现代数据库提供缓存支持。大多数ORM框架也会缓存检索到的数据。为什么需要这种重复的操作呢?
如果数据库已经提供缓存,为什么要使用应用级缓存?
31
- vbezhenar
1
一些相关链接:http://docs.jboss.org/hibernate/stable/core/reference/en/html/performance.html#performance-cache还有:http://www.javalobby.org/java/forums/t48846.html - chickeninabiscuit
9个回答
46
因为要从数据库的缓存中获取数据,您仍然需要执行以下操作:
- 从ORM的“本机”查询格式生成SQL
- 与数据库服务器进行网络往返
- 解析SQL
- 从缓存获取数据
- 将数据序列化为数据库的通过网络传输的格式
- 将数据反序列化为数据库客户端库的格式
- 将数据库客户端库的格式转换为语言级别的对象(即各种集合)
通过在应用程序级别进行缓存,您不需要执行上述任何操作。通常,这只是在内存哈希表中进行简单查找。有时(如果使用memcache进行缓存),仍然存在网络往返,但此时不再发生所有其他操作。
- Dean Harding
13
以下是您可能需要这样做的原因:
- 应用程序只缓存所需内容,因此缓存命中率应更高
- 由于网络延迟,即使使用快速网络,访问本地缓存也可能比访问数据库快几个数量级。
- Robert Christie
13
使用强一致性缓存扩展读写事务的规模
然而,这对于主节点并不起作用,因为它只能进行垂直扩展:
这就是缓存发挥作用的地方。对于需要在主节点上执行的读写数据库事务,缓存可以帮助您将查询负载减少,并将其定向到一个强一致性缓存,例如Hibernate二级缓存:
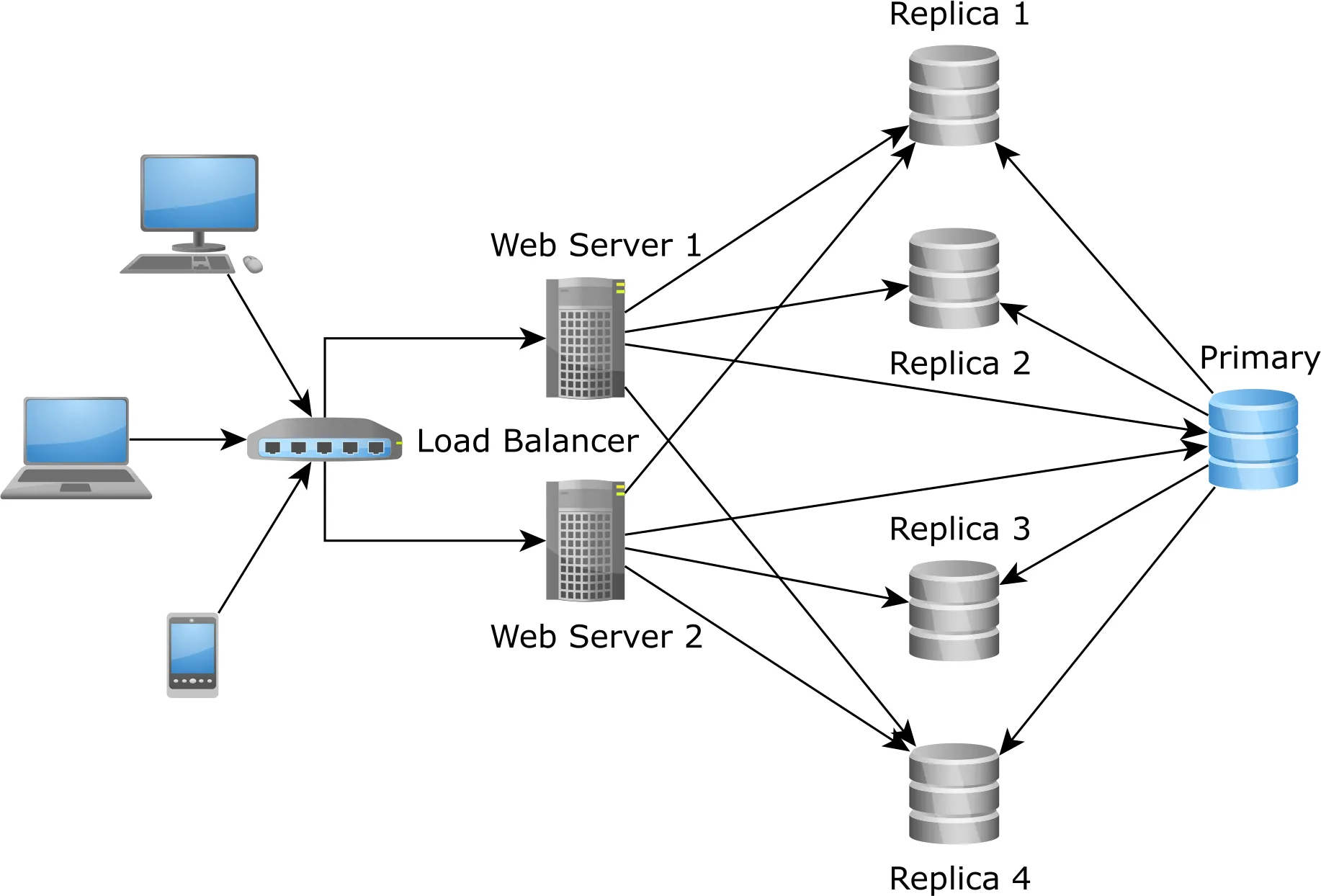
使用分布式缓存
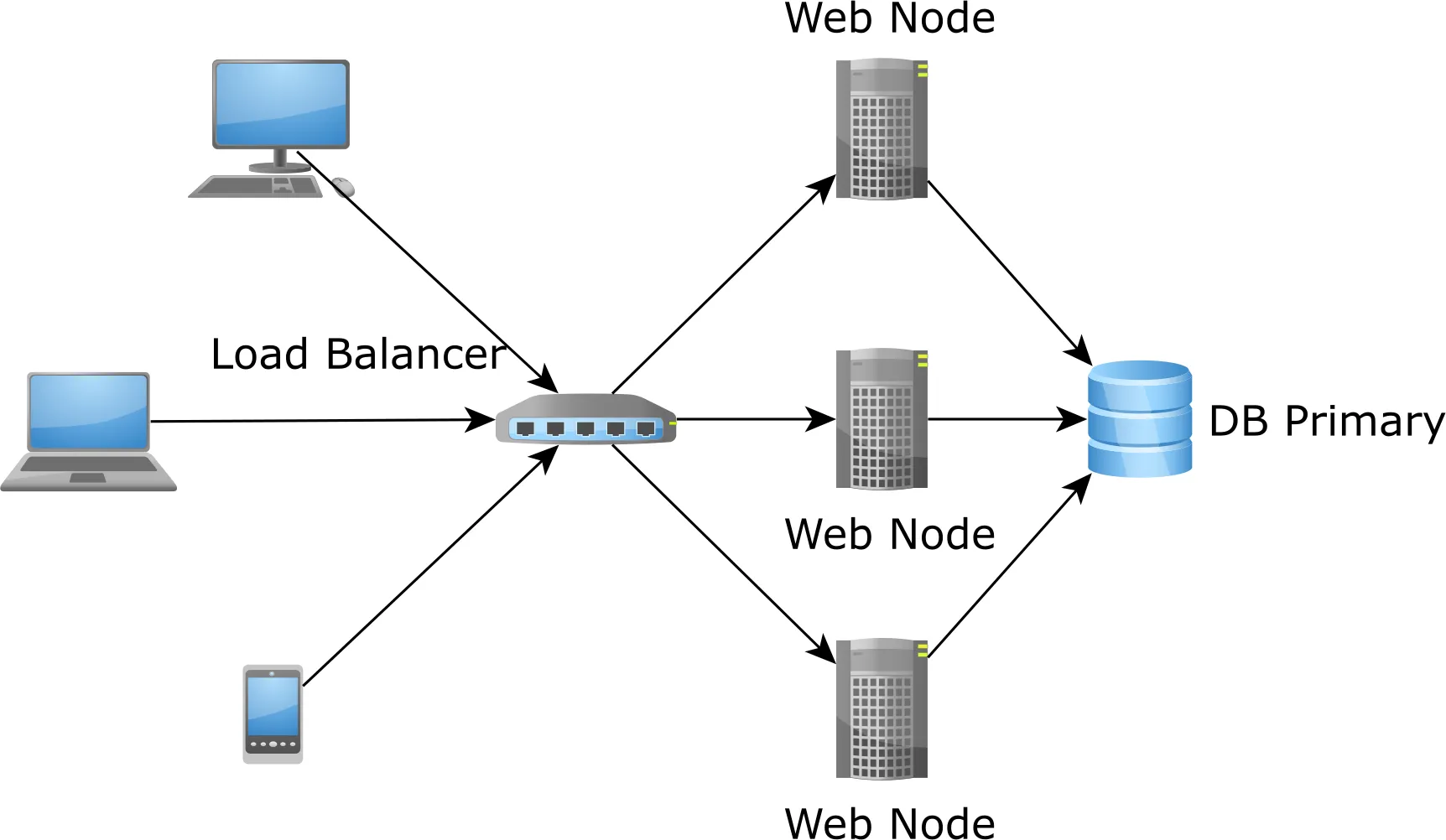
将应用程序级别的缓存存储在应用程序的内存中存在几个问题。
