以下这些库大多数都可以用于语义相似度比较。您可以通过使用这些库中预训练模型生成单词或句子向量来跳过直接单词比较。
使用 Spacy 进行句子相似度比较
首先必须加载所需的模型。
要使用 en_core_web_md,请使用 python -m spacy download en_core_web_md 进行下载。要使用 en_core_web_lg,请使用 python -m spacy download en_core_web_lg 进行下载。
由于较大的模型大小约为830MB且速度相当慢,因此选择中等大小的模型可能是一个不错的选择。
https://spacy.io/usage/vectors-similarity/
代码:
import spacy
nlp = spacy.load("en_core_web_lg")
#nlp = spacy.load("en_core_web_md")
doc1 = nlp(u'the person wear red T-shirt')
doc2 = nlp(u'this person is walking')
doc3 = nlp(u'the boy wear red T-shirt')
print(doc1.similarity(doc2))
print(doc1.similarity(doc3))
print(doc2.similarity(doc3))
输出:
0.7003971105290047
0.9671912343259517
0.6121211244876517
Sentence Transformers实现句子相似性计算
https://github.com/UKPLab/sentence-transformers
https://www.sbert.net/docs/usage/semantic_textual_similarity.html
使用pip install -U sentence-transformers进行安装,该库可生成句子嵌入。
代码:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('distilbert-base-nli-mean-tokens')
sentences = [
'the person wear red T-shirt',
'this person is walking',
'the boy wear red T-shirt'
]
sentence_embeddings = model.encode(sentences)
for sentence, embedding in zip(sentences, sentence_embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
输出:
Sentence: the person wear red T-shirt
Embedding: [ 1.31643847e-01 -4.20616418e-01 ... 8.13076794e-01 -4.64620918e-01]
Sentence: this person is walking
Embedding: [-3.52878094e-01 -5.04286848e-02 ... -2.36091137e-01 -6.77282438e-02]
Sentence: the boy wear red T-shirt
Embedding: [-2.36365378e-01 -8.49713564e-01 ... 1.06414437e+00 -2.70157874e-01]
现在可以使用嵌入向量来计算各种相似性度量。
代码:
from sentence_transformers import SentenceTransformer, util
print(util.pytorch_cos_sim(sentence_embeddings[0], sentence_embeddings[1]))
print(util.pytorch_cos_sim(sentence_embeddings[0], sentence_embeddings[2]))
print(util.pytorch_cos_sim(sentence_embeddings[1], sentence_embeddings[2]))
输出:
tensor([[0.4644]])
tensor([[0.9070]])
tensor([[0.3276]])
同样的情况也适用于scipy和pytorch,
代码:
from scipy.spatial import distance
print(1 - distance.cosine(sentence_embeddings[0], sentence_embeddings[1]))
print(1 - distance.cosine(sentence_embeddings[0], sentence_embeddings[2]))
print(1 - distance.cosine(sentence_embeddings[1], sentence_embeddings[2]))
输出:
0.4643629193305969
0.9069876074790955
0.3275738060474396
代码:
import torch.nn
cos = torch.nn.CosineSimilarity(dim=0, eps=1e-6)
b = torch.from_numpy(sentence_embeddings)
print(cos(b[0], b[1]))
print(cos(b[0], b[2]))
print(cos(b[1], b[2]))
输出:
tensor(0.4644)
tensor(0.9070)
tensor(0.3276)
使用 TFHub Universal Sentence Encoder 进行句子相似度比较
https://tfhub.dev/google/universal-sentence-encoder/4
https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/semantic_similarity_with_tf_hub_universal_encoder.ipynb
这个模型非常大,约为1GB,并且似乎比其他模型慢。它还为句子生成嵌入。
代码:
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
embeddings = embed([
"the person wear red T-shirt",
"this person is walking",
"the boy wear red T-shirt"
])
print(embeddings)
输出:
tf.Tensor(
[[ 0.063188 0.07063895 -0.05998802 ... -0.01409875 0.01863449
0.01505797]
[-0.06786212 0.01993554 0.03236153 ... 0.05772103 0.01787272
0.01740014]
[ 0.05379306 0.07613157 -0.05256693 ... -0.01256405 0.0213196
-0.00262441]], shape=(3, 512), dtype=float32)
代码:
from scipy.spatial import distance
print(1 - distance.cosine(embeddings[0], embeddings[1]))
print(1 - distance.cosine(embeddings[0], embeddings[2]))
print(1 - distance.cosine(embeddings[1], embeddings[2]))
输出:
0.15320375561714172
0.8592830896377563
0.09080004692077637
其他句子嵌入库
https://github.com/facebookresearch/InferSent
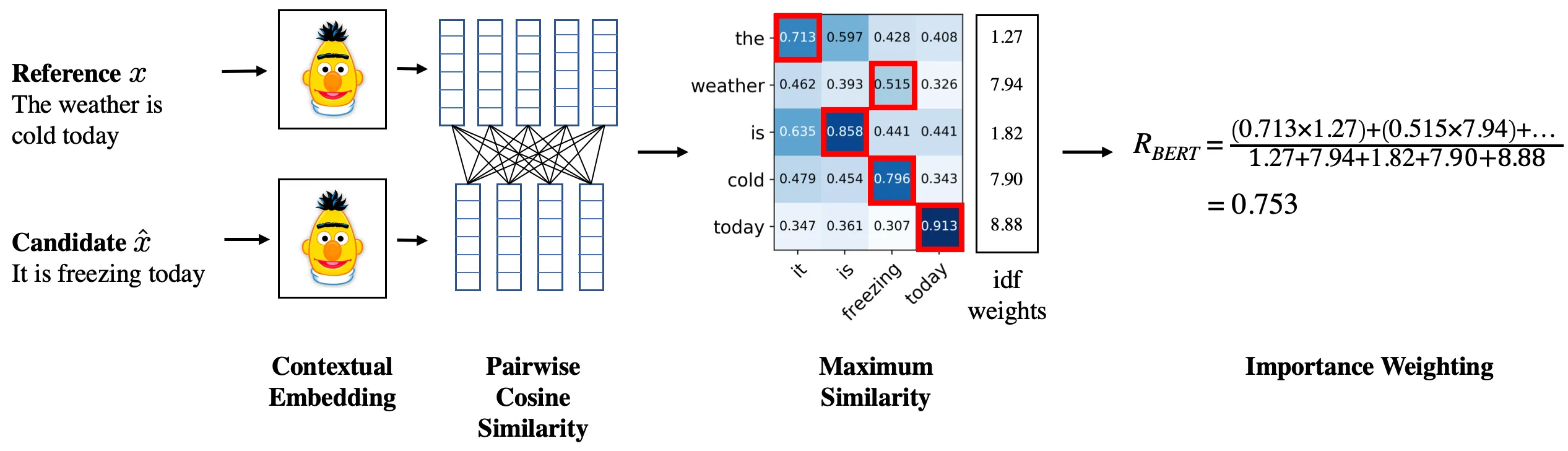
https://github.com/Tiiiger/bert_score
此示意图演示了该方法,
资源
如何计算两个文本文档之间的相似度?
https://en.wikipedia.org/wiki/Cosine_similarity#Angular_distance_and_similarity
https://towardsdatascience.com/word-distance-between-word-embeddings-cc3e9cf1d632
https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.spatial.distance.cosine.html
https://www.tensorflow.org/api_docs/python/tf/keras/losses/CosineSimilarity
https://nlp.town/blog/sentence-similarity/