简述
下面的代码现在已经包含在了PyPI上的infinite包中。因此你可以直接运行pip install infinite再运行下面的代码:
from itertools import count
from infinite import product
for x, y in product(count(0), count(0)):
print(x, y)
if (x, y) == (3, 3):
break
懒人的解决方案
如果您不关心顺序,由于生成器是无限的,一个有效的输出可能是:
(a0, b1), (a0, b2), (a0, b3), ... (a0, bn), ...
所以你可以从第一个生成器中获取第一个元素,然后循环第二个生成器。
如果你真的想这么做,你需要一个嵌套循环,并且你需要使用tee复制嵌套生成器,否则你将无法第二次循环它(即使它不重要,因为你永远不会用完生成器,所以你永远不需要循环)。
但如果你真的真的想这样做,那么你就有了:
from itertools import tee
def product(gen1, gen2):
for elem1 in gen1:
gen2, gen2_copy = tee(gen2)
for elem2 in gen2_copy:
yield (elem1, elem2)
这个想法是始终只制作一个gen2的副本。首先尝试有限生成器。
print(list(product(range(3), range(3,5))))
[(0, 3), (0, 4), (1, 3), (1, 4), (2, 3), (2, 4)]
然后使用无限个“1”:
print(next(product(count(1), count(1))))
(1, 1)
锯齿形扫描算法
正如评论中其他人所指出的那样(并且在先前的解决方案中已经说明),这不会产生所有的组合。尽管如此,自然数和数字对之间的映射是存在的,因此必须以不同的方式迭代数字对,以便在有限时间内查找特定的数字对(而无需无限数字)。你需要使用锯齿形扫描算法。
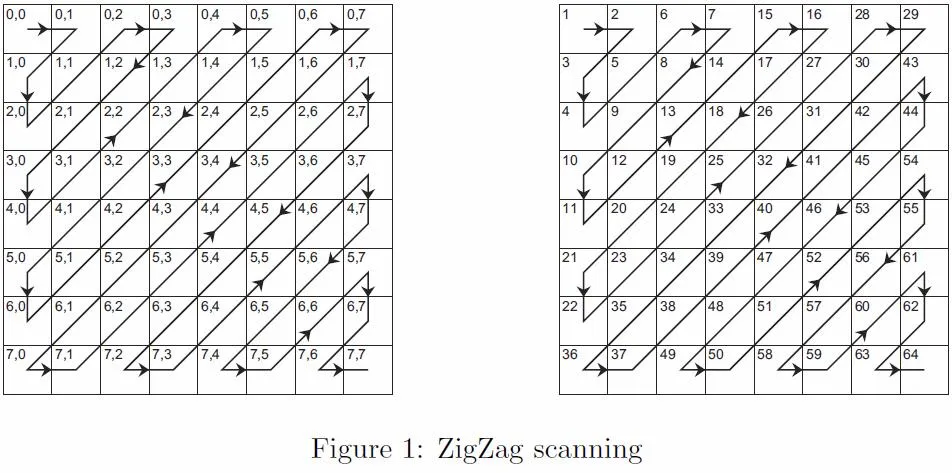
为了实现它,您需要缓存先前的值,因此我创建了一个名为GenCacher的类来缓存先前提取的值:
class GenCacher:
def __init__(self, generator):
self._g = generator
self._cache = []
def __getitem__(self, idx):
while len(self._cache) <= idx:
self._cache.append(next(self._g))
return self._cache[idx]
之后,您只需要实现Zig-Zag算法:
def product(gen1, gen2):
gc1 = GenCacher(gen1)
gc2 = GenCacher(gen2)
idx1 = idx2 = 0
moving_up = True
while True:
yield (gc1[idx1], gc2[idx2])
if moving_up and idx1 == 0:
idx2 += 1
moving_up = False
elif not moving_up and idx2 == 0:
idx1 += 1
moving_up = True
elif moving_up:
idx1, idx2 = idx1 - 1, idx2 + 1
else:
idx1, idx2 = idx1 + 1, idx2 - 1
例子
from itertools import count
for x, y in product(count(0), count(0)):
print(x, y)
if x == 2 and y == 2:
break
这将产生以下输出:
0 0
0 1
1 0
2 0
1 1
0 2
0 3
1 2
2 1
3 0
4 0
3 1
2 2
将解决方案扩展到多个发生器
我们可以稍微修改解决方案,使其适用于多个发生器。基本思路是:
迭代从(0,0)(索引之和)开始的距离。(0,0)是唯一一个距离为0的点,(1,0)和(0,1)距离为1,以此类推。
生成该距离下的所有索引元组。
提取相应的元素。
我们仍然需要GenCacher类,但代码变为:
def summations(sumTo, n=2):
if n == 1:
yield (sumTo,)
else:
for head in xrange(sumTo + 1):
for tail in summations(sumTo - head, n - 1):
yield (head,) + tail
def product(*gens):
gens = map(GenCacher, gens)
for dist in count(0):
for idxs in summations(dist, len(gens)):
yield tuple(gen[idx] for gen, idx in zip(gens, idxs))
coconut-lang感兴趣。在这里查看一个类似于你想要的示例:http://coconut.readthedocs.io/en/master/HELP.html#case-study-4-vector-field。 - Ilya V. Schurov