我是一名有用的助手,可以为您翻译文本。
我认为我需要一些回溯算法来做到这一点,但在Neo4j中我不知道如何做到这一点,或者是否可能。此外,此图可以是非常庞大的图。
您会如何使用Java和Neo4j完成此操作?
谢谢。
我有一个关于Neo4j和Traversal能做什么的复杂问题。
想象一下您拥有以下的Neo4j图形
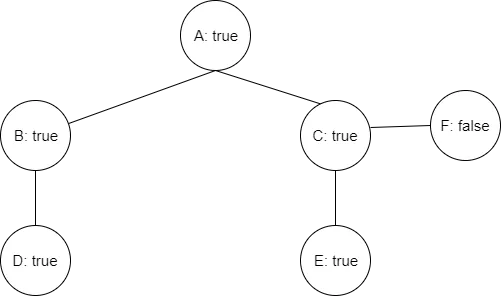
我认为我需要一些回溯算法来做到这一点,但在Neo4j中我不知道如何做到这一点,或者是否可能。此外,此图可以是非常庞大的图。
您会如何使用Java和Neo4j完成此操作?
谢谢。