我一直在尝试学习有关Python的multiprocessing模块,并评估进程间通信的不同技术。我编写了一个基准测试,比较了Pipe、Queue和Array(都来自multiprocessing)在进程之间传输numpy数组的性能。完整的基准测试可以在这里找到。这是一个关于Queue的测试代码片段:
def process_with_queue(input_queue, output_queue):
source = input_queue.get()
dest = source**2
output_queue.put(dest)
def test_with_queue(size):
source = np.random.random(size)
input_queue = Queue()
output_queue = Queue()
p = Process(target=process_with_queue, args=(input_queue, output_queue))
start = timer()
p.start()
input_queue.put(source)
result = output_queue.get()
end = timer()
np.testing.assert_allclose(source**2, result)
return end - start
我在我的Linux笔记本上运行了这个测试,并得到了数组大小为1000000时的以下结果:
Using mp.Array: time for 20 iters: total=2.4869s, avg=0.12435s
Using mp.Queue: time for 20 iters: total=0.6583s, avg=0.032915s
Using mp.Pipe: time for 20 iters: total=0.63691s, avg=0.031845s
看到Array的表现如此糟糕,我有些惊讶,因为它使用共享内存,理论上不需要进行pickling,但我认为在numpy中可能存在一些我无法控制的复制。
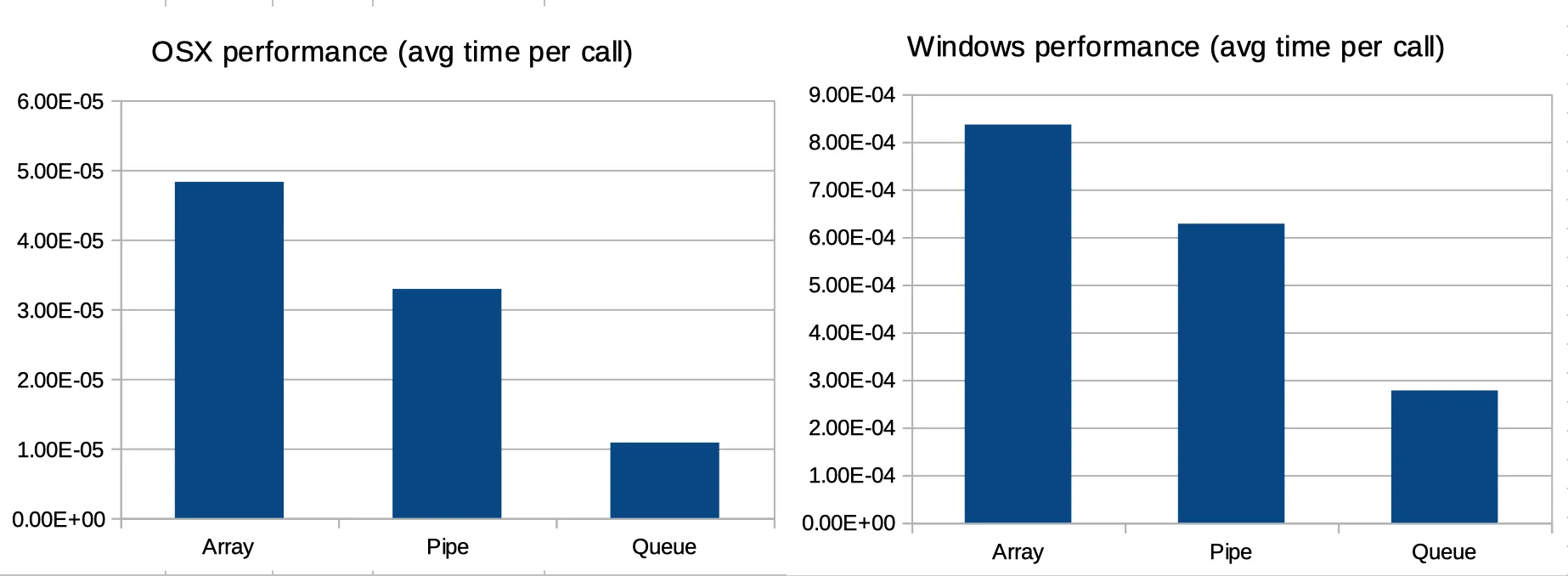
然而,我在Macbook上运行了相同的测试(数组大小仍为1000000),得到了以下结果:
Using mp.Array: time for 20 iters: total=1.6917s, avg=0.084587s
Using mp.Queue: time for 20 iters: total=2.3478s, avg=0.11739s
Using mp.Pipe: time for 20 iters: total=8.7709s, avg=0.43855s
实际的时间差异并不令人惊讶,因为不同的系统表现出不同的性能。真正令人惊讶的是相对时间的差异。
这是什么原因造成的?对我来说,这是一个非常令人惊讶的结果。我不会对Linux和Windows之间,或OSX和Windows之间的显著差异感到惊讶,但我认为在OSX和Linux之间,它们的行为应该非常相似。
这个问题涉及到Windows和OSX之间的性能差异,这似乎更容易理解。
Value和Array类型依赖于Lock来确保数据安全。获取锁是一项相当昂贵的操作,因为它需要切换到内核模式。另一方面,序列化简单数据结构是现代CPU大部分时间所做的事情,因此其成本相当低。从Array中删除Lock应该会显示更好的性能,但您不能排除数据上的竞争条件。 - noxdafoxArray部分使用锁。即使如此,在Linux上相对性能较差的Array只能解释一部分,但并不一定能解释Linux和OSX之间的差异。 - ddavella