我正在尝试解决将人类生成的手势与已知手势进行匹配的问题。人类生成的手势将由一系列点表示,这些点需要被插值成路径并与现有路径进行比较。下面的图片展示了我要比较的内容:
 请帮忙提供资源或概念,帮助我构建一个算法来匹配这两条路径。由于我之前没有这方面的经验,因此任何见解都将不胜感激。
请帮忙提供资源或概念,帮助我构建一个算法来匹配这两条路径。由于我之前没有这方面的经验,因此任何见解都将不胜感激。
请帮忙提供资源或概念,帮助我构建一个算法来匹配这两条路径。由于我之前没有这方面的经验,因此任何见解都将不胜感激。
请帮忙提供资源或概念,帮助我构建一个算法来匹配这两条路径。由于我之前没有这方面的经验,因此任何见解都将不胜感激。在某个时间间隔内测量输入。每隔 xx 毫秒,测量用户手指/笔的坐标。
修改模式。目前它是一个连续的“函数”,但是以这样的方式测量输入是很困难的。使用某个时间间隔内的离散点。这个间隔可以非常短,取决于您需要多么精确地识别手势。实际上,它应该非常短;与更多点进行比较越多,结果会越好(我将在下一部分中更好地解释这个问题)。
当测量输入时,输入测量间隔需要足够短,以便每个接收到的连续输入点对足够接近,可以与预期点进行比较。
想象一下,用户非常快地执行了某些手势(并在您的输入阅读器仅读取三帧的时间内完成)。模式和输入无法可靠地进行比较:
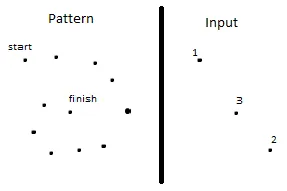
为了避免这种情况,您的输入阅读器必须具有相对较短的间隔。然而,这可能并不是一个很大的问题,因为大多数硬件甚至可以读取最快的人类手势。
回到模式:它们应该始终足够详细,以包括任何可能的输入点。更多的预期点可以提高准确度。如果用户移动得很慢,则输入将具有更多的点;如果他们移动得很快,则输入将具有更少的点。
请考虑以下事项:完成单个手势会给您一半的输入帧,这些输入帧比模式中包含的点要少。用户以“正常”速度移动,因此,为了简化算法,您可以将模式“降级”一倍,然后直接将输入坐标与模式坐标进行比较。
这种方法比下一节中想到的替代方法更容易。
如果您只有少量的预期点,您将不得不做出一些近似值来匹配输入。
这是一个“极端”的示例,但它证明了这个概念。给定这个模式和输入:
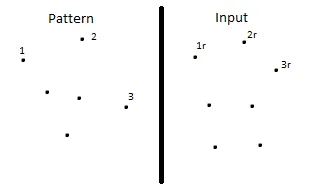
点 3r 无法与点 2 或点 3 可靠比较,因此您必须使用点 2、3 和 3r 的一些函数来确定 3r 是否在正确的路径上。现在考虑相同的输入,但是模式的密度更高:
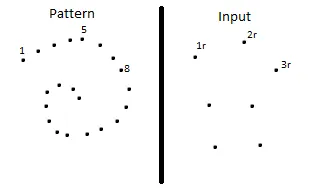
现在,您不必妥协,因为 3r 实际上肯定在手势模式中。模式的轻微减少使其与输入很好地匹配。
与其在触摸屏等绝对位置上进行比较,您可能希望手势可以在某个平面的任何地方被允许。为此,您必须将输入的起始点与某个坐标系相关联。
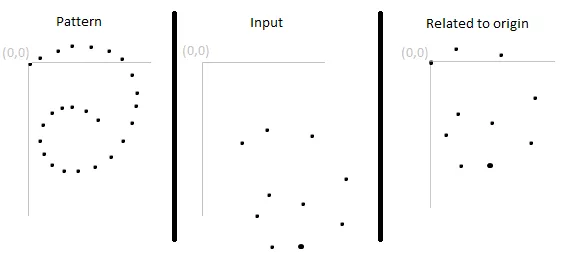
为了使用户友好,允许手势在一定范围内完成。您不想比较原始数据,因为输入平面的大小很可能与模式平面的大小不匹配。
将输入在x和y方向上规范化以匹配您的模式的大小。不要保持宽高比。
RecMaxH和RecMaxV)ExpMaxH和ExpMaxV)ExpMaxH/RecMaxHExpMaxV/RecMaxV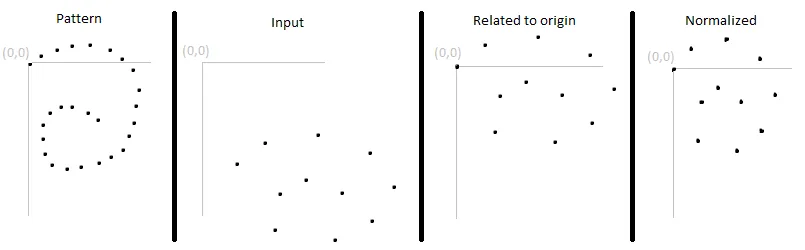
现在您有两组更相似的点,可以进行比较。规范化可以比这更详细;例如,您可以每次规范化3个点集以获得非常相似的图像(但您可能必须为每个模式执行此操作,然后将所有差异的总和进行比较以找到最可能的匹配模式)。
我建议将所有手势模式存储为相同大小的图形;这样在测量输入与可能的模式匹配的接近程度时可以减少计算量。
想象一下一个按钮,在点击/激活时,导致程序开始测量输入。这类似于Google的语音搜索,它不会持续记录和搜索;相反,您说“好 Jarvis”或单击便捷的麦克风图标并开始说出您的查询。
优点:
缺点: