我的初始目的是验证 HTTP分块传输,但无意中发现了这个不一致之处。
该API旨在将文件返回给客户端。我使用HEAD和GET方法访问它。返回的头信息不同。
对于GET,我获得了这些头:(这就是我预期的)
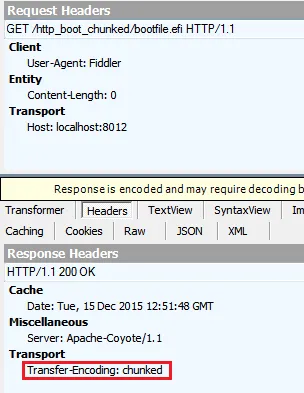
对于HEAD,我获得了这些头:
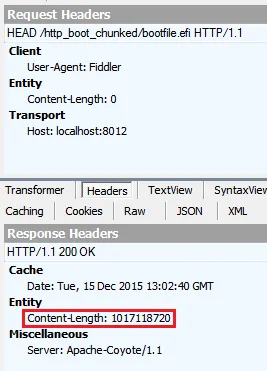
根据此线程,HEAD和GET应该返回相同的头部,但不一定。
我的问题是:
如果Transfer-Encoding: chunked是用于动态提供文件给客户端,并且Tomcat服务器不能预先知道其大小,那么当使用HEAD方法时,Tomcat如何知道Content-Length? Tomcat是否只是模拟运行处理程序并计算文件字节数?为什么它不简单地返回相同的Transfer-Encoding: chunked头部?
以下是我使用Spring Web MVC实现的RESTful API:
@RestController
public class ChunkedTransferAPI {
@Autowired
ServletContext servletContext;
@RequestMapping(value = "bootfile.efi", method = { RequestMethod.GET, RequestMethod.HEAD })
public void doHttpBoot(HttpServletResponse response) {
String filename = "/bootfile.efi";
try {
ServletOutputStream output = response.getOutputStream();
InputStream input = servletContext.getResourceAsStream(filename);
BufferedInputStream bufferedInput = new BufferedInputStream(input);
int datum = bufferedInput.read();
while (datum != -1) {
output.write(datum);
datum = bufferedInput.read();
}
output.flush();
output.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
添加1
在我的代码中,我没有显式地添加任何头文件,那么肯定是Tomcat根据需要添加Content-Length和Transfer-Encoding头文件。
那么,Tomcat决定发送哪些头文件的规则是什么?
添加2
也许这与Tomcat的工作方式有关。我希望有人能够在这里阐明一下。否则,我将调试Tomcat 8的源代码并共享结果。但那可能需要一段时间。
相关: