在我特定情况下的背景下,我想创建一个树形结构,表示这些轮廓之间的关系,使得最外层是根,下一个级别的每个轮廓都是子代,依此类推。因此,一个节点可以有零到多个子节点。
算法的一个关键要求是尽量减少测试以确定轮廓是否为另一个轮廓的子项,因为此操作非常昂贵。轮廓可能(并经常)共享许多顶点,但不应相交。这些共享顶点通常出现在达到地图限制的位置 - 想象一组半圆锥形放置在地图的直边上。如果我需要运行大量点在线路上之前才能得出明确的答案,则点在多边形上的测试速度很慢。
以下是我迄今为止想出的算法。它可能相当幼稚,但它有效。可能有一些启发式方法可以帮助 - 例如,轮廓只有在一定范围内的深度内才可能是另一个轮廓的子项 - 但我首先要掌握基本算法。第一个红旗是指它是指数级的。
for each candidate_contour in all_contours
for each contour in all_contours
// note already contains means "is direct or indirect child of"
if contour == candidate_contour or contour already contains(candidate_contour)
continue
else
list contours_to_check
contours_to_check.add(candidate_contour)
contour parent_contour = candidate_contour.parent
while (parent_contour != null)
contours_to_check.add(parent_contour)
parent_contour = parent_contour.parent
for each possible_move_candidate in contours_to_check (REVERSE ITERATION)
if possible_move_candidate is within contour
// moving a contour moves the contour and all of its children
move possible_move_candidate to direct child of contour
break
这个方法能够运行 - 或者至少看起来是可以的 - 但是当轮廓数量非常大时(比如几百个,甚至可能几千个)会变得非常慢。
有没有更好的基本方法来解决这个问题?或者说,有没有已知的算法可以处理这种情况?正如之前提到的 - 在我的情况下,关键是尽量减少“是否在轮廓内”的比较次数。
编辑以添加基于Jim下面回答的解决方案 - 感谢Jim!
这是第一次迭代 - 它产生了很好的(10倍)改进。请参见下面的迭代2。与我的原始算法相比,这段代码快了>10倍,一旦轮廓集变得非常大。查看下面的图像,现在可以在几秒钟内排序(而不是之前的30多秒),并按顺序渲染。我认为还有改进的空间,例如,现在根据面积对原始列表进行了排序,那么每个新的候选对象都必须是树中的叶节点。难点在于确定要遍历哪些分支来测试现有的叶子节点 - 如果有许多分支/叶子,则检查顶部的分支可能仍然更快..这是需要考虑的一些内容!
public static iso_area sort_iso_areas(List<iso_area> areas, iso_area root)
{
if (areas.Count == 0)
return null;
areas.Sort(new iso_comparer_descending());
foreach (iso_area area in areas)
{
if (root.children.Count == 0)
root.children.Add(area);
else
{
bool found_child = false;
foreach (iso_area child in root.children)
{
// check if this iso_area is within the child
// if it is, follow the children down to find the insertion position
if (child.try_add_child(area))
{
found_child = true;
break;
}
}
if (!found_child)
root.children.Add(area);
}
}
return root;
}
// try and add the provided child to this area
// if it fits, try adding to a subsequent child
// keep trying until failure - then add to the previous child in which it fitted
bool try_add_child(iso_area area)
{
if (within(area))
{
// do a recursive search through all children
foreach (iso_area child in children)
{
if (child.try_add_child(area))
return true;
}
area.move_to(this);
return true;
}
else
return false;
}
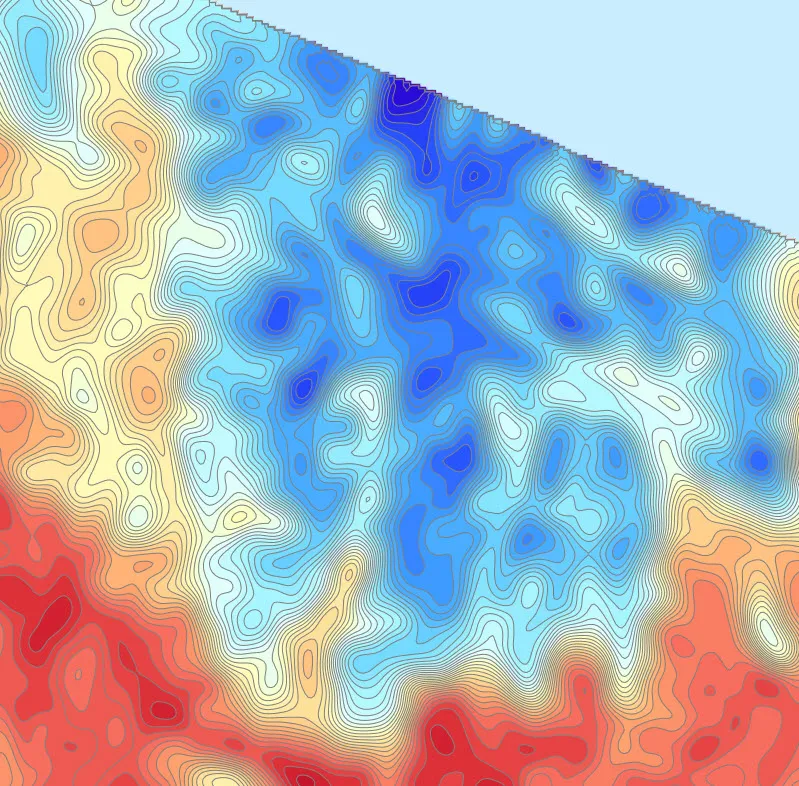
迭代二 - 仅与现有叶子进行比较
继续我之前的想法,即新轮廓只能适合于现有叶子中,我认为实际上这将更快,因为在除了目标叶子以外的所有叶子中,多边形与多边形的测试会在第一次边界检查时失败。第一个解决方案涉及遍历分支以找到目标,其中每个定义上都通过边界检查的多边形都将通过完整的多边形内部测试,直至没有发现更多叶子。
根据Jim的评论和重新审查代码 - 不幸的是,第二个解决方案并没有起作用。我想知道在查看分支之前是否仍然有必要查看树中的低元素,因为多边形内部测试应该很快失败,并且您知道如果找到接受候选者的叶子,则不需要再检查其他多边形。
迭代二重新审视
虽然情况并非轮廓只能适合于叶子,但几乎总是如此 - 而且它们通常适合于轮廓的有序列表中的最近前身。这个最终更新的代码是最快的,完全放弃了树遍历。它只是向后遍历最近的较大多边形并尝试每个 - 来自其他分支的多边形可能会在边界检查时失败多边形内部测试,而找到围绕候选多边形的第一个多边形必须是直接父级,由于列表的先前排序。该代码将排序带入毫秒范围内,并且比树遍历快约5倍(对多边形内部测试进行了显着的速度改进,其占其余速度提升的原因)。现在从区域的排序列表中取出根。请注意,我现在在列表中提供一个包含所有轮廓(所有轮廓的边界框)的根。
感谢您的帮助 - 特别是Jim - 帮助我思考这个问题。关键实际上是将轮廓排序为列表,其中保证不会有轮廓是列表中后面轮廓的子级。
public static iso_area sort_iso_areas(List<iso_area> areas)
{
if (areas.Count == 0)
return null;
areas.Sort(new iso_comparer_descending());
for (int i = 0; i < areas.Count; ++i)
{
for (int j = i - 1; j >= 0; --j)
{
if (areas[j].try_add_child(areas[i]))
break;
}
}
return areas[0];
}
我的原始尝试:133 s 第一次迭代(遍历分支查找叶节点):9s 第二次迭代(按升序大小向后遍历轮廓):25毫秒(同时还有其他点在多边形内的改进)。