValue FOR FieldName IN (AreYouMarried, Gender)) upvt
当然不是这种情况,因此我们需要动态选择我们感兴趣的字段列表并提供它。由于您使用的是2008 R2版本,
STRING_AGG函数不可用,所以我们将
使用XML技巧将所有字段聚合成一个字符串并将其提供给上面的查询。
DECLARE @sql NVARCHAR(MAX)
SELECT @sql = CONCAT('SELECT CandidateId, DistrictID
, FieldName
, FieldValue
FROM Table_RegistrationInfo t
UNPIVOT (FieldValue FOR FieldName IN (',
STUFF((
SELECT DISTINCT ',' + ami.FieldName
FROM Table_LKP_AlertMastInfo ami
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1, ''), ')) upvt')
PRINT @sql
这几乎产生了我所写查询的完全输出。接下来,我们需要将这些数据存储在某处。临时表来拯救。让我们创建一个临时表,并使用此动态SQL插入其中。
CREATE TABLE #candidateFields
(
CandidateID VARCHAR(50),
DistrictID INT,
FieldName NVARCHAR(200),
FieldValue NVARCHAR(1000)
);
INSERT INTO #candidateFields
EXEC sp_executesql @sql
CREATE UNIQUE CLUSTERED INDEX uxc#candidateFields on #candidateFields
(
CandidateId, DistrictId, FieldName, FieldValue
);
好的,现在我们已经把警报数据和候选数据都以相同的格式准备好了。接下来的重点是将它们进行连接,以便找到两者之间的匹配项:
SELECT cf.CandidateID, COUNT(*) AS matches
FROM #candidateFields cf
INNER
JOIN Table_LKP_AlertMastInfo alerts
ON alerts.DistrictID = cf.DistrictID
AND alerts.FieldName = cf.FieldName
AND alerts.AlertOptionValue = cf.FieldValue
GROUP BY cf.CandidateID
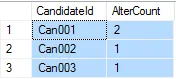
为样本数据提供所需的输出:
CandidateID 匹配次数
-------------------------------------------------- -----------
Can001 2
Can002 1
Can003 1
(3 行受影响)
现在我们可以将所有内容拼合在一起,形成可重用的存储过程:
CREATE PROCEDURE dbo.findMatches
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX)
SELECT @sql = CONCAT('SELECT CandidateId, DistrictID
, FieldName
, FieldValue
FROM Table_RegistrationInfo t
UNPIVOT (FieldValue FOR FieldName IN (',
STUFF((
SELECT DISTINCT ',' + ami.FieldName
FROM Table_LKP_AlertMastInfo ami
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1, ''), ')) upvt')
CREATE TABLE #candidateFields
(
CandidateID VARCHAR(50),
DistrictID INT,
FieldName NVARCHAR(200),
FieldValue NVARCHAR(1000)
);
INSERT INTO #candidateFields
EXEC sp_executesql @sql
CREATE UNIQUE CLUSTERED INDEX uxc#candidateFields on #candidateFields
(
CandidateId, DistrictId, FieldName
);
SELECT cf.CandidateID, COUNT(*) AS matches
FROM #candidateFields cf
JOIN Table_LKP_AlertMastInfo alerts
ON alerts.DistrictID = cf.DistrictID
AND alerts.FieldName = cf.FieldName
AND alerts.AlertOptionValue = cf.FieldValue
GROUP BY cf.CandidateID
END;
使用以下方式执行:
EXEC dbo.findMatches
当然,你需要调整类型,并在此处添加许多其他内容,例如错误处理,但这应该可以让你朝着正确的方向开始。您将需要在警报表上设置覆盖索引,即使有很多记录,它也应该非常快。