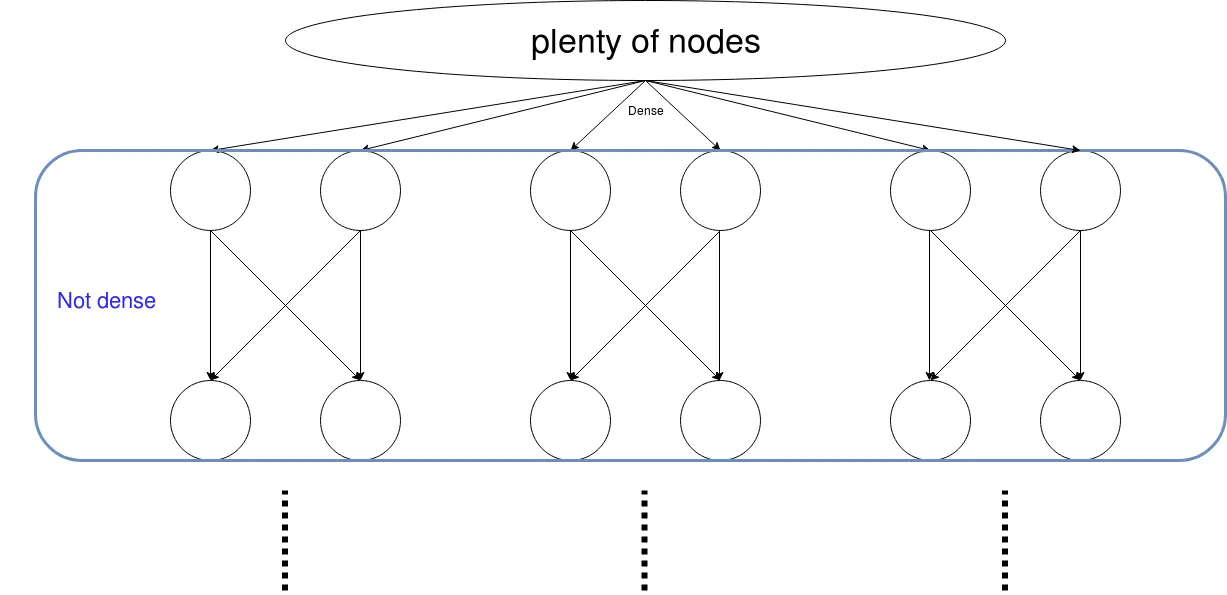
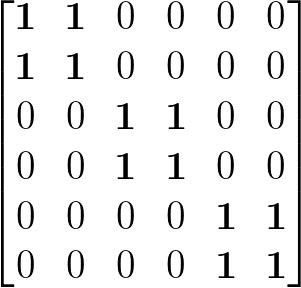编辑
所以评论是:这是一个可训练的对象吗?
答案:不是。您目前不能使用稀疏矩阵并使其可训练。相反,您可以使用掩码矩阵(请参见末尾)。
但是,如果您需要使用稀疏矩阵,则只需使用tf.sparse.sparse_dense_matmul()或tf.sparse_tensor_to_dense(),其中您的稀疏矩阵与密集矩阵交互。我从此处获取了一个简单的XOR示例,并将密集矩阵替换为稀疏矩阵:
import tensorflow as tf
import numpy as np
"""
A simple numpy implementation of a XOR gate to understand the backpropagation
algorithm
"""
x = tf.placeholder(tf.float32,shape = [4,2],name = "x")
y = tf.placeholder(tf.float32,shape = [4,1],name = "y")
m = np.shape(x)[0]
n = np.shape(x)[1]
hidden_s = 2
l_r = 1
theta1 = tf.SparseTensor(indices=[[0, 0],[0, 1], [1, 1]], values=[0.1, 0.2, 0.1], dense_shape=[3, 2])
theta2 = tf.cast(tf.Variable(tf.random_normal([hidden_s+1,1]),name = "theta2"),tf.float32)
a1 = tf.concat([np.c_[np.ones(x.shape[0])],x],1)
z1 = tf.matmul(a1,tf.sparse_tensor_to_dense(theta1))
a2 = tf.concat([np.c_[np.ones(x.shape[0])],tf.sigmoid(z1)],1)
z3 = tf.matmul(a2,theta2)
h3 = tf.sigmoid(z3)
cost_func = -tf.reduce_sum(y*tf.log(h3)+(1-y)*tf.log(1-h3),axis = 1)
optimiser = tf.train.GradientDescentOptimizer(learning_rate = l_r).minimize(cost_func)
X = [[0,0],[0,1],[1,0],[1,1]]
Y = [[0],[1],[1],[0]]
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(200):
sess.run(optimiser, feed_dict = {x:X,y:Y})
if i%100==0:
print("Epoch:",i)
print(sess.run(theta1))
输出结果为:
Epoch: 0
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[1, 1]]), values=array([0.1, 0.2, 0.1], dtype=float32), dense_shape=array([3, 2]))
Epoch: 100
SparseTensorValue(indices=array([[0, 0],
[0, 1],
[1, 1]]), values=array([0.1, 0.2, 0.1], dtype=float32), dense_shape=array([3, 2]))
所以唯一的方法是使用掩码矩阵。你可以通过乘法或tf.where来使用它。
1) 乘法:你可以创建所需形状的掩码矩阵,并将其与权重矩阵相乘:
mask = tf.Variable([[1,0,0],[0,1,0],[0,0,1]],name ='mask', trainable=False)
weight = tf.cast(tf.Variable(tf.random_normal([3,3])),tf.float32)
desired_tensor = tf.matmul(weight, mask)
2) tf.where
mask = tf.Variable([[1,0,0],[0,1,0],[0,0,1]],name ='mask', trainable=False)
weight = tf.cast(tf.Variable(tf.random_normal([3,3])),tf.float32)
desired_tensor = tf.where(mask > 0, tf.ones_like(weight), weight)
希望这能有所帮助。
您可以通过使用稀疏张量来实现此操作,如下所示:
SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4])
输出结果为:
[[1, 0, 0, 0]
[0, 0, 2, 0]
[0, 0, 0, 0]]
您可以在这里查阅更多关于稀疏张量的文档:
https://www.tensorflow.org/api_docs/python/tf/sparse/SparseTensor
希望对您有所帮助!