我认为这是一个简单的问题,但是我无法解决我的问题。
我有一个数据框,它有9列,我想获取第4列(LumenLength)的每个组中排名最高的3个值。
我想要做到以下几点: a)找到每个SampleID(第一列)的前10个包含第4列最高值的行 b)计算每个SampleID的这10个值的平均值
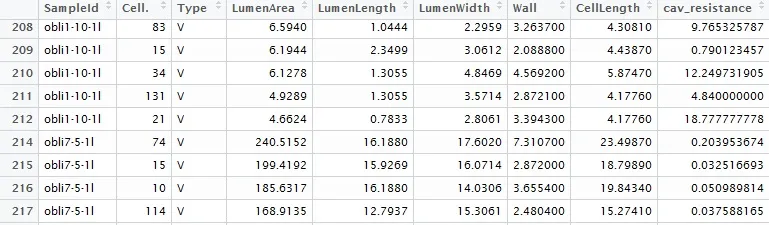
我的当前代码a)首先根据SampleID和LumenLength排序值,然后b)分离每个SampleID中最高、次高和第三高的LumenLength值。
sorted.v= arrange(sorted.v, desc(SampleId), LumenLength)
maxlength1 = aggregate(sorted.v$LumenLength,by = list(sorted.v$SampleId), FUN = tail, n = 1)#highest value
maxlength2 = aggregate(sorted.v$LumenLength,by = list(sorted.v$SampleId), FUN = tail, n = 2)#second highest value
maxlength3 = aggregate(sorted.v$LumenLength,by = list(sorted.v$SampleId), FUN = tail, n = 3)#3. highest value
如您所见,我还没有真正达到我的目标。我也相信有更好的方法来做到这一点,但我现在卡住了。