阅读base64 维基 后...
我正试图弄清楚公式的作用:
给定长度为n的字符串,base64的长度将为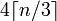
即: 4*Math.Ceiling(((double)s.Length/3)))
我已经知道base64的长度必须为%4==0,以便解码器知道原始文本长度。
序列的最大填充数可以是=或==。
维基:每个输入字节的输出字节数约为4/3(33%开销)
问题:
如何将上述信息与输出长度结合起来?
每个字符用于表示6位(log2(64) = 6)。
因此,使用4个字符来表示4 * 6 = 24位 = 3字节。
因此,您需要4*(n/3)个字符来表示n个字节,并且需要将其向上舍入为4的倍数。
向上舍入为4的倍数后导致未使用填充字符的数量显然为0、1、2或3个。
4 * n / 3 会得到未填充长度。
然后将其四舍五入到最接近的4的倍数,由于4是2的幂,因此可以使用位逻辑操作。
((4 * n / 3) + 3) & ~3
$(( ((4 * n / 3) + 3) & ~3 )),意为:将n乘以4/3再加上3,然后向下取整至最接近的能被4整除的数。 - starfry参考资料,Base64编码器的长度公式如下:
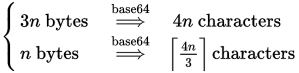
正如你所说,给定n个字节的数据,一个Base64编码器将产生一个由4n / 3个Base64字符组成的字符串。换句话说,每3个字节的数据将产生4个Base64字符。修改:一条评论正确指出我以前的图形没有考虑到填充;填充的正确公式为4(向上取整(n/3))。
维基百科文章中举例说明了ASCII字符串Man是如何编码为Base64字符串TWFu。输入字符串大小为3个字节或24位,因此该公式正确预测输出长度将为4个字节(或32位): TWFu。该过程将6个数据位编码成64个Base64字符之一,因此24位的输入除以6得到4个Base64字符。
你在评论中问编码123456的大小是多少。请记住,该字符串的每个字符都是1个字节,即8位(假设为ASCII/UTF8编码),因此我们正在编码6个字节或48位的数据。根据公式,我们预计输出长度为(6字节/3字节)*4个字符=8个字符。
将123456放入Base64编码器中会创建一个8个字符长的字符串MTIzNDU2,正如我们所预期的那样。
一般来说,我们不希望使用双精度浮点数,因为我们不想使用浮点运算、舍入误差等。它们是不必要的。
为此,记住如何执行向上取整除法是一个好主意:ceil(x / y) 可以用双精度浮点数写成 (x + y - 1) / y(避免负数,但要注意溢出)。
如果你追求可读性,当然也可以像这样编程(Java示例,对于C语言你当然可以使用宏):
public static int ceilDiv(int x, int y) {
return (x + y - 1) / y;
}
public static int paddedBase64(int n) {
int blocks = ceilDiv(n, 3);
return blocks * 4;
}
public static int unpaddedBase64(int n) {
int bits = 8 * n;
return ceilDiv(bits, 6);
}
// test only
public static void main(String[] args) {
for (int n = 0; n < 21; n++) {
System.out.println("Base 64 padded: " + paddedBase64(n));
System.out.println("Base 64 unpadded: " + unpaddedBase64(n));
}
}
填充
我们知道每3个字节(或更少)需要每次使用4个字符块。因此,该公式变为(对于x = n和y = 3):
blocks = (bytes + 3 - 1) / 3
chars = blocks * 4
或者合并:
chars = ((bytes + 3 - 1) / 3) * 4
你的编译器将优化掉3 - 1,因此只需保留它以保持可读性。
未加填充的
不太常见的是未加填充的变体,在这种情况下,我们需要记住每6位需要一个字符,向上取整:
bits = bytes * 8
chars = (bits + 6 - 1) / 6
或者组合:
chars = (bytes * 8 + 6 - 1) / 6
然而,如果我们想要的话,仍然可以将其除以二:
chars = (bytes * 4 + 3 - 1) / 3
如果您不信任编译器为您进行最终优化(或者希望让同事感到困惑):
填充的
((n + 2) / 3) << 2
未填充的
((n << 2) | 2) / 3
所以,这就是两种逻辑计算的方式,我们不需要任何分支、位运算或模运算 - 除非我们真的需要。
注意事项:
(为了给出简洁而完整的推导。)
每个输入字节有8位,因此对于n个输入字节,我们得到:
n × 8 输入比特
每6位是一个输出字节,因此:
ceil(n × 8 / 6) = ceil(n × 4 / 3) 输出字节
这是没有填充的情况。
有填充的情况下,我们将其舍入为四的倍数的输出字节:
ceil(ceil(n × 4 / 3) / 4) × 4 = ceil(n × 4 / 3 / 4) × 4 = ceil(n / 3) × 4 输出字节
参见嵌套除法(维基百科)以获取第一个等式。
使用整数算术,可以将ceil(n / m)计算为(n + m – 1) div m,因此我们得到:
(n * 4 + 2) div 3 没有填充
(n + 2) div 3 * 4 有填充
举例说明:
n with padding (n + 2) div 3 * 4 without padding (n * 4 + 2) div 3
------------------------------------------------------------------------------
0 0 0
1 AA== 4 AA 2
2 AAA= 4 AAA 3
3 AAAA 4 AAAA 4
4 AAAAAA== 8 AAAAAA 6
5 AAAAAAA= 8 AAAAAAA 7
6 AAAAAAAA 8 AAAAAAAA 8
7 AAAAAAAAAA== 12 AAAAAAAAAA 10
8 AAAAAAAAAAA= 12 AAAAAAAAAAA 11
9 AAAAAAAAAAAA 12 AAAAAAAAAAAA 12
10 AAAAAAAAAAAAAA== 16 AAAAAAAAAAAAAA 14
11 AAAAAAAAAAAAAAA= 16 AAAAAAAAAAAAAAA 15
12 AAAAAAAAAAAAAAAA 16 AAAAAAAAAAAAAAAA 16
最后,在MIME Base64编码的情况下,每76个输出字节需要两个额外的字节(CR LF),四舍五入或向上取整,具体取决于是否需要终止换行符。
这里有一个函数,可以计算Base64编码文件的原始大小,以KB为单位:
private Double calcBase64SizeInKBytes(String base64String) {
Double result = -1.0;
if(StringUtils.isNotEmpty(base64String)) {
Integer padding = 0;
if(base64String.endsWith("==")) {
padding = 2;
}
else {
if (base64String.endsWith("=")) padding = 1;
}
result = (Math.ceil(base64String.length() / 4) * 3 ) - padding;
}
return result / 1000;
}
(floor(n / 3) + 1) * 4 + 1。对于所有使用C语言的人,请看一下这两个宏:
// calculate the size of 'output' buffer required for a 'input' buffer of length x during Base64 encoding operation
#define B64ENCODE_OUT_SAFESIZE(x) ((((x) + 3 - 1)/3) * 4 + 1)
// calculate the size of 'output' buffer required for a 'input' buffer of length x during Base64 decoding operation
#define B64DECODE_OUT_SAFESIZE(x) (((x)*3)/4)
该内容摘自此处。
我没有在其他回复中看到简化公式。逻辑已经覆盖,但我需要一个最基本的形式用于我的嵌入式使用:
Unpadded = ((4 * n) + 2) / 3
Padded = 4 * ((n + 2) / 3)
注意:计算未填充计数时,我们向上取整整数除法,即加上除数-1,本例中为+2。
当其他人还在争论代数公式时,我更愿意直接使用BASE64来告诉我:
$ echo "Including padding, a base64 string requires four bytes for every three-byte chunk of the original string, including any partial chunks. One or two bytes extra at the end of the string will still get converted to four bytes in the base64 string when padding is added. Unless you have a very specific use, it is best to add the padding, usually an equals character. I added an extra byte for a null character in C, because ASCII strings without this are a little dangerous and you'd need to carry the string length separately."| wc -c
525
$ echo "Including padding, a base64 string requires four bytes for every three-byte chunk of the original string, including any partial chunks. One or two bytes extra at the end of the string will still get converted to four bytes in the base64 string when padding is added. Unless you have a very specific use, it is best to add the padding, usually an equals character. I added an extra byte for a null character in C, because ASCII strings without this are a little dangerous and you'd need to carry the string length separately." | base64 | wc -c
看起来,一个3字节的公式可以用4个base64字符表示,这是正确的。