流处理和传统消息处理的基本区别是什么?人们说kafka是流处理的好选择,但实际上kafka与ActivMQ、RabbitMQ等消息框架类似。
为什么一般不说ActiveMQ也适用于流处理呢?
是消费者消费消息的速度决定是否是流处理吗?
为什么一般不说ActiveMQ也适用于流处理呢?
是消费者消费消息的速度决定是否是流处理吗?
如果你喜欢纠结细节: 消息传递是两个或多个进程或组件之间的通信,而流式传输是按照事件发送日志的过程。消息携带原始数据,而事件包含有关订单等发生和活动的信息。 因此,Kafka同时执行消息传递和流式传输。 Kafka中的主题可以是原始消息,也可以是通常保留数小时或数天的事件日志。事件可以进一步聚合成更复杂的事件。
虽然Rabbit支持流处理,但它实际上并不是为此而建立的(请参见Rabbit的网站)。 Rabbit是消息代理,Kafka是事件流平台。
Kafka可以处理大量面向Rabbit的“消息”。 Kafka是一种日志,而Rabbit是一个队列,这意味着如果被消耗了,Rabbit的消息就不再存在了(如果你需要的话)。
然而,Rabbit可以指定消息优先级,而Kafka则不能。
这取决于您的需求。
https://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/
当涉及流处理时,为什么要提到Kafka?抱歉回答比较长,但我认为简短的回答无法公正地回答问题。
考虑队列系统,例如MQ,用于:
考虑流系统,例如Kafka,作为发布/订阅和持久性系统,用于:
什么是事件和消息
IT系统中有很长的消息传递历史。您可以在消息系统和消息的上下文中轻松看到事件驱动的解决方案和事件。但是,值得考虑的有不同的特征:
消息:消息传输有效载荷,并保留消息直到被消费。消息的消费者通常直接定向和相关到关心消息是否已经被交付和处理的生产者。
事件:事件作为可重放流历史记录而存在。事件消费者不绑定于生产者。事件是发生过的事情的记录,因此无法更改。(您不能改变历史)
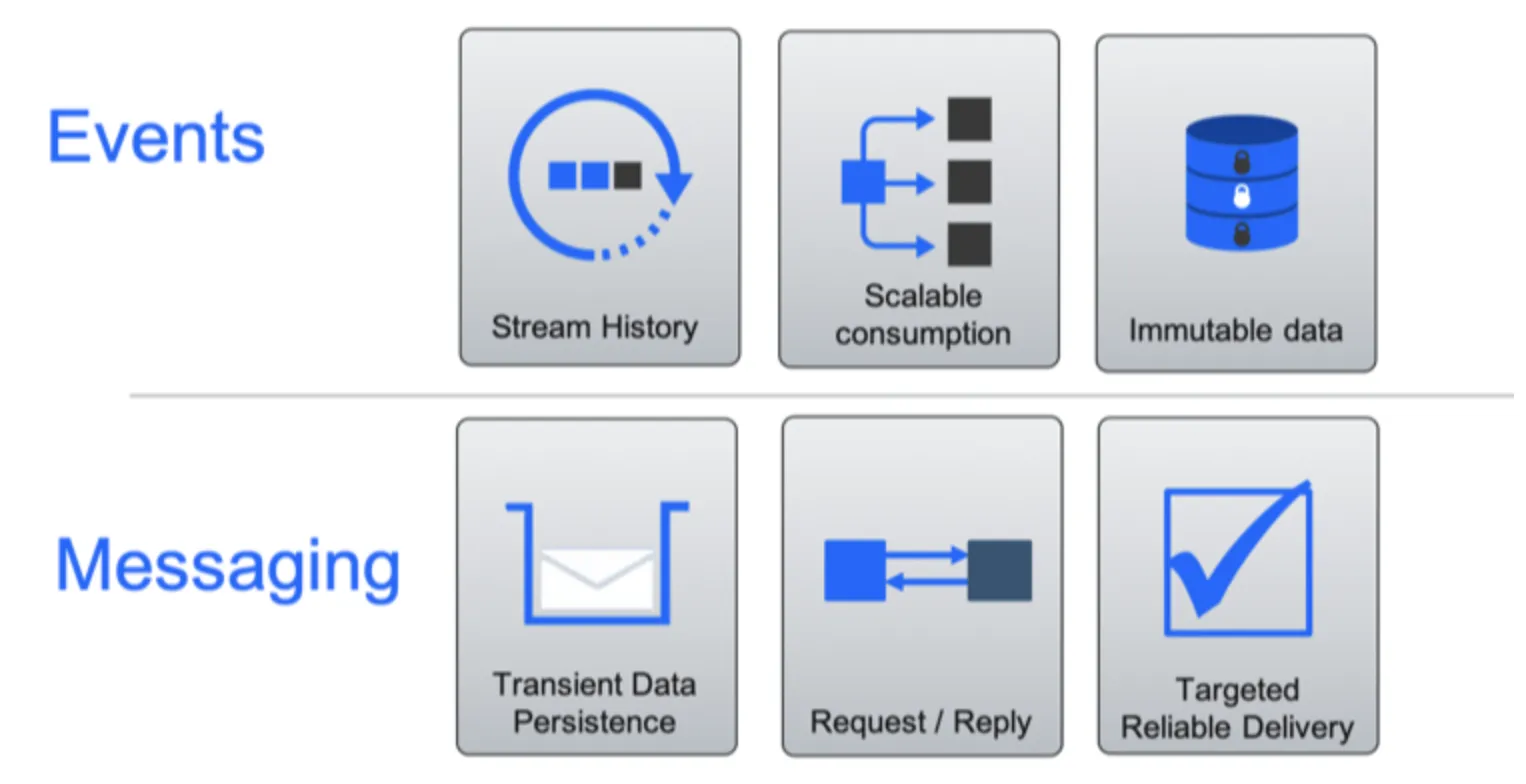
现在比较消息传递和事件流
消息用于支持:
事件用于支持:
希望这个答案能够帮助您!
消息处理涉及操作和/或使用单个消息。流处理则包括对单个消息进行操作和/或使用,以及对进入系统的消息集合进行操作。例如,假设有付款工具的交易正在进行 - 流处理可用于连续计算每小时平均支出。在这种情况下 - 可以向流中强加滑动窗口,选择在一小时内接收的消息并计算金额的平均值。然后可以将这些数字用作欺诈检测系统的输入。
最近,我看到了一份非常好的文件,介绍了“流处理”和“消息处理”的用法。
https://developer.ibm.com/articles/difference-between-events-and-messages/
在异步处理中考虑:
消息传递:
当存在“请求处理”即客户端请求服务器进行处理时,请考虑使用此方法。
事件流:
当“访问企业数据”即企业内的组件可以发出描述其当前状态的数据时,请考虑使用此方法。这些数据通常不包含针对其他系统完成操作的直接指令。相反,组件允许其他系统了解其数据和状态。
为了促进此评估,请考虑以下关键选择标准以选择适合您解决方案的正确技术: