我正在与一位开发者合作,他正在开发一个分析路面图像以查找路面裂缝的程序。对于它找到的每个裂缝,它会在文件中生成一个条目,告诉我哪些像素组成了这个特定的裂缝。然而,他的软件存在两个问题:
1)它会产生几个错误报告
2)如果他找到了一个裂缝,他只能找到其中的一小部分,并将这些部分标记为单独的裂缝。
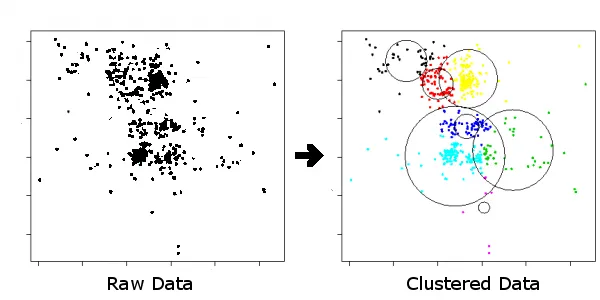
我的工作是编写软件来读取这些数据、分析它并区分假阳性和实际裂缝。我还需要确定如何将所有小段裂缝组合成一个裂缝。
我已经尝试了各种方法来过滤数据以消除假阳性,同时也在有限的程度上使用神经网络来组合裂缝。我知道会存在误差,但到目前为止,错误太多了。有没有人能给一个非AI专家的建议,告诉我完成任务的最佳方式或学习更多相关知识的书籍或课程类型?
编辑:我的问题更多的是关于如何注意同事数据中的模式,并将这些模式识别为实际的裂缝。我关心的是高级逻辑,而不是低级逻辑。
1)它会产生几个错误报告
2)如果他找到了一个裂缝,他只能找到其中的一小部分,并将这些部分标记为单独的裂缝。
我的工作是编写软件来读取这些数据、分析它并区分假阳性和实际裂缝。我还需要确定如何将所有小段裂缝组合成一个裂缝。
我已经尝试了各种方法来过滤数据以消除假阳性,同时也在有限的程度上使用神经网络来组合裂缝。我知道会存在误差,但到目前为止,错误太多了。有没有人能给一个非AI专家的建议,告诉我完成任务的最佳方式或学习更多相关知识的书籍或课程类型?
编辑:我的问题更多的是关于如何注意同事数据中的模式,并将这些模式识别为实际的裂缝。我关心的是高级逻辑,而不是低级逻辑。
编辑实际上,要准确地展示我的数据需要至少20张样本图片。由于数据变化较大,但我这里有一些样本在此、在这里和在这里。这些图片已经通过我的同事的处理过程进行了处理。红色、蓝色和绿色数据是我需要分类的(红色代表深裂缝,蓝色代表浅裂缝,绿色代表宽/密封裂缝)。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}