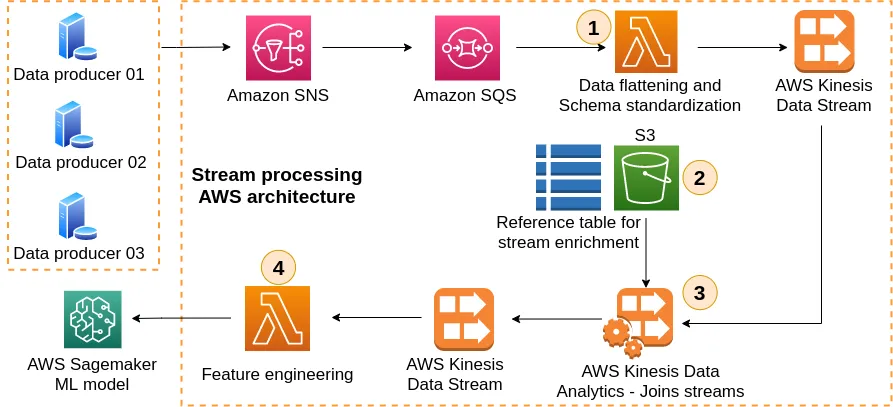
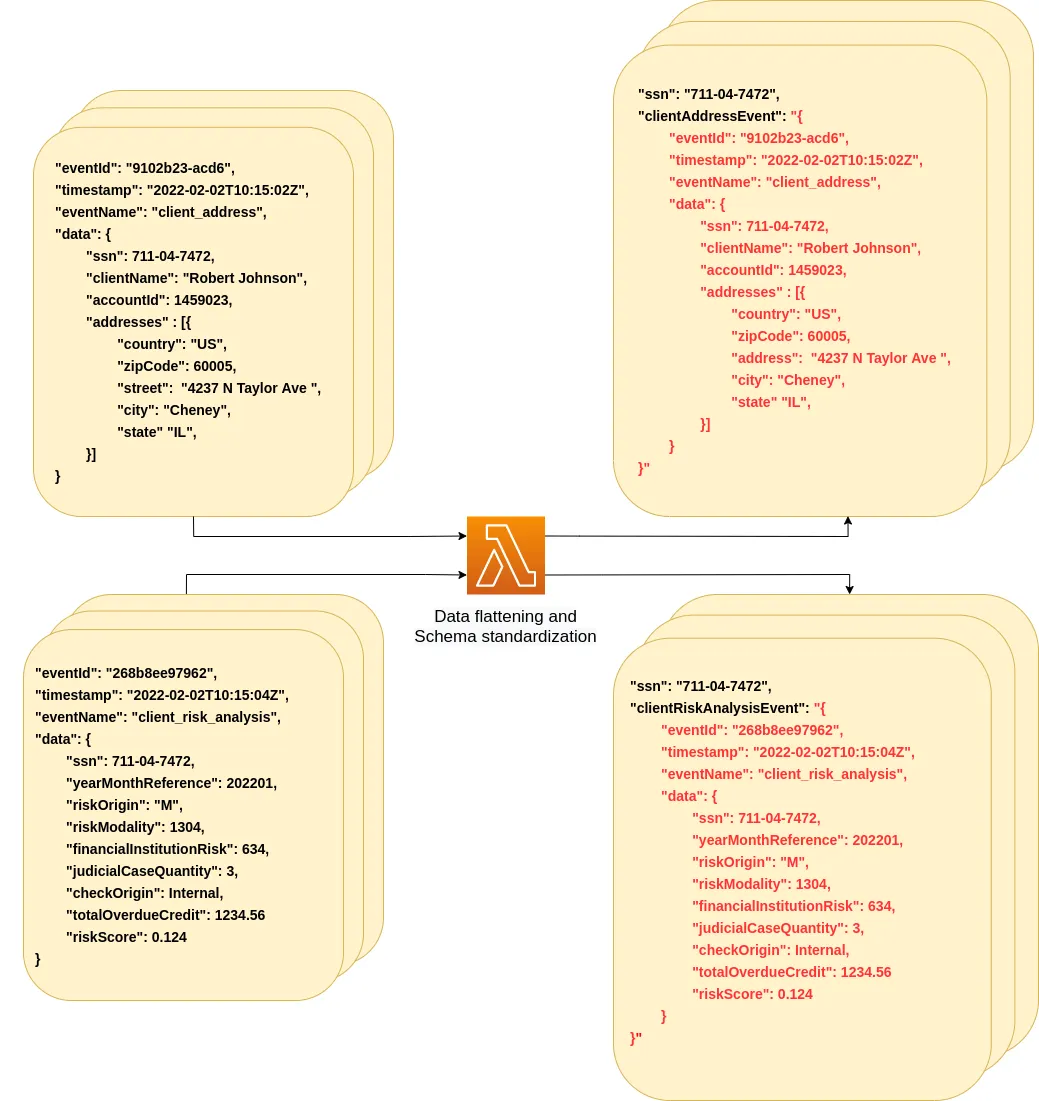
我有两个 Kinesis 流,我想创建一个第三个流,它是这两个流的交集。我的目标是让流处理器响应第三个流上的事件,而无需编写执行此交集的消费者。
流 a 上的记录将是:
{
"customer_id": 3,
"first_name":"Marcy",
"last_name":"Shurtleff"
}
而 流 b 上的记录将会是:
{
"payment_id": 10001,
"customer_id": 1,
"amount":234.56,
"date":"2018-09-07T10:25:43.511Z"
我希望执行一个类似于Kafka中KSQL的连接操作,将流 a.customer_id 与流 b.customer_id 连接起来,得到以下结果:
{
"customer_id": 3,
"first_name":"Marcy",
"last_name":"Shurtleff",
"payment_id": 10001,
"amount":234.56,
"date":"2018-09-07T10:25:43.511Z"
}
(或者我选择的任何类似SQL的投影)。
我知道使用Kafka和KSQL是可能的,但在Kinesis中可行吗?
由于Kinesis数据分析产品不能在一个以上的流中作为数据源使用,并且您只能在“应用程序内”流上执行连接,因此Kinesis不起作用。