首先,应用程序内存有限,因此可以缓存的数据量也有限。
其次,当流量增加并且我们想要启动新的应用程序节点来处理额外的流量时,新节点将以冷缓存启动,使问题变得更糟,因为它们会导致数据库负载激增,直到缓存填充了数据为止:
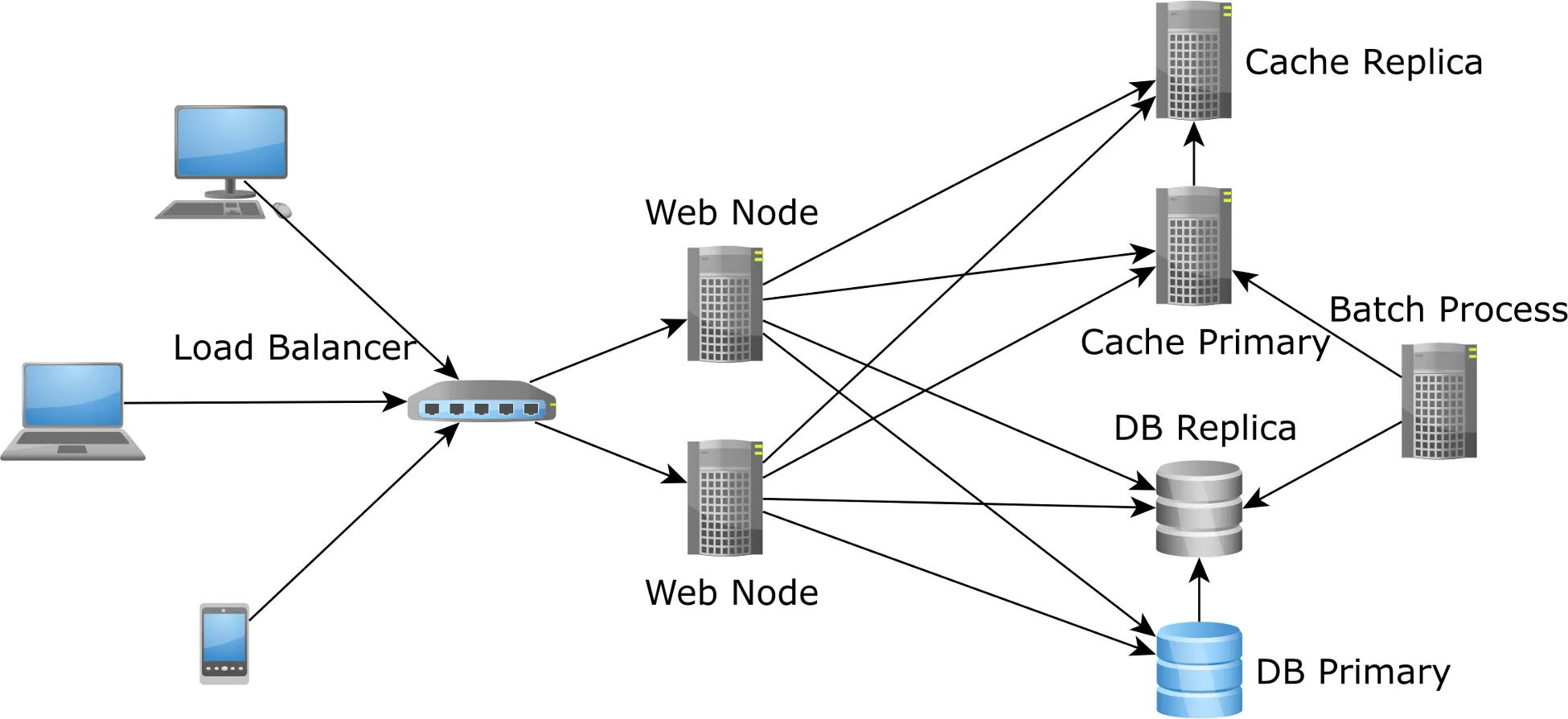
当自动扩展程序添加新的应用节点时,新节点将从同一分布式缓存中加载数据。因此,不再存在冷缓存问题。
- Vlad Mihalcea
1
1应用级缓存方面提出的观点是合理的顾虑,但并非不可克服的障碍。在Go语言中,有谷歌的“group-cache”(https://github.com/golang/groupcache),它可以相当优雅地解决其中的一些问题。这只是我的个人意见,希望能帮助大家了解当前可用/可实现的缓存选项。 - XDS
7
即使数据库引擎缓存了数据、索引或查询结果集,应用程序仍然需要通过往返到数据库来从该缓存中受益。
ORM框架运行在与应用程序相同的空间中。因此,没有往返交互,只是内存访问,这通常会更快。
框架还可以决定将数据保留在缓存中,只要它需要。数据库可能会在其他并发客户端请求利用缓存时,在不可预测的时间过期缓存数据。
您的应用程序侧ORM框架还可以以数据库无法返回的形式缓存数据。例如,作为Java对象集合而不是原始数据流。如果您依赖于数据库缓存,则ORM必须重复该转换成对象的过程,这增加了开销并减少了缓存的好处。
ORM框架运行在与应用程序相同的空间中。因此,没有往返交互,只是内存访问,这通常会更快。
框架还可以决定将数据保留在缓存中,只要它需要。数据库可能会在其他并发客户端请求利用缓存时,在不可预测的时间过期缓存数据。
您的应用程序侧ORM框架还可以以数据库无法返回的形式缓存数据。例如,作为Java对象集合而不是原始数据流。如果您依赖于数据库缓存,则ORM必须重复该转换成对象的过程,这增加了开销并减少了缓存的好处。
- Bill Karwin
6
