昨天我使用期望最大化算法实现了GMM(高斯混合模型)。
如你所记,它将某个未知分布建模为高斯混合物,我们需要学习其每个高斯分量的均值和方差以及权重。
这是代码背后的数学原理(并不复杂)http://mccormickml.com/2014/08/04/gaussian-mixture-models-tutorial-and-matlab-code/。
这是我的代码:
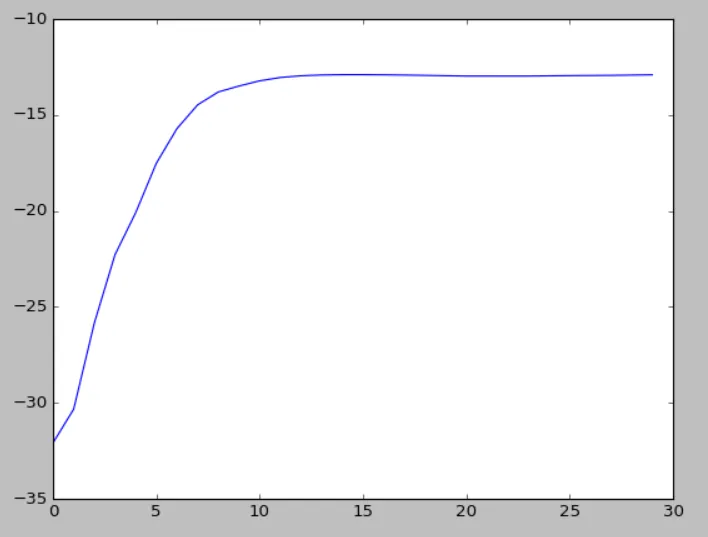
问题在于对数似然的行为很奇怪。我希望它是单调递增的,但事实并非如此。
例如,使用8个特征和3个高斯聚类的2000个示例,对数似然看起来像这样(30次迭代)-
如你所记,它将某个未知分布建模为高斯混合物,我们需要学习其每个高斯分量的均值和方差以及权重。
这是代码背后的数学原理(并不复杂)http://mccormickml.com/2014/08/04/gaussian-mixture-models-tutorial-and-matlab-code/。
这是我的代码:
import numpy as np
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
#reference for this code is http://mccormickml.com/2014/08/04/gaussian-mixture-models-tutorial-and-matlab-code/
def expectation(data, means, covs, priors): #E-step. returns the updated probabilities
m = data.shape[0] #gets the data, means covariances and priors of all clusters
numOfClusters = priors.shape[0]
probabilities = np.zeros((m, numOfClusters))
for i in range(0, m):
for j in range(0, numOfClusters):
sum = 0
for l in range(0, numOfClusters):
sum += normalPDF(data[i, :], means[l], covs[l]) * priors[l, 0]
probabilities[i, j] = normalPDF(data[i, :], means[j], covs[j]) * priors[j, 0] / sum
return probabilities
def maximization(data, probabilities): #M-step. this updates the means, covariances, and priors of all clusters
m, n = data.shape
numOfClusters = probabilities.shape[1]
means = np.zeros((numOfClusters, n))
covs = np.zeros((numOfClusters, n, n))
priors = np.zeros((numOfClusters, 1))
for i in range(0, numOfClusters):
priors[i, 0] = np.sum(probabilities[:, i]) / m #update priors
for j in range(0, m): #update means
means[i] += probabilities[j, i] * data[j, :]
vec = np.reshape(data[j, :] - means[i, :], (n, 1))
covs[i] += probabilities[j, i] * np.dot(vec, vec.T) #update covs
means[i] /= np.sum(probabilities[:, i])
covs[i] /= np.sum(probabilities[:, i])
return [means, covs, priors]
def normalPDF(x, mean, covariance): #this is simply multivariate normal pdf
n = len(x)
mean = np.reshape(mean, (n, ))
x = np.reshape(x, (n, ))
var = multivariate_normal(mean=mean, cov=covariance,)
return var.pdf(x)
def initClusters(numOfClusters, data): #initialize all the gaussian clusters (means, covariances, priors
m, n = data.shape
means = np.zeros((numOfClusters, n))
covs = np.zeros((numOfClusters, n, n))
priors = np.zeros((numOfClusters, 1))
initialCovariance = np.cov(data.T)
for i in range(0, numOfClusters):
means[i] = np.random.rand(n) #the initial mean for each gaussian is chosen randomly
covs[i] = initialCovariance #the initial covariance of each cluster is the covariance of the data
priors[i, 0] = 1.0 / numOfClusters #the initial priors are uniformly distributed.
