我写了一个方便的小函数,可以用来选择最大的行距。你可以使用n参数指定你想要最大的、第二大的等等。
getBigSegment <- function(x, y, n = 1){
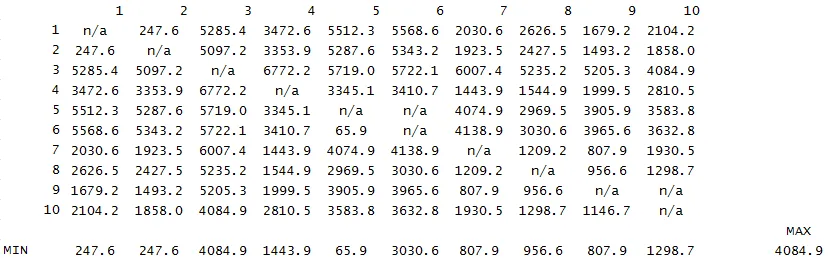
a <- cbind(x,y)
d <- as.matrix(dist(a, method = "euclidean"))
sorted <- order(d, decreasing = T)
sub <- (1:length(d))[as.logical(1:length(sorted) %% 2)]
s <- which(d == d[sorted[sub][n]], arr.ind = T)
t(cbind(a[s[1],], a[s[2],]))
}
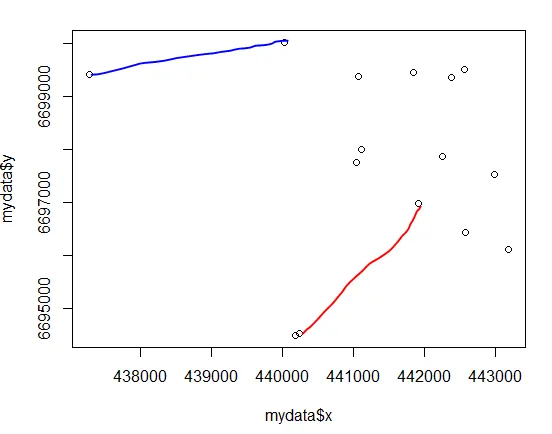
有一些类似于您自己的示例数据,您可以看到:
set.seed(100)
mydata <- data.frame(x = runif(10, 438000, 445000) + rpois(10, 440000),
y = runif(10, 6695000, 6699000) + rpois(10, 6996000))
getBigSegment(mydata$x, mydata$y)
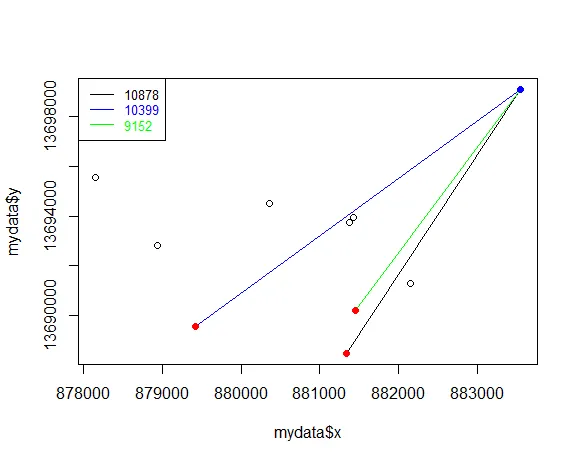
以下是我如何使用这样一个函数的可视化演示。
pointsegments <- function(z, ...) {
segments(z[1,1], z[1,2], z[2,1], z[2,2], ...)
points(z, pch = 16, col = c("blue", "red"))
}
plot(mydata$x, mydata$y)
top3 <- lapply(1:3, getBigSegment, x = mydata$x, y = mydata$y)
mycolors <- c("black","blue","green")
for(i in 1:3) pointsegments(top3[[i]], col = mycolors[i])
legend("topleft", legend = round(unlist(lapply(top3, dist))), lty = 1,
col = mycolors, text.col = mycolors, cex = .8)