在Solr(3.3)中,是否可以通过使用EdgeNGramFilterFactory使字段逐字搜索,并且对短语查询敏感?
例如,我正在寻找一个字段,如果包含“contrat informatique”,则用户输入以下内容时将找到该字段:
- contrat - informatique - contr - informa - “contrat informatique” - “contrat info”
目前,我做了类似于这样的事情:
例如,我正在寻找一个字段,如果包含“contrat informatique”,则用户输入以下内容时将找到该字段:
- contrat - informatique - contr - informa - “contrat informatique” - “contrat info”
目前,我做了类似于这样的事情:
<fieldtype name="terms" class="solr.TextField">
<analyzer type="index">
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
</fieldtype>
...但是它在短语查询上失败了。
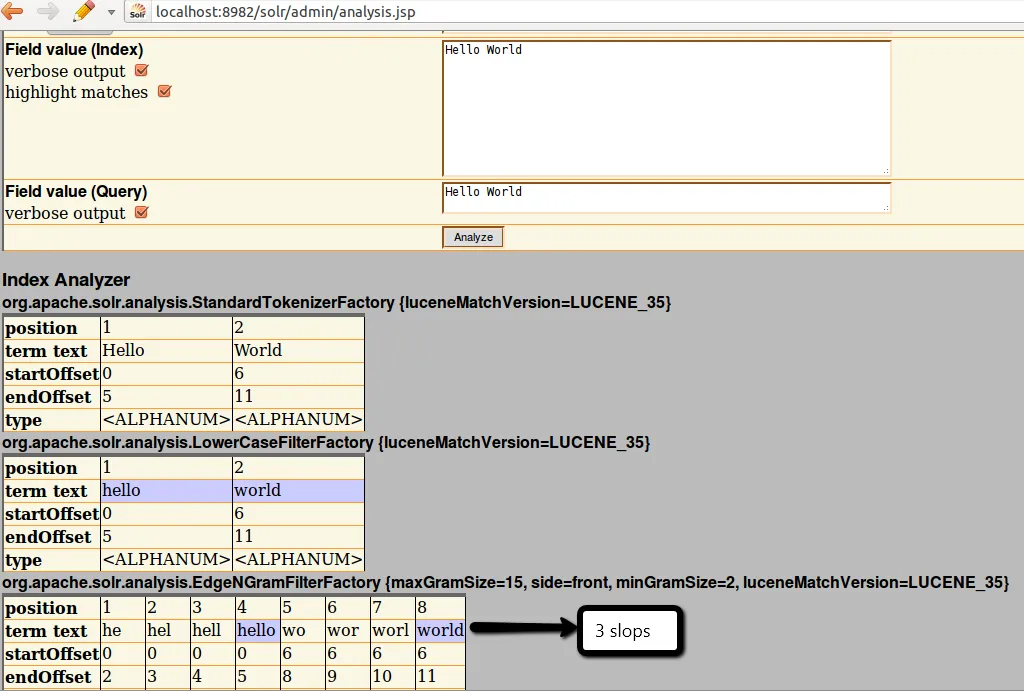
当我在solr管理页面的模式分析器中查看时,发现"contrat informatique"生成了以下令牌:
[...] contr contra contrat in inf info infor inform [...]
因此,“contrat in”(连续标记)可以与查询一起使用,但“contrat inf”不行(因为这两个标记是分开的)。
我相信任何类型的词干处理都可以与短语查询一起使用,但在使用EdgeNGramFilterFactory之前,我找不到正确的标记器或过滤器。