是的,我知道所有版本的 printf 都存在这个问题。我在 这个答案 和 这个答案 中简要讨论了此事。
对于 C 语言,我不知道有没有库可以为您解决这个问题,但如果有的话,那就应该是 ICU。
对于 Perl,您需要使用 CPAN 中的 Unicode::GCString 模块来计算 Unicode 字符串占用的打印列数。它考虑了Unicode 标准附录#11:东亚宽度。
例如,某些代码点占用1列,而其他代码点占用2列。甚至还有一些根本不占用任何列,如组合字符和不可见的控制字符。该类具有一个 columns 方法,返回字符串占用的列数。
我有一个使用该类进行垂直对齐 Unicode 文本的示例,在 这里。它会对一堆 Unicode 字符串进行排序,包括一些带有组合字符和“宽”亚洲表意文字(CJK 字符),并允许您垂直对齐这些字符串。
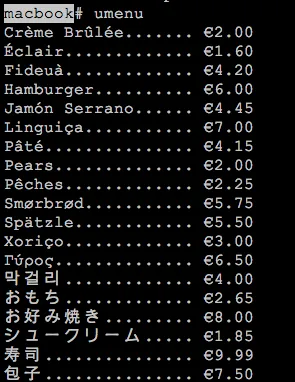
下面是打印漂亮对齐输出的小 umenu 演示程序代码:
您可能还会对更为雄心勃勃的 Unicode::LineBreak 模块感兴趣,其前面提到的 Unicode::GCString 类只是其较小的组成部分。该模块更加强大,考虑了Unicode 标准附录#14:Unicode 文本断行算法。
下面是经过 Perl v5.14 测试的小 umenu 演示程序的代码:
use utf8;
use v5.14;
use strict;
use warnings;
use warnings qw(FATAL utf8);
use open qw(:std :utf8);
use charnames qw(:full :short);
use Unicode::Normalize;
use List::Util qw(max);
use Unicode::Collate::Locale;
use Unicode::GCString;
sub pad($$$);
sub colwidth(_);
sub entitle(_);
my %price = (
"γύρος" => 6.50,
"pears" => 2.00,
"linguiça" => 7.00,
"xoriço" => 3.00,
"hamburger" => 6.00,
"éclair" => 1.60,
"smørbrød" => 5.75,
"spätzle" => 5.50,
"包子" => 7.50,
"jamón serrano" => 4.45,
"pêches" => 2.25,
"シュークリーム" => 1.85,
"막걸리" => 4.00,
"寿司" => 9.99,
"おもち" => 2.65,
"crème brûlée" => 2.00,
"fideuà" => 4.20,
"pâté" => 4.15,
"お好み焼き" => 8.00,
);
my $width = 5 + max map { colwidth } keys %price;
my $coll = new Unicode::Collate::Locale locale => "ja";
for my $item ($coll->sort(keys %price)) {
print pad(entitle($item), $width, ".");
printf " €%.2f\n", $price{$item};
}
sub pad($$$) {
my($str, $width, $padchar) = @_;
return $str . ($padchar x ($width - colwidth($str)));
}
sub colwidth(_) {
my($str) = @_;
return Unicode::GCString->new($str)->columns;
}
sub entitle(_) {
my($str) = @_;
$str =~ s{ (?=\pL)(\S) (\S*) }
{ ucfirst($1) . lc($2) }xge;
return $str;
}
正如您所见,使它在该特定程序中运行的关键是这行代码,它只是调用上面定义的其他函数,并使用我讨论的模块:
print pad(entitle($item), $width, ".");
这将使用点作为填充字符,将该项填充到给定的宽度。
是的,这比 printf 不方便得多,但至少是可行的。
East_Asian_Width=Ambiguous字符。我不知道是否有任何Go库可以像我回答中描述的Perl库那样处理这个问题,但如果有这样的东西供Go使用,我很想了解!谢谢。 - tchristprintf只关心字节数。如果您想考虑字符数,请使用wprintf(记住,它需要一个wchar_t*格式)。在 C 中没有格式化函数考虑显示宽度。 - n. m.printf由C标准定义,任何偏离它的行为都是非标准的。 - n. m.