return [means, covs, priors]
def logLikelihood(data, probabilities): #data is our data. probabilities[i, j] = k means probability example i belongs in cluster j is 0 < k < 1
m = data.shape[0] #num of examples
examplesByCluster = np.zeros((m, 1))
for i in range(0, m):
examplesByCluster[i, 0] = np.argmax(probabilities[i, :])
examplesByCluster = examplesByCluster.astype(int) #examplesByCluster[i] = j means that example i belongs in cluster j
result = 0
for i in range(0, m):
result += np.log(probabilities[i, examplesByCluster[i, 0]]) #example i belongs in cluster examplesByCluster[i, 0]
return result
m = 2000 #num of training examples
n = 8 #num of features for each example
data = np.random.rand(m, n)
numOfClusters = 2 #num of gaussians
numIter = 30 #num of iterations of EM
cost = np.zeros((numIter, 1))
[means, covs, priors] = initClusters(numOfClusters, data)
for i in range(0, numIter):
probabilities = expectation(data, means, covs, priors)
[means, covs, priors] = maximization(data, probabilities)
cost[i, 0] = logLikelihood(data, probabilities)
plt.plot(cost)
plt.show()
问题在于对数似然的行为很奇怪。我希望它是单调递增的,但事实并非如此。
例如,使用8个特征和3个高斯聚类的2000个示例,对数似然看起来像这样(30次迭代)-
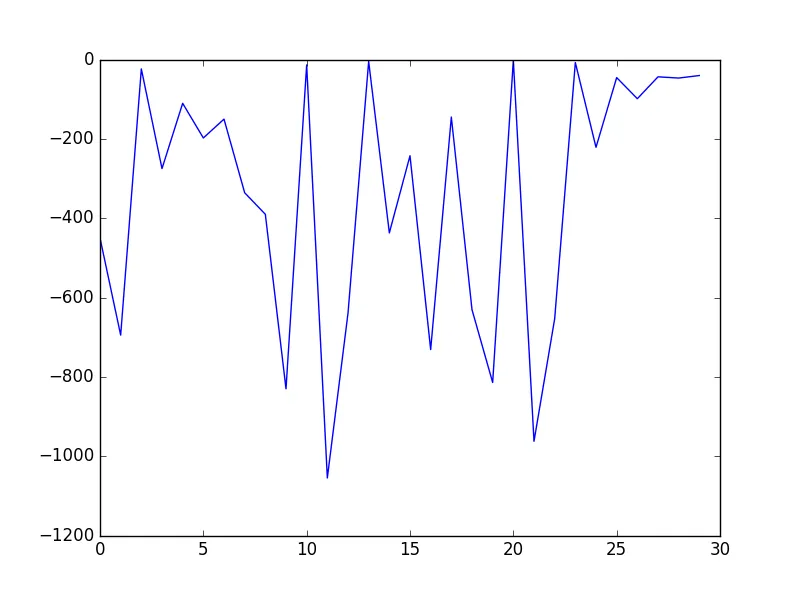
所以这很糟糕。但是在我进行的其他测试中,例如一个包含2个特征和2个聚类的15个示例的测试,对数似然值为 -
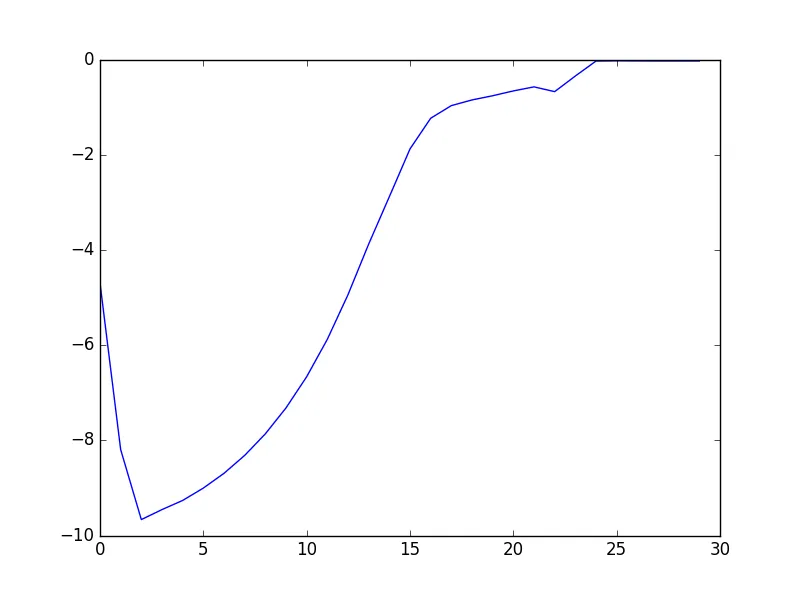
进步了但还不完美。
为什么会发生这种情况,我该如何解决?