此外,数据库的缓存可能并不像人们想象的那样实用。以下内容来自 http://highscalability.com/bunch-great-strategies-using-memcached-and-mysql-better-together,但它是针对MySQL特定的。
鉴于MySQL具有缓存功能,为什么还需要使用memcached?
MySQL缓存仅与一个实例相关联。这限制了缓存的最大地址为一个服务器的内存大小。如果您的系统比一个服务器的内存更大,则使用MySQL缓存将无法正常工作。如果从另一个实例读取相同的对象,则不会缓存。
查询缓存在写操作时会失效。当有人对其进行写入操作时,您建立的所有缓存都会消失。根据使用模式,您的缓存可能根本不是一个很好的缓存。
查询缓存基于行。而Memcached可以缓存任何类型的数据,并且不限于缓存数据库行。Memcached可以缓存可直接使用而无需连接的复杂对象。
鉴于MySQL具有缓存功能,为什么还需要使用memcached?
MySQL缓存仅与一个实例相关联。这限制了缓存的最大地址为一个服务器的内存大小。如果您的系统比一个服务器的内存更大,则使用MySQL缓存将无法正常工作。如果从另一个实例读取相同的对象,则不会缓存。
查询缓存在写操作时会失效。当有人对其进行写入操作时,您建立的所有缓存都会消失。根据使用模式,您的缓存可能根本不是一个很好的缓存。
查询缓存基于行。而Memcached可以缓存任何类型的数据,并且不限于缓存数据库行。Memcached可以缓存可直接使用而无需连接的复杂对象。
- monotux
6
有关网络往返的性能考虑已经被正确指出。
除了在数据库管理系统(而不是“数据库”)中缓存数据之外,将数据缓存到其他任何地方都会产生潜在过时数据的问题,这些数据仍然被呈现为“最新的”。
为了追求性能提升而放弃绝对可靠和一致的数据保证(严密或至少接近于此),这是有代价的。
每当准确性和一致性至关重要时,请考虑这一点。
- Erwin Smout
6
很多好的答案都在这里了。我会补充一个观点:我知道我的访问模式,但数据库不知道。
根据我的操作,我知道如果数据变得陈旧,那并不是真正的问题。但数据库不知道,必须重新加载新数据到缓存中。
我知道在接下来的一段时间里,我会多次访问某个数据,所以保留它很重要。但数据库必须猜测要在缓存中保留什么,它没有我拥有的信息。因此,如果我一遍又一遍地从数据库中获取它,当服务器繁忙时,可能不在缓存中。我可能会遇到缓存未命中。使用我的缓存,我可以确保获得命中。特别是对于非常规数据(即一些连接、一些组函数),而不仅仅是单行数据。对于数据库来说,获取主键为7的行很容易,但如果它必须做一些实际工作,缓存未命中的成本就会更高。
根据我的操作,我知道如果数据变得陈旧,那并不是真正的问题。但数据库不知道,必须重新加载新数据到缓存中。
我知道在接下来的一段时间里,我会多次访问某个数据,所以保留它很重要。但数据库必须猜测要在缓存中保留什么,它没有我拥有的信息。因此,如果我一遍又一遍地从数据库中获取它,当服务器繁忙时,可能不在缓存中。我可能会遇到缓存未命中。使用我的缓存,我可以确保获得命中。特别是对于非常规数据(即一些连接、一些组函数),而不仅仅是单行数据。对于数据库来说,获取主键为7的行很容易,但如果它必须做一些实际工作,缓存未命中的成本就会更高。
- MBCook
4
毫无疑问,现代数据库提供了缓存功能,但当您的网站流量增加并且需要执行许多数据库事务时,您将无法获得高性能。因此,在这种情况下,Hibernate缓存将帮助您通过优化数据库应用程序来提高性能。缓存实际上存储已从数据库加载的数据,以便在应用程序再次访问该数据时,我们的应用程序和数据库之间的流量将减少。应用程序和数据库之间的访问时间和流量将减少。
- Rupeshit
3
话虽如此,缓存有时会成为负担,并且实际上会减慢服务器速度。当您的负载很高时,缓存和未缓存内容的算法可能无法正确匹配请求...你得到的是一个像FIFO一样运行的缓存,在加班时开始显现...当坐在缓存后面的表格中的记录数量显著多于内存中将被缓存的记录数时,这种情况开始变得明显...
一个很好的折衷方案是对你想要缓存的数据进行集群。有一个主服务器向集群泵送更新,何时发送/泵送更新的时间应该能够根据TTL(生存时间)设置来定制每个表。
然后,您的用户节点逻辑和数据可以位于同一台服务器上,这打开了内存数据库,如果必须获取数据,则可以设置其使用管道而不是网络调用...
这需要一些思考,以确定如何使用数据,以及何时/是否进行集群,但是如果正在缓存的数据将独立更新而没有链接到其他数据库空间,则可以摆脱这种情况....
ORM缓存的问题在于,如果通过另一个应用程序独立更新数据库,则ORM缓存可能过时...此外,如果对一组进行更新,则可能会出现麻烦...更新可能会更新缓存中的某些内容,并且需要具有一些算法来识别哪些记录需要在内存中删除/更新(减慢更新!?)-然后这个算法变得非常棘手和容易出错!
如果使用ORM缓存,则遵循一个简单的规则...缓存很少更改的简单对象(例如用户/角色详细信息),这些对象大小小,请求中命中多次...如果超出此范围,则建议为性能而对数据进行集群。
一个很好的折衷方案是对你想要缓存的数据进行集群。有一个主服务器向集群泵送更新,何时发送/泵送更新的时间应该能够根据TTL(生存时间)设置来定制每个表。
然后,您的用户节点逻辑和数据可以位于同一台服务器上,这打开了内存数据库,如果必须获取数据,则可以设置其使用管道而不是网络调用...
这需要一些思考,以确定如何使用数据,以及何时/是否进行集群,但是如果正在缓存的数据将独立更新而没有链接到其他数据库空间,则可以摆脱这种情况....
ORM缓存的问题在于,如果通过另一个应用程序独立更新数据库,则ORM缓存可能过时...此外,如果对一组进行更新,则可能会出现麻烦...更新可能会更新缓存中的某些内容,并且需要具有一些算法来识别哪些记录需要在内存中删除/更新(减慢更新!?)-然后这个算法变得非常棘手和容易出错!
如果使用ORM缓存,则遵循一个简单的规则...缓存很少更改的简单对象(例如用户/角色详细信息),这些对象大小小,请求中命中多次...如果超出此范围,则建议为性能而对数据进行集群。
- Colin Saxton
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接