dtreeviz有一种简单而直观的方法来可视化决策树。当我们使用XGBoost模型进行训练时,通常会创建许多决策树。而测试数据的预测将涉及将所有树的值累加以推导出测试目标值。那么,我们如何可视化这些树中的代表性树?
在尝试回答这个问题时,我使用了sklearn加利福尼亚房屋数据,并使用XGBoost进行了训练。以下是代码:
我使用了
"
我们得到了这个图像: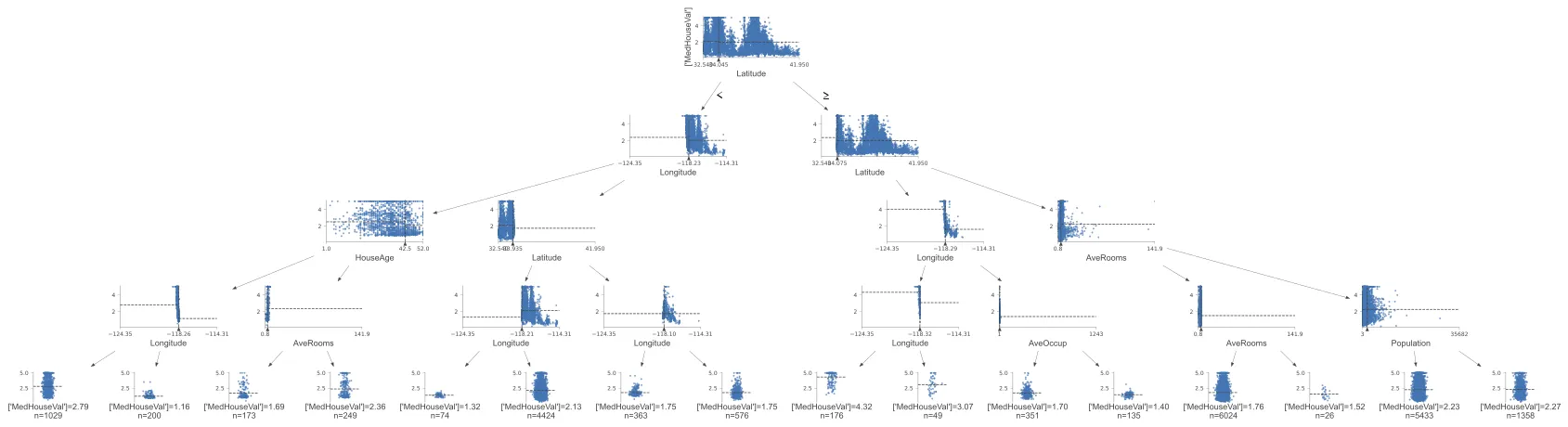 如果我使用这个`ShadowXGBDTree`来绘制验证行的预测路径,它返回的值与模型预测的值不同。为了说明,我随机选择了`X_valid[50]`并绘制了其预测路径,如下所示:
如果我使用这个`ShadowXGBDTree`来绘制验证行的预测路径,它返回的值与模型预测的值不同。为了说明,我随机选择了`X_valid[50]`并绘制了其预测路径,如下所示:
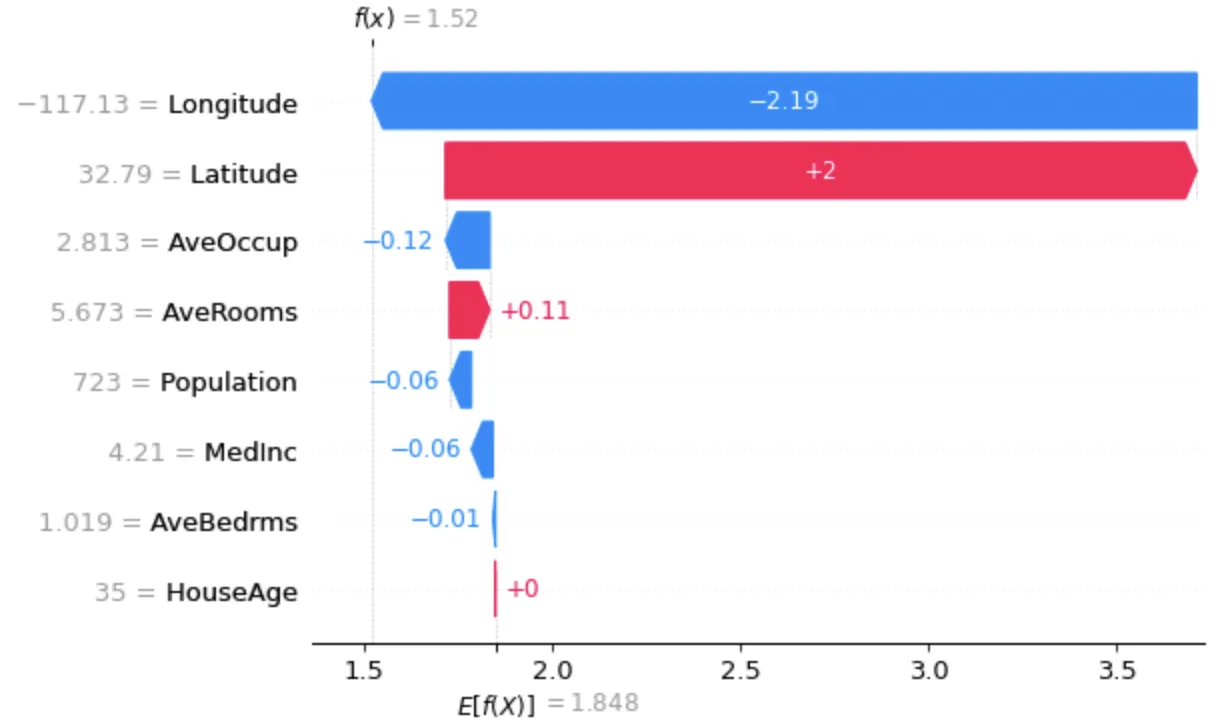
预测的目标值为2.13,如下所示: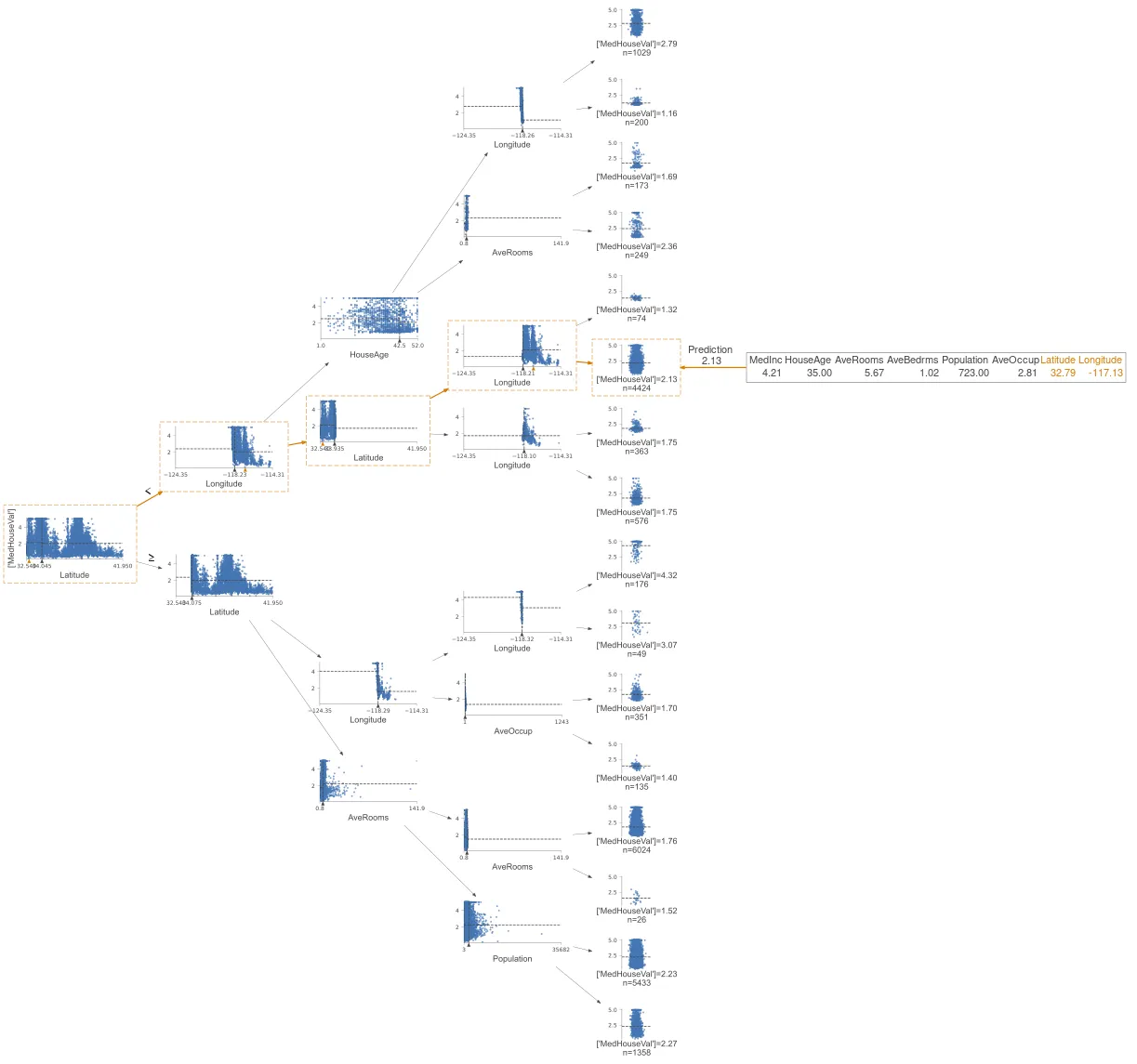 然而,y_valid[50]的值为1.741,甚至y_pred[50]的值为1.5196749,两者都与图中显示的值不匹配。我猜这是可以预料的,因为我只是使用这个特定的树来进行路径预测。那么我应该如何选择代表性的树呢?
然而,y_valid[50]的值为1.741,甚至y_pred[50]的值为1.5196749,两者都与图中显示的值不匹配。我猜这是可以预料的,因为我只是使用这个特定的树来进行路径预测。那么我应该如何选择代表性的树呢?
有什么想法可以解决这个问题吗?谢谢。
在尝试回答这个问题时,我使用了sklearn加利福尼亚房屋数据,并使用XGBoost进行了训练。以下是代码:
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import xgboost as xgb
housing = fetch_california_housing()
X_train, X_valid, y_train, y_valid = train_test_split(housing.data, housing.target,
test_size = 0.33, random_state = 11)
dtrain = xgb.DMatrix(data=X_train, label=y_train)
dvalid= xgb.DMatrix(data=X_valid, label=y_valid)
# specify xgboost parameters and train the model
params_reg = {"max_depth":4, "eta":0.3, "objective":"reg:squarederror", "subsample":1}
xgb_model_reg = xgb.train(params=params_reg, dtrain=dtrain, num_boost_round=1000, \
early_stopping_rounds=50, evals=[(dtrain, "train"),(dvalid, "valid")], verbose_eval=True)
我使用了
early_stopping_rounds,它在以下迭代中停止:[0] train-rmse:1.46031 valid-rmse:1.47189
[1] train-rmse:1.14333 valid-rmse:1.15873
[2] train-rmse:0.93840 valid-rmse:0.95947
[3] train-rmse:0.80224 valid-rmse:0.82699
...
[308] train-rmse:0.28237 valid-rmse:0.47431
[309] train-rmse:0.28231 valid-rmse:0.47429
"
xgb_model_reg.best_iteration 是260。
使用这棵最佳树,我绘制了以下的dtreeviz树:"
from dtreeviz import trees
from dtreeviz.models.xgb_decision_tree import ShadowXGBDTree
best_tree = xgb_model_reg.best_iteration
xgb_shadow_reg = ShadowXGBDTree(xgb_model_reg, best_tree, housing.data, housing.target, \
housing.feature_names, housing.target_names)
trees.dtreeviz(xgb_shadow_reg)
我们得到了这个图像:
如果我使用这个`ShadowXGBDTree`来绘制验证行的预测路径,它返回的值与模型预测的值不同。为了说明,我随机选择了`X_valid[50]`并绘制了其预测路径,如下所示:# predict
y_pred = xgb_model_reg.predict(dvalid)
# select a sample row and visualize path
X_sample = X_valid[50]
viz = trees.dtreeviz(xgb_shadow_reg,
X_valid,
y_valid,
target_name='MedHouseVal',
orientation ='LR', # left-right orientation
feature_names=housing.feature_names,
class_names=list(housing.target_names),
X=X_sample)
viz
预测的目标值为2.13,如下所示:
然而,y_valid[50]的值为1.741,甚至y_pred[50]的值为1.5196749,两者都与图中显示的值不匹配。我猜这是可以预料的,因为我只是使用这个特定的树来进行路径预测。那么我应该如何选择代表性的树呢?有什么想法可以解决这个问题吗?谢谢。