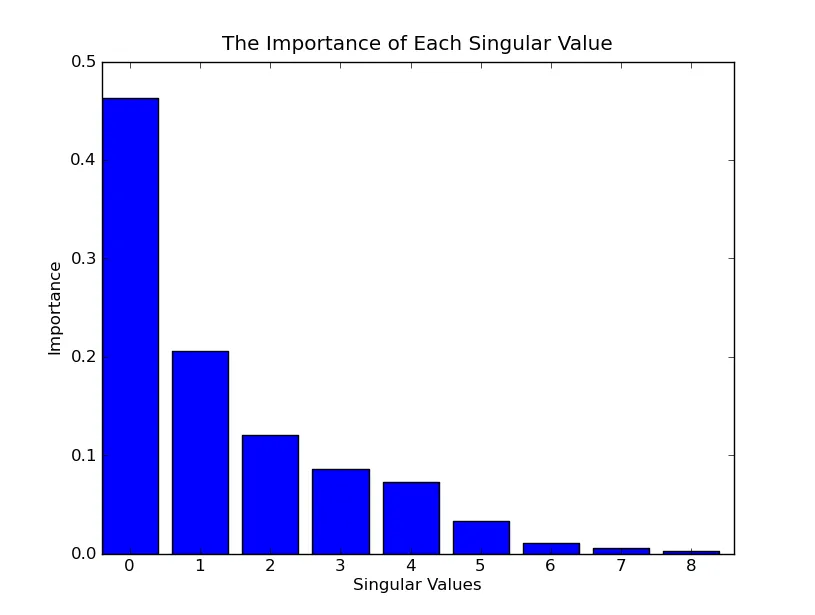
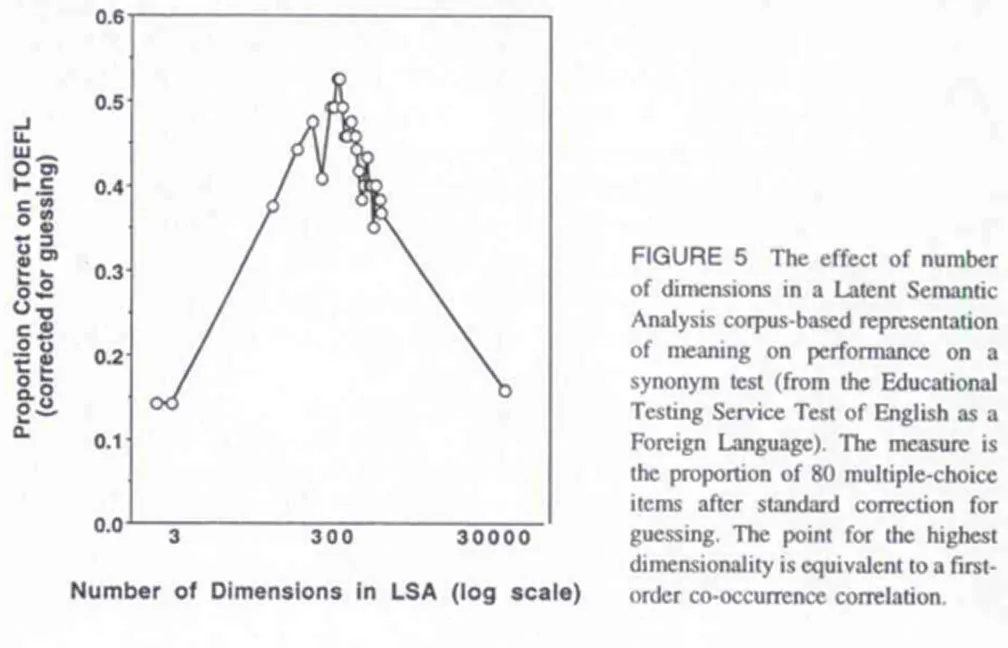
最近我一直在研究潜在语义分析。我已经使用Jama包在Java中实现了它。
下面是代码:
Matrix vtranspose ;
a = new Matrix(termdoc);
termdoc = a.getArray();
a = a.transpose() ;
SingularValueDecomposition sv =new SingularValueDecomposition(a) ;
u = sv.getU();
v = sv.getV();
s = sv.getS();
vtranspose = v.transpose() ; // we obtain this as a result of svd
uarray = u.getArray();
sarray = s.getArray();
varray = vtranspose.getArray();
if(semantics.maketerms.nodoc>50)
{
sarray_mod = new double[50][50];
uarray_mod = new double[uarray.length][50];
varray_mod = new double[50][varray.length];
move(sarray,50,50,sarray_mod);
move(uarray,uarray.length,50,uarray_mod);
move(varray,50,varray.length,varray_mod);
e = new Matrix(uarray_mod);
f = new Matrix(sarray_mod);
g = new Matrix(varray_mod);
Matrix temp =e.times(f);
result = temp.times(g);
}
else
{
Matrix temp = u.times(s);
result = temp.times(vtranspose);
}
result = result.transpose();
results = result.getArray() ;
return results ;
但是我们如何确定维度的数量?有没有一种方法可以确定系统应该减少到哪个维度以获得最佳结果?除了LSA的有效性,我们考虑哪些其他参数?